深入解析Kafka源码:生产与消费模型详解
本资源深入剖析了Apache Kafka的核心原理和源码,特别关注于生产者(Producer)和消费者的实现机制。首先,我们从Kafka生产者源码入手,理解其如何与服务器交互,通过ProducerRequest和ProducerResponse发送消息,并确保数据的有效传递。生产者负责将消息发送到特定的分区(Partition),并可能涉及主题(Topic)的创建和管理。
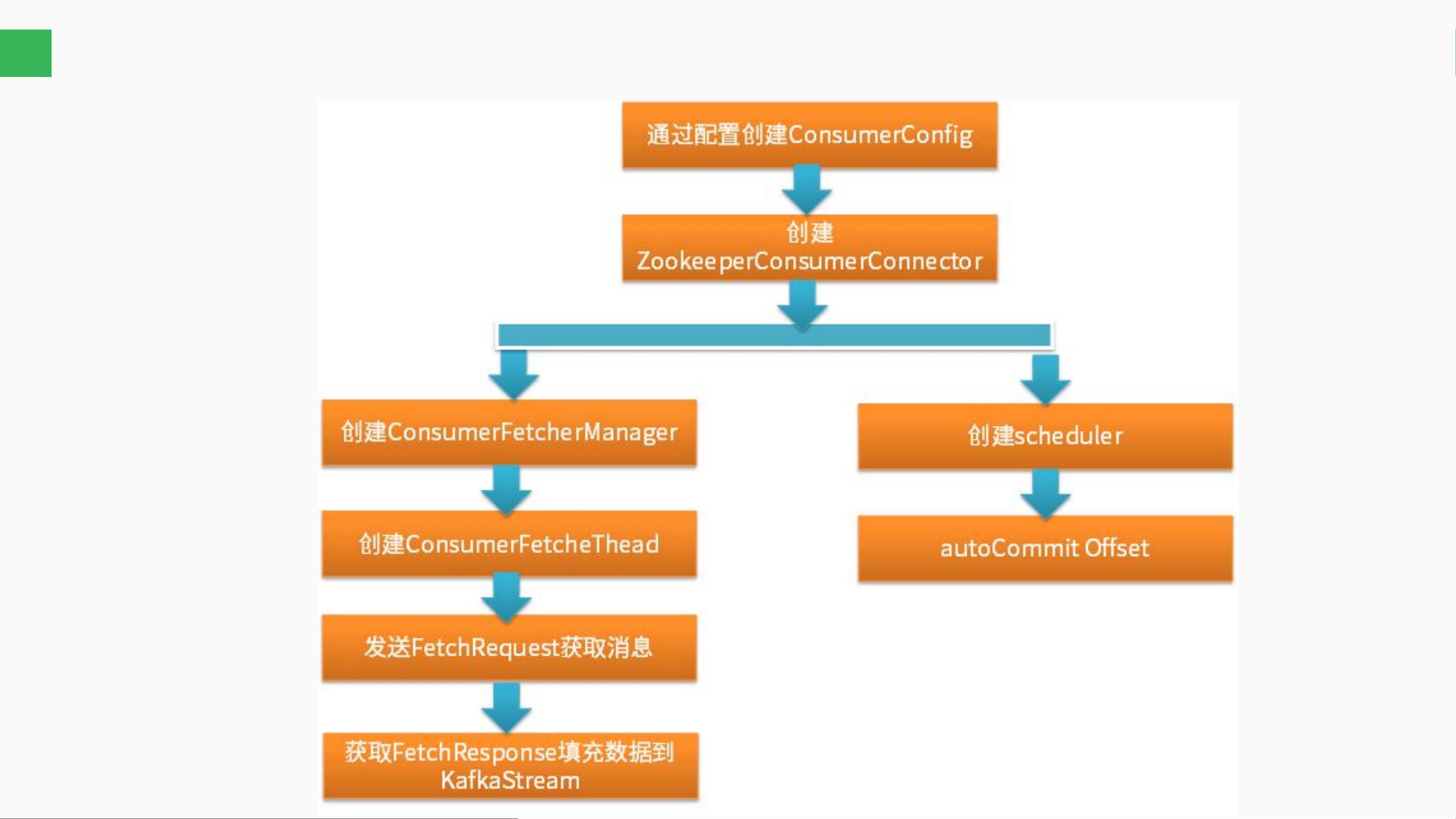
接着,消费者(Consumer)的源码是本课程的重要部分。课程分为两个主要的消费模式:分区消费模式和组消费模式。分区消费模式下,客户端主动与服务器交互,通过FetchRequest和FetchResponse获取消息,同时需自行处理offset管理和错误处理。客户端需要确保正确地指定topic、partition和offset,并负责提交offset以维护消费进度。
相比之下,组消费模式更为简化,客户端只需作为迭代器消费消息,服务器端负责错误处理、offset提交以及负载均衡。KafkaServerReactor设计模型在消费者源码中起着关键作用,它定义了服务器如何响应消费者的请求,包括MetadataRequest和MetadataResponse等。此外,Kafka的监控工具,如KafkaOffsetMonitor和KafkaManager,都是基于组消费模式来实现对消费进度的管理和监控。
在讲解过程中,还涉及到KafkaPartitionLeader选举机制,这是确保数据一致性的重要环节,当分区的领导者(Leader)发生变更时,服务器会重新组织分区的读写逻辑。整体而言,通过学习这些源码,读者可以全面掌握Kafka的消息生产和消费模型,以及服务器端的内部运作机制,这对于理解和优化Kafka系统有着至关重要的作用。无论是初学者还是高级开发者,都可以通过这个深入的源码分析来提升对Kafka技术的理解和实践能力。

Kafka 消费者源码介绍—组消费模式源码介绍
剩余38页未读,继续阅读
2018-05-24 上传
2018-06-26 上传
2018-03-14 上传
2019-11-06 上传
2021-06-15 上传
2018-04-09 上传
2019-01-23 上传

少林码僧
- 粉丝: 2041
- 资源: 19
 我的内容管理
展开
我的内容管理
展开







最新资源
- zlib-1.2.12压缩包解析与技术要点
- 微信小程序滑动选项卡源码模版发布
- Unity虚拟人物唇同步插件Oculus Lipsync介绍
- Nginx 1.18.0版本WinSW自动安装与管理指南
- Java Swing和JDBC实现的ATM系统源码解析
- 掌握Spark Streaming与Maven集成的分布式大数据处理
- 深入学习推荐系统:教程、案例与项目实践
- Web开发者必备的取色工具软件介绍
- C语言实现李春葆数据结构实验程序
- 超市管理系统开发:asp+SQL Server 2005实战
- Redis伪集群搭建教程与实践
- 掌握网络活动细节:Wireshark v3.6.3网络嗅探工具详解
- 全面掌握美赛:建模、分析与编程实现教程
- Java图书馆系统完整项目源码及SQL文件解析
- PCtoLCD2002软件:高效图片和字符取模转换
- Java开发的体育赛事在线购票系统源码分析
