网易高级专家解析:Impala在大数据优化中的实战与管理
版权申诉
150 浏览量
更新于2024-07-07
收藏 4.63MB PDF 举报
Impala是针对大数据处理的一种查询引擎,由温正湖这位网易杭研的高级数据库技术专家介绍,它在网易大数据环境中得到了广泛应用。Impala的主要定位是为大规模数据集提供快速的查询性能,尤其适合处理百万到百亿级别的数据,区别于传统的OLTP(在线事务处理)数据库和实时分析型数仓,以及离线数仓如Hive和Spark SQL。
Impala的优势主要体现在以下几个方面:
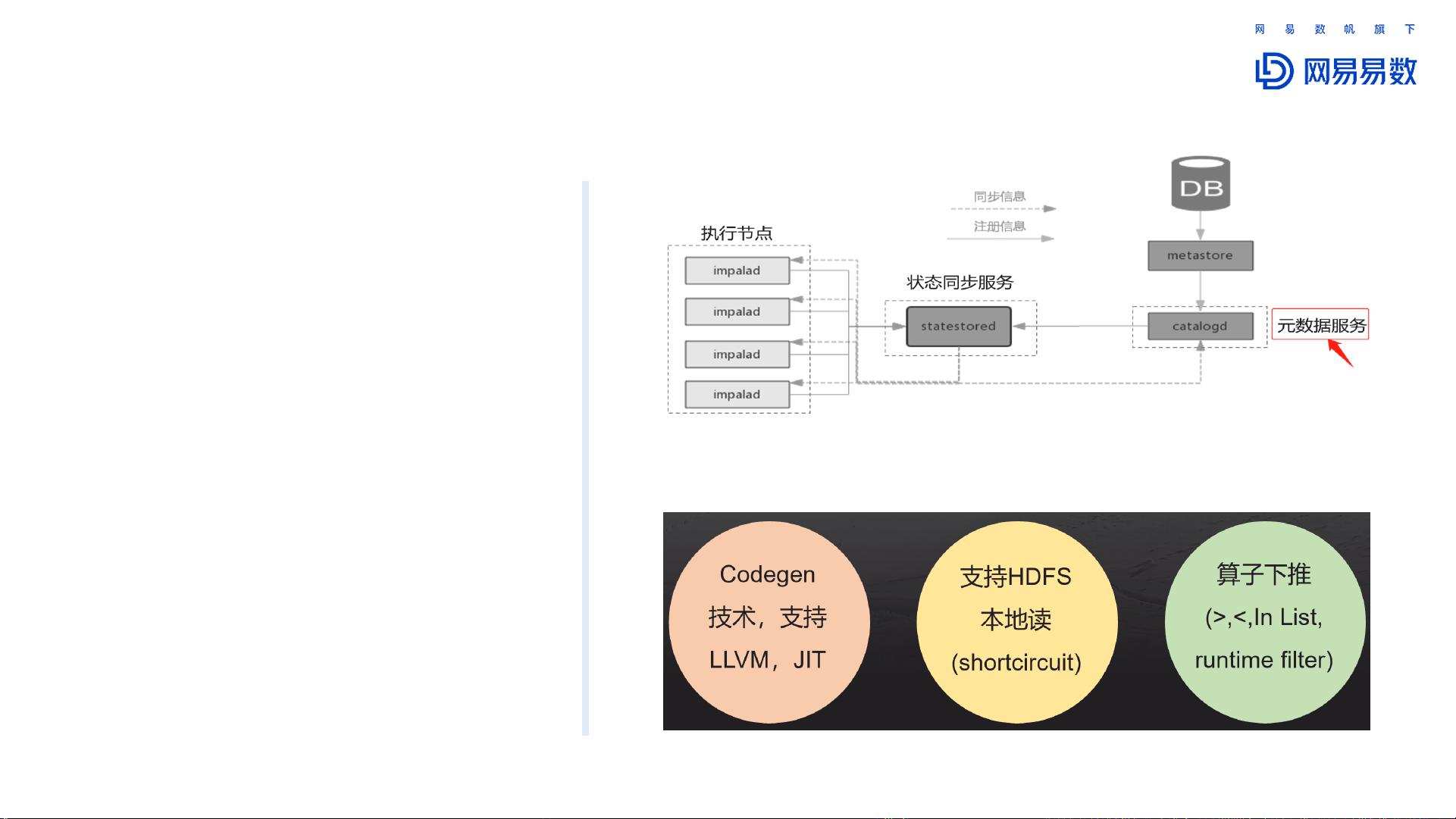
1. **去中心化的MPP架构**:与传统的集中式架构相比,Impala采用分布式并行处理模式,避免了单点故障,增强了系统的可靠性和性能。
2. **优秀的查询性能**:得益于成本优化器(CBO)的支持,Impala能够自动选择最优执行计划,同时通过Catalog缓存提高数据访问效率。
3. **友好的用户界面**:Impala提供了一个易于使用的Web UI,用户可以方便地查看节点内存消耗、查询分析、SQL诊断以及异常查询的终止情况。
4. **兼容性和扩展性**:Impala与Hive元数据完全兼容,且作为Apache顶级项目,拥有活跃的社区支持,支持多种数据格式,如Parquet和Orc,并能与Kudu集成以构建实时数仓。
5. **增强和优化**:针对实际应用的需求,Impala不断进行改进,包括引入管理服务器来持久化存储集群信息,提升服务的高可用性,以及支持更多的存储后端,提高了整体的性能和管理效率。
在使用实践中,Impala常被用作通用查询引擎,特别是在需要快速响应的数据分析场景,比如自助分析和BI报表制作。然而,尽管社区版的Impala管理服务器提供了丰富的信息,但仍存在非持久化问题,即重启后可能会丢失部分数据。为解决这一问题,管理服务器采用了MySQL存储集群配置和统计信息,确保了数据的持久性和完整性。
Impala在大数据处理中扮演着关键角色,通过其高性能的MPP架构和持续优化的功能,为企业提供了高效、可靠的分析能力。
Impala优势
➢ MPP架构,去中心化
➢ 优秀的查询性能
✓ CBO:支持基于代价执行优化;
✓ Catalog缓存:缓存库和表信息,HDFS数据块,统计信息等
剩余33页未读,继续阅读
2022-03-18 上传
2022-03-18 上传
2022-10-26 上传
2019-08-06 上传
2021-10-14 上传
2022-03-18 上传


智慧化智能化数字化方案
- 粉丝: 591
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- Aspose资源包:转PDF无水印学习工具
- Go语言控制台输入输出操作教程
- 红外遥控报警器原理及应用详解下载
- 控制卷筒纸侧面位置的先进装置技术解析
- 易语言加解密例程源码详解与实践
- SpringMVC客户管理系统:Hibernate与Bootstrap集成实践
- 深入理解JavaScript Set与WeakSet的使用
- 深入解析接收存储及发送装置的广播技术方法
- zyString模块1.0源码公开-易语言编程利器
- Android记分板UI设计:SimpleScoreboard的简洁与高效
- 量子网格列设置存储组件:开源解决方案
- 全面技术源码合集:CcVita Php Check v1.1
- 中军创易语言抢购软件:付款功能解析
- Python手动实现图像滤波教程
- MATLAB源代码实现基于DFT的量子传输分析
- 开源程序Hukoch.exe:简化食谱管理与导入功能
