Ubuntu 16.04下VirtualBox环境中Hadoop集群安装详解
版权申诉
160 浏览量
更新于2024-09-12
收藏 496KB PDF 举报
本篇文档是关于最新Hadoop集群安装教程,适用于2021年,主要讲解如何在Ubuntu 16.04环境下使用VirtualBox构建Hadoop分布式系统。以下是详细的步骤:
1. **安装VirtualBox**:作为集群的基础,首先需要安装VirtualBox虚拟机软件,以便在宿主机上创建和管理虚拟机。
2. **安装Ubuntu 16.04**:
- **设置虚拟机配置**:创建一个新的虚拟机,分配2GB内存和至少20GB磁盘空间,网络设置选择网络地址转换(NAT)用于互联网连接,以及一个仅主机网络用于内部通信。
- **安装过程**:启动名为"master"的虚拟机,选择Ubuntu 16.04的安装镜像,设置管理员用户名和密码(这里均为"master")。
- **增强虚拟机功能**:为了方便主机与虚拟机间的交互,确保共享剪贴板和拖放功能已启用,并安装增强功能,然后重启虚拟机。
3. **创建bigdata目录**:
- 在宿主机的`/usr/local`目录下创建一个名为"bigdata"的文件夹,并设置权限,确保用户"master"对它有完全控制权。
4. **安装Java JDK 1.8**:
- 下载并解压JDK 1.8.0_261到`/usr/local/bigdata`目录。
- 配置环境变量:在`.bashrc`文件中添加JDK和JRE路径,然后执行`source ~/.bashrc`使更改生效。对于CentOS,需在`/etc/profile`中做同样操作。
5. **验证Java安装**:
- 通过运行`java-version`命令,确认Java安装正确且环境变量设置无误,显示版本信息表明安装配置成功。
6. **安装SSH服务**:
- 安装SSH(Secure Shell)服务,这是Hadoop中进行远程管理和通信的关键组件,允许用户在节点之间安全地传输数据和执行命令。
这份教程详细指导了在Ubuntu 16.04上搭建Hadoop集群的基本步骤,包括环境准备、系统安装、软件配置和验证,适合初学者和开发者学习和实践Hadoop分布式系统的部署。在实际操作过程中,可能还需要根据网络环境、集群规模等因素进行适当的调整。
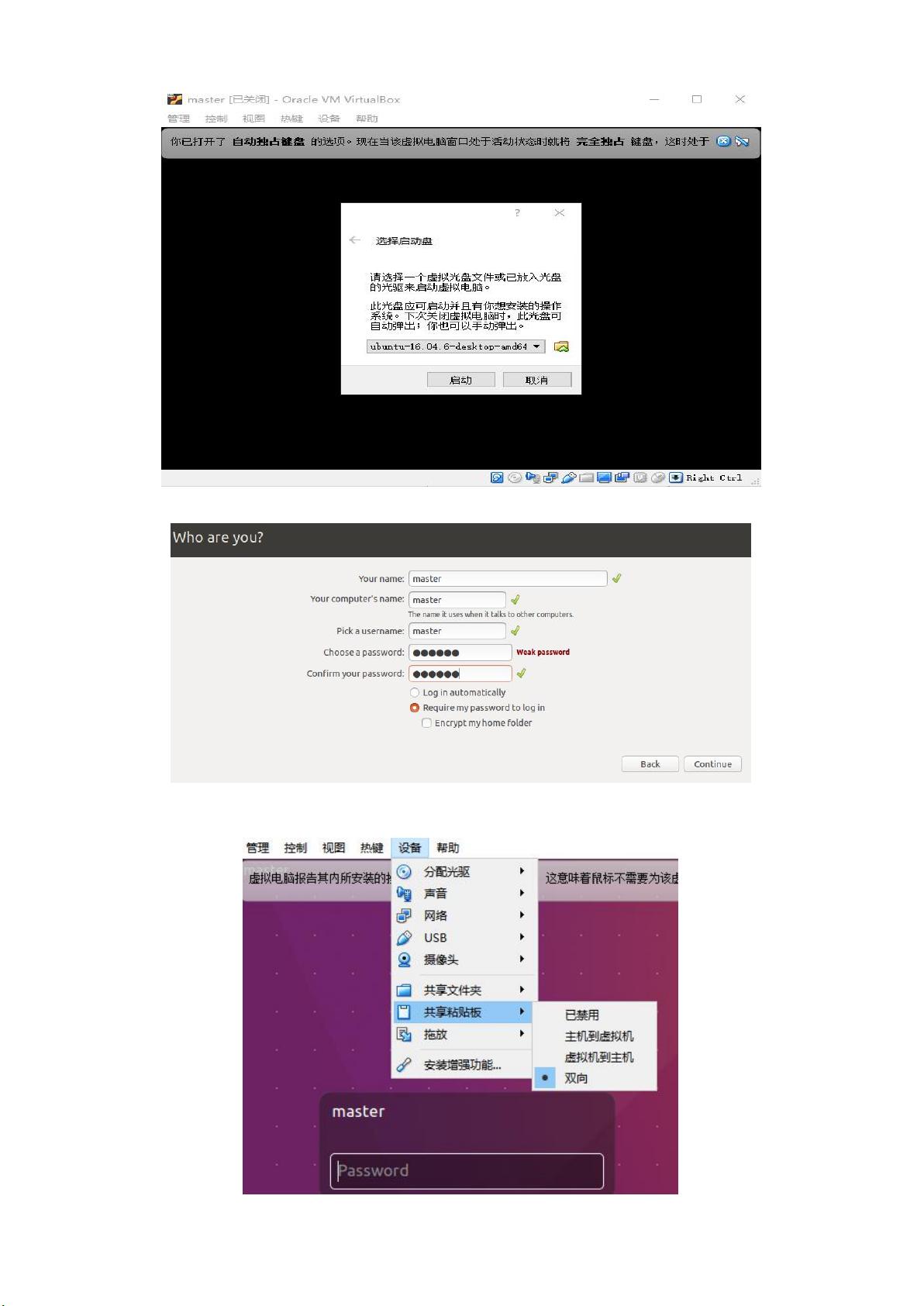
按照安装引导安装,设置用户名:
master,
密码
master
为了虚拟机与主机交互,安装完成后,在虚拟机菜单“设备”栏设置共享剪切板和拖放都为双向,并
安装增强功能,安装完成重启虚拟机(重启才能生效)
剩余11页未读,继续阅读
141 浏览量
248 浏览量
197 浏览量
2021-10-12 上传
156 浏览量
133 浏览量
2021-12-12 上传

安全方案
- 粉丝: 2707
- 资源: 3972
 我的内容管理
展开
我的内容管理
展开







最新资源
- JVM指令查询手册.pdf
- 闪亮鹦鹉:个人笔记
- vivmost:这是vivmost的GitHub个人资料存储库
- ebook-chat-app-spring-websocket-cassandra-redis-rabbitmq:Pro Java群集和可伸缩性:使用Spring,Cassandra,Redis,WebSocket和RabbitMQ构建实时应用程序
- 火车时刻表
- roman-numerals
- RJ11接口-EMC设计与技术资料-综合文档
- 云熙天工优化下料.rar
- 获取网页表单数据并显示
- 阿里云安全恶意程序检测-数据集
- 真棒机器学习jupyter-notes-for-colab:Jupyter Notebook格式的机器学习和深度学习教程的精选清单,准备在Google合作实验室中运行
- 欧美车迷俱乐部模板
- 基于SIR模型的疫情预测
- mtk_API.rar_MTK_Others_
- Java自定义函数式接口idea源码
- blogs:用于出版
