"数据仓库与数据挖掘第9章:分类与预测方法综述"
版权申诉
184 浏览量
更新于2024-02-21
收藏 766KB PPTX 举报
Data warehouse and data mining are concepts that play a crucial role in the world of data analysis and business intelligence. In chapter 9 of the "Data Warehouse and Data Mining" presentation, various topics related to classification and prediction are discussed in detail.
Classification and prediction are fundamental concepts in data mining, where classification refers to predicting categorical class labels, while prediction involves forecasting numerical values. Some of the key issues regarding classification and prediction include accuracy, efficiency, interpretation, and scalability.
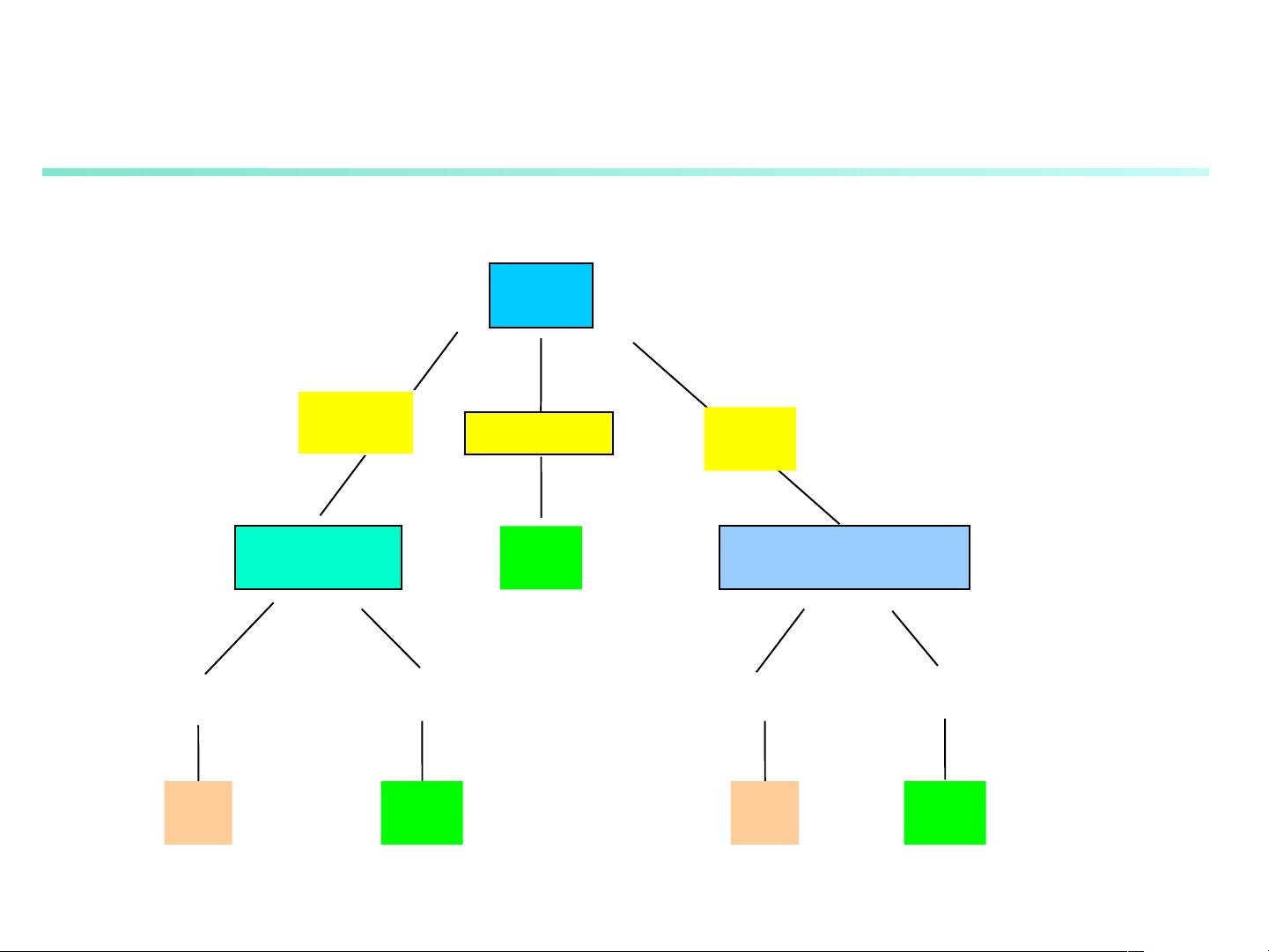
Decision tree induction is a popular method for classification, where a tree-like structure is used to model relationships between variables. Bayesian classification, neural networks, support vector machines, and association rule mining are other techniques commonly used for classification. Each method has its strengths and weaknesses, and the choice of technique depends on the specific requirements of the problem at hand.
Prediction accuracy is a critical factor in evaluating the performance of a classification model. Various measures such as precision, recall, and F1 score are used to assess the accuracy of the predictions made by a classifier. It is essential to balance between accuracy and interpretability when choosing a classification method, as a highly accurate model may be difficult to interpret and explain.
In summary, chapter 9 of the "Data Warehouse and Data Mining" presentation provides an in-depth discussion on classification and prediction in data mining. It covers various classification methods, issues related to accuracy and efficiency, and the importance of interpretability in model selection. By understanding these concepts, data analysts and business professionals can make informed decisions when building and evaluating classification models for their organizations.

,*
,
!
<"
!"
DE
*7
%&'%&'(%(( ))
*+
,-
age income student credit_rating buys_computer
<=30 high no fair no
<=30 high no excellent no
31…40 high no fair yes
>40 medium no fair yes
>40 low yes fair yes
>40 low yes excellent no
31…40 low yes excellent yes
<=30 medium no fair no
<=30 low yes fair yes
>40 medium yes fair yes
<=30 medium yes excellent yes
31…40 medium no excellent yes
31…40 high yes fair yes
>40 medium no excellent no

剩余62页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-10-08 上传
2021-10-12 上传
2021-10-11 上传
2021-10-11 上传
2021-09-21 上传
2022-06-09 上传

文档爱好者
- 粉丝: 8
- 资源: 29万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- WordPress作为新闻管理面板的实现指南
- NPC_Generator:使用Ruby打造的游戏角色生成器
- MATLAB实现变邻域搜索算法源码解析
- 探索C++并行编程:使用INTEL TBB的项目实践
- 玫枫跟打器:网页版五笔打字工具,提升macOS打字效率
- 萨尔塔·阿萨尔·希塔斯:SATINDER项目解析
- 掌握变邻域搜索算法:MATLAB代码实践
- saaraansh: 简化法律文档,打破语言障碍的智能应用
- 探索牛角交友盲盒系统:PHP开源交友平台的新选择
- 探索Nullfactory-SSRSExtensions: 强化SQL Server报告服务
- Lotide:一套JavaScript实用工具库的深度解析
- 利用Aurelia 2脚手架搭建新项目的快速指南
- 变邻域搜索算法Matlab实现教程
- 实战指南:构建高效ES+Redis+MySQL架构解决方案
- GitHub Pages入门模板快速启动指南
- NeonClock遗产版:包名更迭与应用更新
