癌症基因研究:信息基因挖掘与分类方法
需积分: 0 68 浏览量
更新于2024-07-01
收藏 605KB PDF 举报
随着生物分子学的飞速发展,癌症与基因之间的关联性已经成为科学研究的热点。本文以"10286037_A题1"为题,深入探讨了癌症基因表达谱中的关键信息识别和分析方法。首先,通过对比不同样本的基因表达水平,作者提出了区分无关基因(非相关调控基因)与信息基因(可能参与癌症发生的关键基因)的概念,这在生物信息学中至关重要,因为筛选出这些信息基因有助于我们理解癌症的发生机制。
在方法论上,文章应用了数学建模和数据分析技术,如支持向量机(SVM)和人工神经网络(ANN),来评估特征子集的分类性能。具体来说,第一部分采用巴氏距离模型和理想基因模型对基因表达谱进行降维,以剔除无关基因。这种方法通过量化基因间的相似度,有效地减少了数据维度,提高了后续分析的效率。
第二部分,作者引入了FSSM算法(可能是Feature Selection based on Spectral Methods的缩写),在信息基因空间中寻找具有高分类能力的特征子集。通过将样本分为训练集和测试集,FSSM的结果在SVM和ANN的验证下,成功识别出一个包含5个信息基因的特征子集,实现了95.79%的样本分类准确率,证明了该特征子集的有效性。
接着,文章关注了噪声处理在基因表达谱分析中的重要性。第三部分讨论了阈值滤波和主成分分析作为去噪模型,以及它们在构建高斯过程分类器中的作用。噪声管理对于防止过拟合和提升模型的泛化能力至关重要,确保了最终分类器的稳健性和准确性。
为了结合医学知识,第四部分提出了基于知识库的基因图谱分析模型KFS(Knowledge-based Genomics Analysis Model)。该模型不仅考虑了信息基因的已有知识,还对基因图谱进行了去噪、样本评价函数增益优化和无关基因剔除。通过知识驱动的KFSSM算法,作者获得了更精准的特征子集,并利用SVM和ANN进一步验证信息基因的组合,针对结肠癌数据处理,获得了94.52%的样本分类正确率。
本文的研究不仅揭示了癌症基因表达谱中的关键信息,还展示了如何结合数学建模、特征选择和噪声处理等方法,以提升癌症基因标志物的识别精度。这些成果为癌症早期诊断和个性化治疗提供了科学依据,对未来癌症研究和临床实践具有重要意义。
7
0cos,)(
0o,)(
1
2
1
2
ge
m
i
eigi
ge
m
i
eigi
ge
vv
scvv
D
(7)
(3)基因 g 与基因 e 的相似度为:
ge
ge
D
S
cos
(8)
从相似度的定义中,我们可以看出,基因 g 与理想基因 e 向量的欧拉距离不
变,夹角越小,余弦值的绝对值越大,相似度越大。基因 g 和 e 的夹角不变,欧
拉距离越小,相似度越大。相似度定义很好地量化了基因 g 与理想基因 e 之间的
相关性,相似度越高,说明基因 g 的分类能力越强。同样的,我们可以通过设置
适当的阈值θ,将基因表达谱中信息基因和无关基因区分开,达到降维的效果。
geN
geI
SS
SS
g
,
,
(9)
5.1.2.3 综合模型
本文在处理第一题时,综合利用了巴氏距离模型和理想基因模型,以巴氏距
离模型为主,但是由于基因表达谱中的噪声会影响巴氏距离模型选出来的信息基
因的效果,所以再以理想基因模型为辅,选取一些与理想基因相似度高的基因,
防止将一些信息基因剔除。
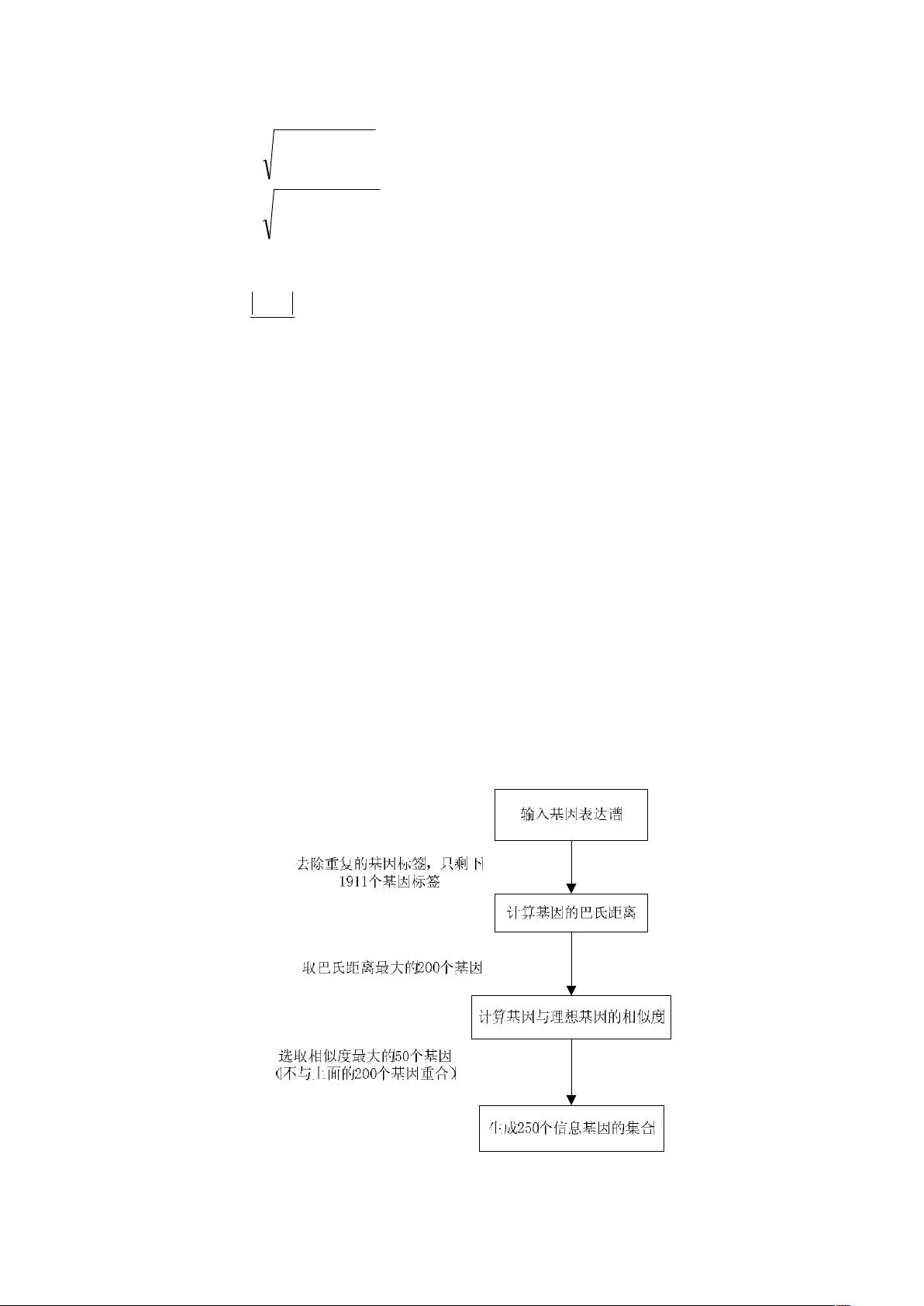
我们首先计算基因的巴氏距离前 200 的基因,然后再计算与理想基因的相似
度,选取相似度值前 50,并且不与前面重复的基因,组成大小为 250 的信息基
因集合。这个基因集合大约占题目所给基因总数的 20%,大幅压缩了冗余基因。
这 250 个基因集合作为第二问的特征子集的搜索空间。
图 5.1.1 综合模型的分类基因流程图
剩余35页未读,继续阅读
2022-08-08 上传
2020-07-23 上传
241 浏览量

神康不是狗
- 粉丝: 38
- 资源: 336
 我的内容管理
展开
我的内容管理
展开







最新资源
- Android圆角进度条控件的设计与应用
- mui框架实现带侧边栏的响应式布局
- Android仿知乎横线直线进度条实现教程
- SSM选课系统实现:Spring+SpringMVC+MyBatis源码剖析
- 使用JavaScript开发的流星待办事项应用
- Google Code Jam 2015竞赛回顾与Java编程实践
- Angular 2与NW.js集成:通过Webpack和Gulp构建环境详解
- OneDayTripPlanner:数字化城市旅游活动规划助手
- TinySTM 轻量级原子操作库的详细介绍与安装指南
- 模拟PHP序列化:JavaScript实现序列化与反序列化技术
- ***进销存系统全面功能介绍与开发指南
- 掌握Clojure命名空间的正确重新加载技巧
- 免费获取VMD模态分解Matlab源代码与案例数据
- BuglyEasyToUnity最新更新优化:简化Unity开发者接入流程
- Android学生俱乐部项目任务2解析与实践
- 掌握Elixir语言构建高效分布式网络爬虫
