Hadoop MapReduce实验:WordCount详解与实践
需积分: 0 17 浏览量
更新于2024-08-04
收藏 191KB DOCX 举报
"HADOOP实验一1"
这个实验主要介绍了如何在Hadoop环境中使用MapReduce进行简单的数据处理,特别是通过实现WordCount程序来理解MapReduce的工作原理。Hadoop是一个开源框架,它允许分布式存储和处理大规模数据集,而MapReduce是Hadoop中用于并行计算的核心编程模型。
实验首先要求掌握基本的命令行操作,包括编译和运行MapReduce程序。MapReduce程序通常由Java编写,所以开发者需要熟悉Java开发环境,如Eclipse。在实验过程中,需要将Hadoop的classpath信息添加到系统环境变量CLASSPATH中,这样可以确保Java编译器能找到Hadoop的相关库。
实验过程主要包括以下步骤:
1. 配置环境:在用户的.bashrc文件中添加Hadoop的classpath信息,以便于系统能够识别Hadoop的相关类库。
2. 编译Java源代码:使用javac命令编译MapReduce程序,例如WordCount.java。这个程序包含一个Mapper和Reducer类,分别负责数据的初步处理和聚合计算。
3. 打包class文件:将编译后的class文件打包成jar包,便于Hadoop集群执行。使用jar命令可以完成这个操作。
4. 创建输入目录:在HDFS上创建一个名为input1的目录,用于存放待处理的数据文件。
5. 上传数据:将本地的文本文件上传到HDFS的input1目录下,作为MapReduce程序的输入。
6. 运行MapReduce任务:使用Hadoop的`hadoop jar`命令运行打包好的jar文件,并指定输入和输出目录。
7. 检查结果:通过HDFS的命令或工具查看输出结果,例如使用Hadoop的fs -cat命令查看生成的统计结果文件。
在WordCount示例中,Mapper函数负责读取输入文件的每一行,以空格为分隔符进行分词,并去除单词中的标点符号。这里使用了`StringTokenizer`进行分词,`replaceAll("\\pP","")`用于移除所有标点符号。Mapper的输出是一系列键值对,键是单词,值是1,表示该单词出现一次。
Reducer函数则接收Mapper的输出,对相同键的所有值进行求和,从而得到每个单词的总数。最后,这些结果会被写入到HDFS的指定输出目录中。
实验还强调了在遇到问题时自主查找解决方案的能力,这是在实际工作中非常重要的技能。通过这个实验,参与者不仅学习了MapReduce的基本操作,还对Hadoop的生态系统有了更深入的理解。
HADOOP 实验一
一. 实验要求
1. 学会使用基本的命令行编译运行 mapreduce 程序。
2. 对 mapreduce 代码编写有基本的熟悉,对 mapreduce 执行过程有更深
层次的了解。
3. 在实验过程中学会自己查找解决问题的方法,培养处理独自处理问题
的能力。
二. 实验过程
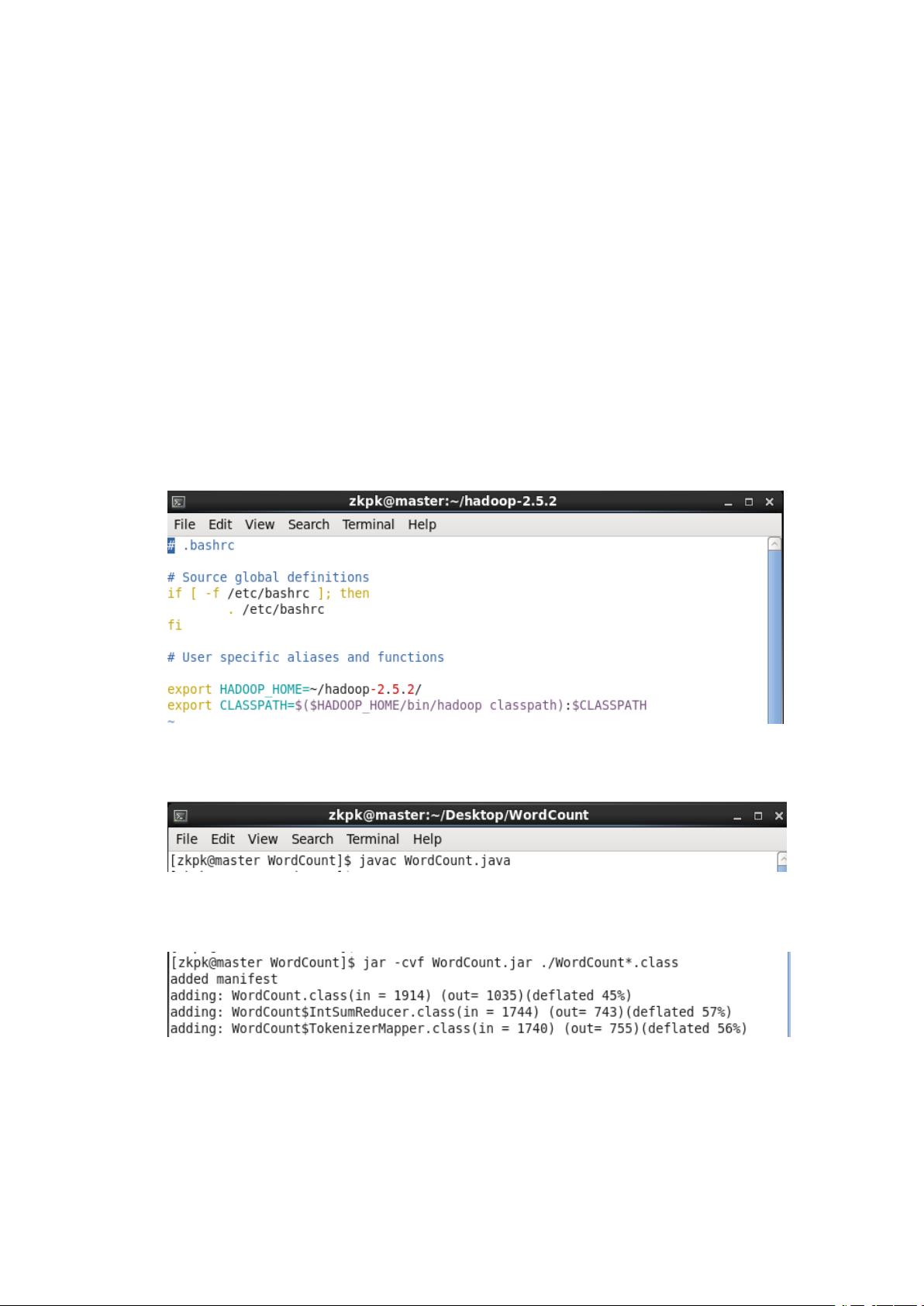
1. 将 我 们 将 Hadoop 的 classhpath 信 息 添 加 到 CLASSPATH 变 量 中 , 在
~/.bashrc 中添加最后两行命令。
图 1 配置 CLASSPATH 变量
2. 编译 java 文件
图 2 编译 java 文件
3. 将 class 文件打包成 jar 包
图 3 将 class 文件打包
下载后可阅读完整内容,剩余4页未读,立即下载
1597 浏览量
9257 浏览量
4215 浏览量
2024-09-26 上传
123 浏览量
168 浏览量
1108 浏览量
118 浏览量
2025-01-12 上传

daidaiyijiu
- 粉丝: 20
 我的内容管理
展开
我的内容管理
展开







最新资源
- USB设备属性查看器:C语言管理系统源码解析
- 轻量级权限管理系统的开发利器:renren-security源码解析
- Go-UNIS框架:Go语言字符串处理的公共架构解析
- 基于Javacli的货币汇率查询系统开源项目
- 响应式二手车交易网站模板源代码
- 复古室内装饰3D模型设计与应用
- XX乳业存货管理:提升效率的行政管理策略
- Rails与React结合开发单页应用程序教程
- 掌握Shell脚本管理点文件dotfiles的秘诀
- C++图像旋转放大及U盘小偷C语言源码分析
- 提升石油公司竞争力的信息化整合策略
- Go-HPACK库:高效实现HPACK压缩协议的Go语言库
- C语言实战项目:比较多个值大小的源码分析
- GitHub Pages:使用Markdown维护个人网站
- JavaScript实现背景与前景颜色动态切换技巧
- 深入学习JavaScript语法及示例实践
