Hadoop分布式文件系统HDFS详解:功能、读写与安全
需积分: 13 180 浏览量
更新于2024-09-04
收藏 6.01MB DOCX 举报
"本资源详细介绍了Hadoop分布式文件系统(HDFS)的核心概念、功能、读写机制、NameNode的工作方式、文件安全性、Web UI的使用以及Hadoop文件Shell的运用。"
Hadoop分布式文件系统(HDFS)是Apache Hadoop项目的关键组件,其设计灵感来源于Google的GFS(Google文件系统)。HDFS建立在本机文件系统之上,如ext3、ext4或xfs,旨在为大规模数据提供冗余存储,确保在使用标准硬件的情况下具备高可靠性、高性能和可伸缩性。
HDFS的主要功能包括高性能的数据处理,通过数据分布和冗余实现容错,以及简化管理和安全控制。其架构采用主从模式,NameNode作为主节点负责元数据管理,DataNodes作为从节点存储实际数据。HDFS特别适合处理大型文件,一次写入多次读取,支持大流式读取,保证在低延迟下实现高吞吐量。
文件在HDFS中被分割成固定大小的块,默认为128MB。这些块会被复制到集群中的多个节点,通常复制三次,以增强数据的可靠性和性能。如果配置了高可用性,HDFS会包含两个NameNode,一个为主,另一个为备用,以防止单点故障。
NameNode在内存中维护所有文件的元数据,包括文件位置、所有权、权限和块信息。元数据的变化首先存储在内存中,同时也会写入一个称为edit log的持久化日志。NameNode启动时,会从磁盘上的fsimage(元数据快照)加载初始元数据状态,然后合并edit log中的更新,形成新的fsimage。
为了监控和管理HDFS,用户可以通过NameNode的Web UI进行操作,查看文件系统状态、集群健康状况等信息。此外,Hadoop提供了文件Shell工具,允许用户执行各种文件操作,如创建、移动、删除文件和目录,以及执行文件系统检查。
Hadoop的安全性可以通过多种方式实现,例如通过Kerberos进行身份验证,或者利用HDFS的访问控制列表(ACLs)和POSIX样式的权限来限制对文件和目录的访问。
理解HDFS的工作原理对于有效地使用Hadoop生态系统至关重要,无论是进行大数据处理、数据分析还是开发相关应用。通过掌握HDFS的这些核心知识点,用户能够更好地管理和优化他们的Hadoop集群。
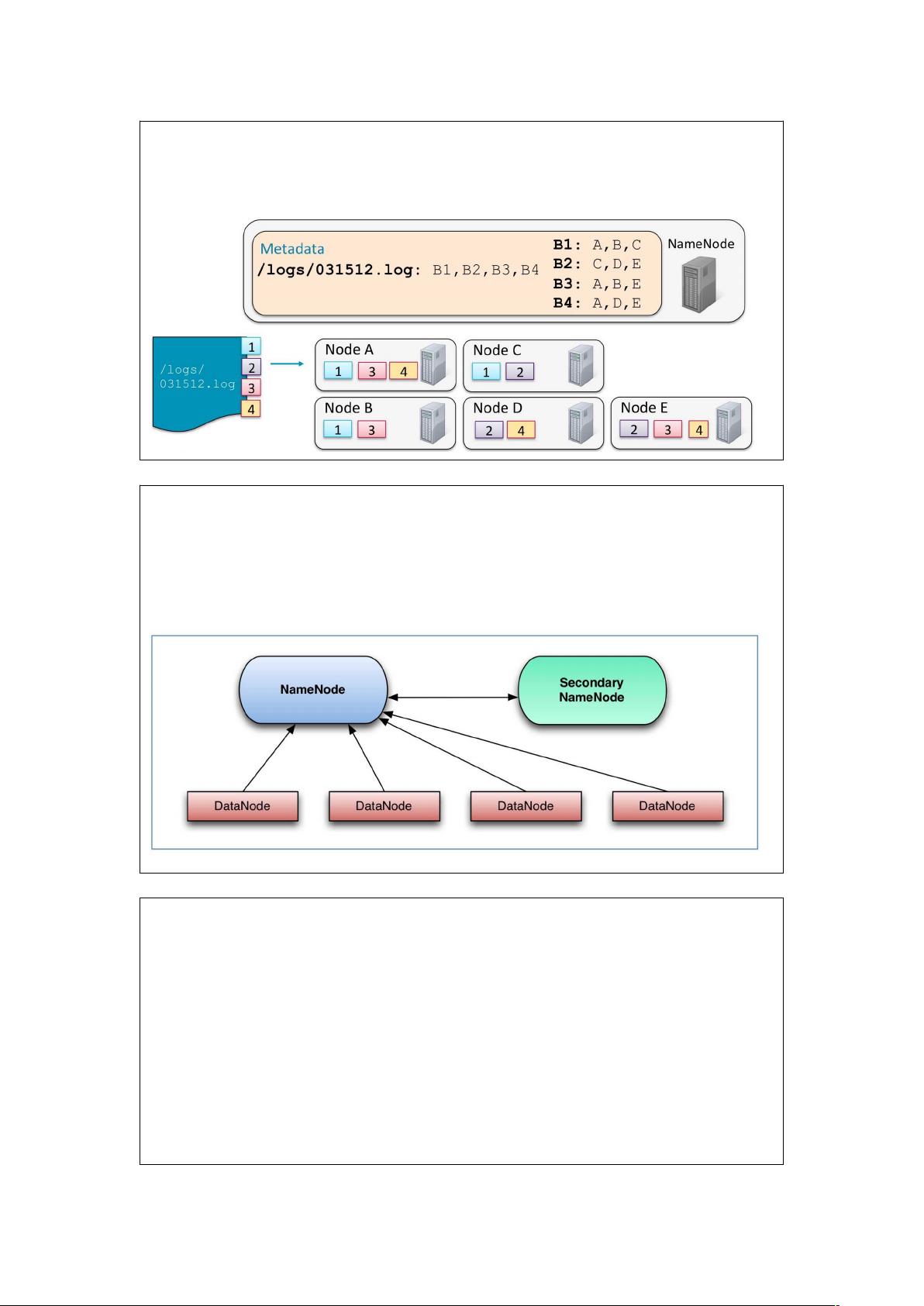
_ 基于复制因⼦(默认为三份)
■ 复制提高了可靠性和性能
_ 可靠性:数据可以容忍除一个副本之外的所有副本的丢失
_ 性能:数据本地化的机会更多
无高可用性的 HDFS
■ 您可以部署具有或不具有高可用性的 HDFS
■ 没有高可用性,有三个守护程序
_ NameNode(主节点)
_ SecondNameNode(主节点)
_ 数据节点(工作节点)
HDFS NameNode
■ NameNode 在 RAM 中保存所有元数据
_ 有关 HDFS 中文件的位置信息
_ 有关文件的所有权和权限信息
_ 各个块的名称
_ 块的位置
■ 元数据存储在磁盘上,并在 NameNode 守护程序启动时读取
_ 文件名是 fsimage
_ 注意:块位置不存储在 fsimage 中
■ 元数据的更改存储在 RAM 中
_ 更改也写入 edits 日志
剩余12页未读,继续阅读
2022-01-12 上传
120 浏览量
2022-05-17 上传
881 浏览量
230 浏览量
2022-06-21 上传
2022-07-14 上传
142 浏览量

尕聪明
- 粉丝: 113
- 资源: 111
 我的内容管理
展开
我的内容管理
展开







