Ubuntu 16.04下Hadoop全配置教程:从单机到集群
需积分: 11 97 浏览量
更新于2024-07-16
收藏 616KB DOCX 举报
本文档是关于在Ubuntu 16.04 LTS 64位操作系统环境下安装Hadoop 2.6.4的详细指南,特别适合大数据技术的学习者作为环境准备。文档覆盖了三种安装模式:单机模式、伪分布模式和完全分布式集群模式,其中完全集群模式至少需要三台服务器(Hadoop102、Hadoop103、Hadoop104)。
首先,对于系统环境的要求,指定了使用的是Ubuntu 16.04 LUbuntu操作系统,以及Java Development Kit (JDK) 1.8.0_161。部署时需要使用用户名hadoop,但读者应自行替换为实际用户名。
文档的核心部分详述了安装和配置步骤:
1. **系统环境设置**:
- 安装前确保修改root密码,使用`sudopasswd root`命令。
- 安装并配置SSH服务至关重要,通过`sudo apt-get install openssh-server`进行安装,并通过`ssh localhost`验证连接。还需允许root用户SSH登录,修改`/etc/ssh/sshd_config`中的`PermitRootLogin`配置。
2. **静态IP地址和DNS配置**:
- 配置静态IP,先禁用Network-manager服务,然后编辑`/etc/network/interfaces`,指定IP地址、子网掩码、网关和DNS服务器。确保在操作前了解当前的IP地址和DNS信息。
3. **Hadoop安装与配置**:
- 单机模式适用于学习和小规模测试,而伪分布模式则模拟Hadoop集群的部分功能,但不完全分布式。完全分布式集群至少需要三个节点,每个节点都有完整的Hadoop服务。
- 在完全集群中,安装Hadoop后,还需要配置HDFS(分布式文件系统)和YARN(资源管理和调度器)等组件,以及设置适当的网络参数,以实现节点间的通信。
本文档提供了详细的指导,有助于读者理解并搭建一个Hadoop环境,无论是在学习阶段还是进行小型项目开发时,都是实用的参考资源。
4
QST
青软实训 - 推动 教育 与产业的无缝衔接
重启网络服务:sudo /etc/init.d/networking restart
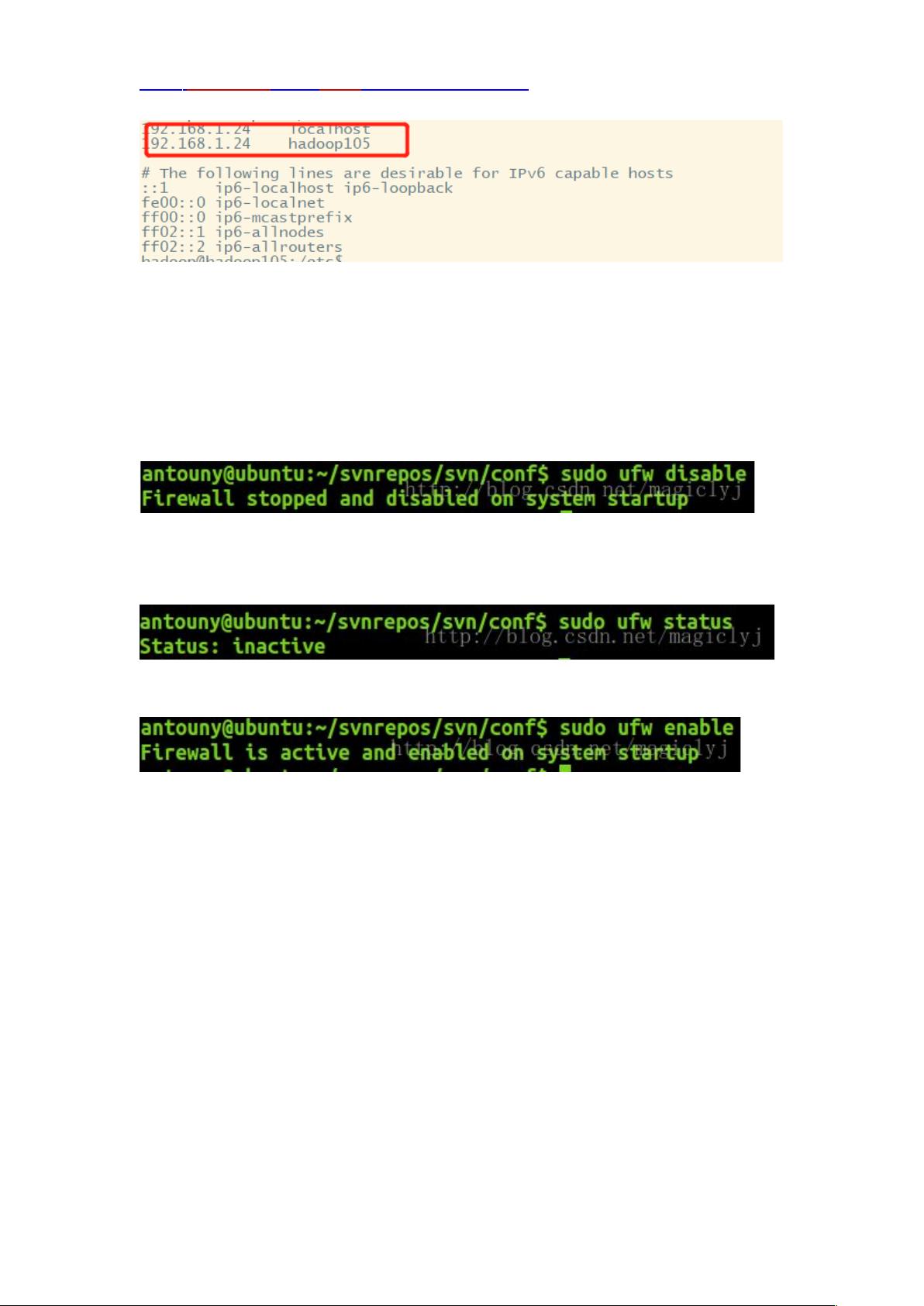
2.5 关闭防火墙
1、关闭防火墙
#sudo ufw disable
关闭了防火墙,并取消了开机自启动。
2、查看防火墙状态:
#sudo ufw status
3、开启防火墙:
#sudo ufw enable
2.6 VI 编辑器换行和退格键问题(可选)
1. sudo vi /etc/vim/vimrc."ny
2. vim:set <=vim:前面的iiset compa"ble 修改为iset nocompa"ble 解决方向键问题
再在下面加上iset backspace=2 修改退格键问题
2.7 配置 ssh 无密码登录(完全集群模式)【重要】
需要配置下面两个 ssh 无密码登录:
1. Hadoop102->hadoop103,hadoop4,hadoop102 的 ssh 无 密 码 登 录 。 配 置 Root 用 户 和
haddop 用 户 。 Hadoop102 上 部 署 了 NameNode , 需 要 管 理
剩余17页未读,继续阅读
2022-10-13 上传
2013-01-10 上传
2022-06-21 上传
2022-11-14 上传
2022-11-26 上传
2022-10-15 上传
2021-11-27 上传
2021-10-05 上传
2021-10-07 上传









