TF-IDF算法在用户画像中标签权重的应用解析
用户画像之标签权重算法是大数据时代企业精准营销和个人化服务的重要工具。它通过对用户的社会属性、消费习惯、偏好特征等多维度数据进行收集和分析,构建用户的信息全貌,以便于企业更好地理解用户需求并提供个性化的体验。本文关注的是如何确定用户标签的权重,这对于用户画像的准确性和推荐系统的有效性至关重要。
首先,理解用户画像的基本概念,它是将用户的复杂信息简化为一系列标签,这些标签描述了用户的特定特征。例如,程序员小Z在电商平台上的行为数据会被转化为"大数据"、"程序员"、"购物"等标签,这些标签不仅包括用户id、标签名称,还包含了用户行为的频率、类型和时间。其中,标签权重的计算直接影响到用户属性的归类精度。
提到的TF-IDF(Term Frequency-Inverse Document Frequency)算法是常用的权重计算方法之一。TF(Term Frequency)衡量了一个词在文档中的出现频率,即标签在用户个人标签列表中的占比,反映了该标签与用户行为的相关性。IDF(Inverse Document Frequency)则考虑了标签在整个用户群体中的普遍程度,一个标签如果被大量用户使用,它的IDF值就会降低,表示其独特性较弱。结合这两个指标,可以计算出TF-IDF值,权重越高,说明该标签对于区分用户特征的重要性越大。
在用户1的例子中,如果A标签被赋予的TF值为5/8(5次出现在所有标签中),而A标签在整个用户群体中的IDF值较低,那么A标签对用户1的权重就较高。反之,如果B标签虽然也被使用,但IDF值较大,那么其权重可能相对较低。这种权重分配有助于电商平台根据用户的兴趣热点进行更精确的推荐,避免过度推荐大众化商品,提高用户满意度。
除了TF-IDF算法,还有其他权重计算方法,如基于机器学习的协同过滤、基于深度学习的神经网络等,它们可以根据历史数据动态调整标签权重,以适应用户的实时变化。这些方法都是为了提升用户画像的精细度和个性化程度,从而实现更有效的用户运营和商业决策。
总结起来,用户画像之标签权重算法是利用统计学和信息检索技术,对用户行为数据进行深入分析,赋予每个标签相应的权重,为个性化推荐和营销策略提供依据。掌握和优化这一算法,对于企业优化用户体验、提高转化率具有重要意义。
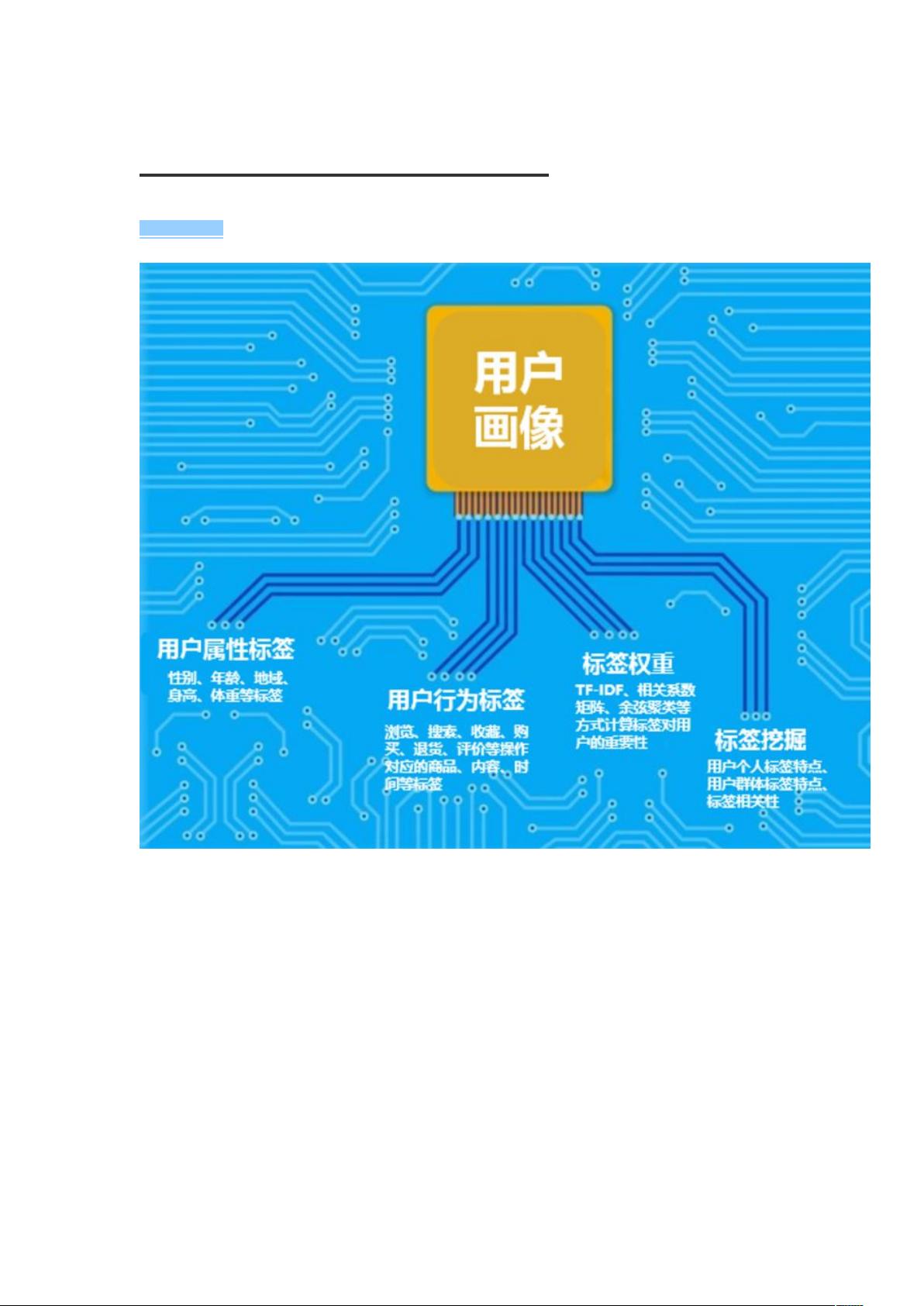
用户画像之标签权重算法
发表: 2017-07-28浏览: 289
算法 用户画像
感谢大家长期以来对专栏的关注,最近工作比较忙,好久没更新了。接下来的几篇文章想
和大家分享下关于用户画像的一些东西。今天我们先从用户画像的标签权重开始聊起吧。
用户画像:即用户信息标签化,通过收集用户社会属性、消费习惯、偏好特征等各个维度
数据,进而对用户或者产品特征属性的刻画,并对这些特征分析统计挖掘潜在价值信息,
从而抽象出一个用户的信息全貌,可看做是企业应用大数据的根基,是定向广告投放与个
性化推荐的前置条件。
先举个场景,程序员小 Z 在某电商平台上注册了账号,经过一段时间在该电商平台的 web
端/app 端进行浏览、所搜、收藏商品、下单购物等系列行为,该电商平台数据库已全程记
录该用户在平台上的行为,通过系列建模算法,给程序员小 Z 打上了符合其特征的标签
(如下图所示)。此后程序员小 Z 在该电商平台的相关推荐版块上总能发现自己想买的商
品,总能在下单前犹豫不决时收到优惠券的推送,总是在平台上越逛越喜欢....
下载后可阅读完整内容,剩余4页未读,立即下载
点击了解资源详情
2024-09-21 上传
811 浏览量
2022-08-08 上传
2024-05-26 上传
2021-03-23 上传

huangcb123456
- 粉丝: 1
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- 语音清浊音分类及浊音谐波提取算法_三阶累积量基于正弦语音模型的应用.pdf
- 有源电力滤波器中谐波提取的数字法实现.pdf
- 谐波提取理论的实践.pdf
- 基于谐波恢复方法的直升机声信号特征提取.pdf
- ASP.NET程序设计基础篇.pdf
- ASP.NET_XML深入编程技术.pdf
- 试采用FFT方法实现加速度_速度与位移的相互转换.pdf
- eclipse开发教程得到 的点点滴滴
- DWR中文文档.pdf
- 一种基于DNS和第七层交换的CDN实现方案
- keepalived the definitive guide权威指南
- 数据库原理课后答案(自考).doc
- 图书管理系统毕业论文
- 数字信号处理课程设计+matlab滤波器设计
- 基于提升方案小波和混沌映射的盲水印算法
- 基于快速提升小波变换与人眼视觉特性的数字水印算法
