
对对pandas处理处理json数据的方法详解数据的方法详解
今天小编就为大家分享一篇对pandas处理json数据的方法详解,具有很好的参考价值,希望对大家有所帮助。
一起跟随小编过来看看吧
今天展示一个利用pandas将json数据导入excel例子,主要利用的是pandas里的read_json函数将json数据转化为dataframe。
先拿出我要处理的先拿出我要处理的json字符串:字符串:
strtext='[{"ttery":"min","issue":"20130801-3391","code":"8,4,5,2,9","code1":"297734529","code2":null,"time":1013395466000},\
{"ttery":"min","issue":"20130801-3390","code":"7,8,2,1,2","code1":"298058212","code2":null,"time":1013395406000},\
{"ttery":"min","issue":"20130801-3389","code":"5,9,1,2,9","code1":"298329129","code2":null,"time":1013395346000},\
{"ttery":"min","issue":"20130801-3388","code":"3,8,7,3,3","code1":"298588733","code2":null,"time":1013395286000},\
{"ttery":"min","issue":"20130801-3387","code":"0,8,5,2,7","code1":"298818527","code2":null,"time":1013395226000}]'
pandas.read_json的语法如下:的语法如下:
pandas.read_json(path_or_buf=None, orient=None, typ='frame', dtype=True,
convert_axes=True, convert_dates=True, keep_default_dates=True,
numpy=False, precise_float=False, date_unit=None, encoding=None,
lines=False, chunksize=None, compression='infer')
第一参数就是json文件路径或者json格式的字符串。
第二参数orient是表明预期的json字符串格式。orient的设置有以下几个值:
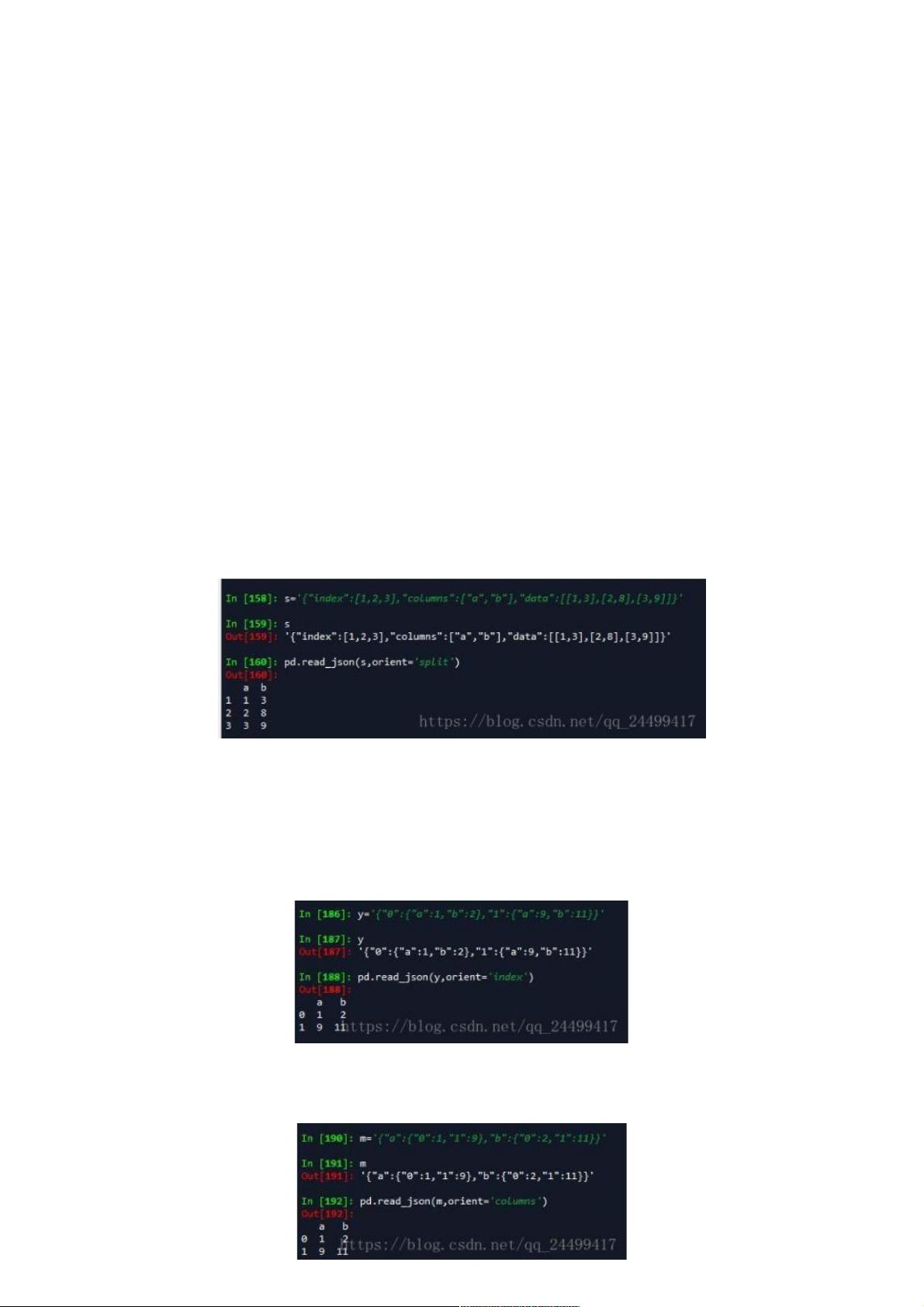
(1).'split' : dict like {index -> [index], columns -> [columns], data -> [values]}
这种就是有索引,有列字段,和数据矩阵构成的json格式。key名称只能是index,columns和data。
'records' : list like [{column -> value}, ... , {column -> value}]
这种就是成员为字典的列表。如我今天要处理的json数据示例所见。构成是列字段为键,值为键值,每一个字典成员就构成了
dataframe的一行数据。
'index' : dict like {index -> {column -> value}}
以索引为key,以列字段构成的字典为键值。如:
'columns' : dict like {column -> {index -> value}}
这种处理的就是以列为键,对应一个值字典的对象。这个字典对象以索引为键,以值为键值构成的json字符串。如下图所示:

weixin_38622611
- 粉丝: 6
- 资源: 945
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- 27页智慧街道信息化建设综合解决方案.pptx
- 计算机二级Ms-Office选择题汇总.doc
- 单链表的插入和删除实验报告 (2).docx
- 单链表的插入和删除实验报告.pdf
- 物联网智能终端项目设备管理方案.pdf
- 如何打造品牌的模式.doc
- 样式控制与页面布局.pdf
- 武汉理工Java实验报告(二).docx
- 2021线上新品消费趋势报告.pdf
- 第3章 Matlab中的矩阵及其运算.docx
- 基于Web的人力资源管理系统的必要性和可行性.doc
- 基于一阶倒立摆的matlab仿真实验.doc
- 速运公司物流管理模式研究教材
- 大数据与管理.pptx
- 单片机课程设计之步进电机.doc
- 大数据与数据挖掘.pptx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0