python运用运用sklearn实现实现KNN分类算法分类算法
KNN(K-Nearest-Neighbours Classiflication)分类算法,供大家参考,具体内容如下
最简单的分类算法,易于理解和实现
实现步骤:通过选取与该点距离最近的k个样本,在这k个样本中哪一个类别的数量多,就把k归为哪一类。
注意
该算法需要保存训练集的观察值,以此判定待分类数据属于哪一类
k需要进行自定义,一般选取k<30
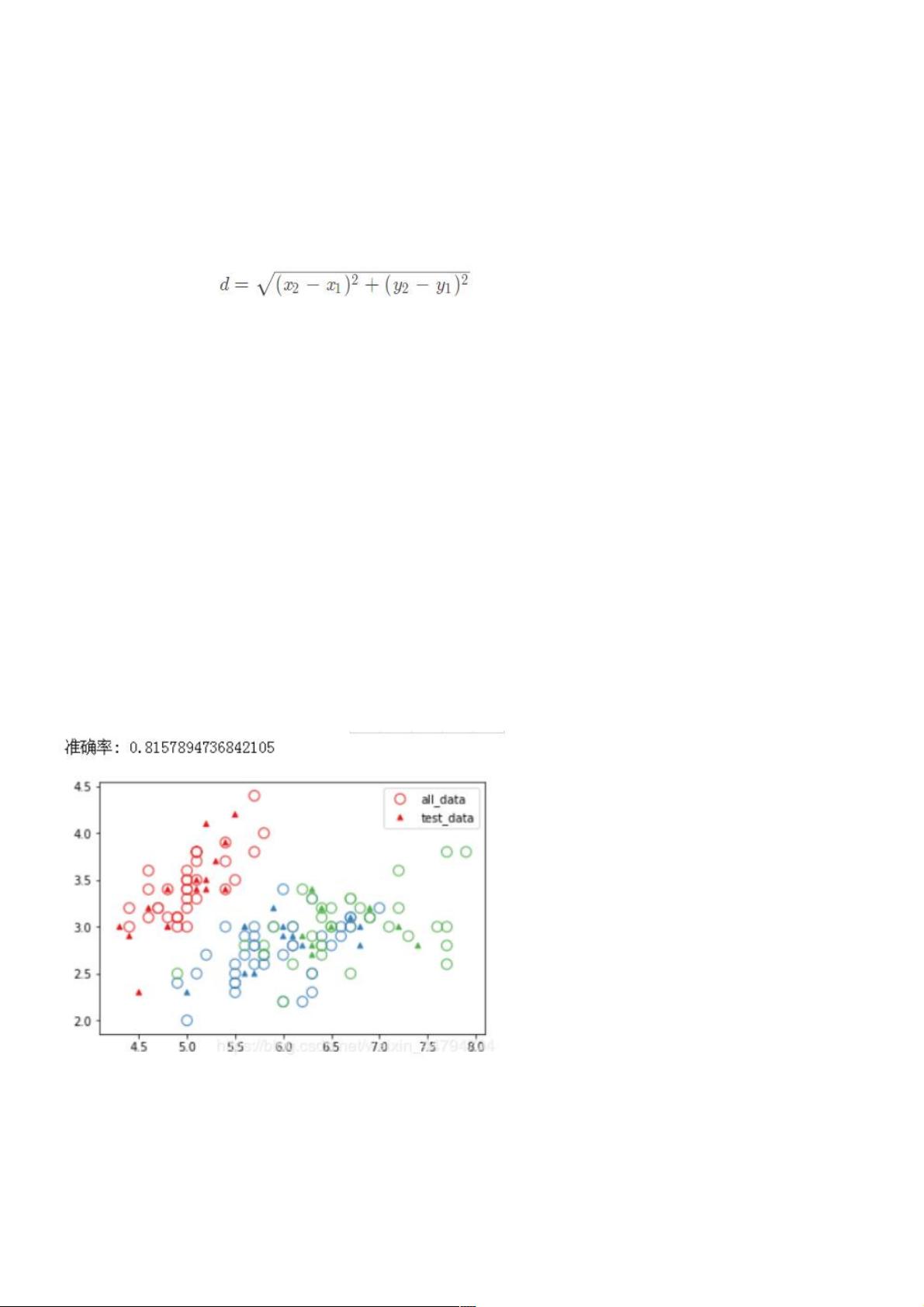
距离一般用欧氏距离,即
通过通过sklearn对数据使用对数据使用KNN算法进行分类算法进行分类
代码如下:
## 导入鸢尾花数据集
iris = datasets.load_iris()
data = iris.data[:, :2] target = iris.target
## 区分训练集和测试集,75%的训练集和25%的测试集
train_data, test_data = train_test_split(np.c_[data, target])
## 训练并预测,其中选取k=15
clf = neighbors.KNeighborsClassifier(15, 'distance')
clf.fit(train_data[:, :2], train_data[:, 2])
Z = clf.predict(test_data[:, :2])
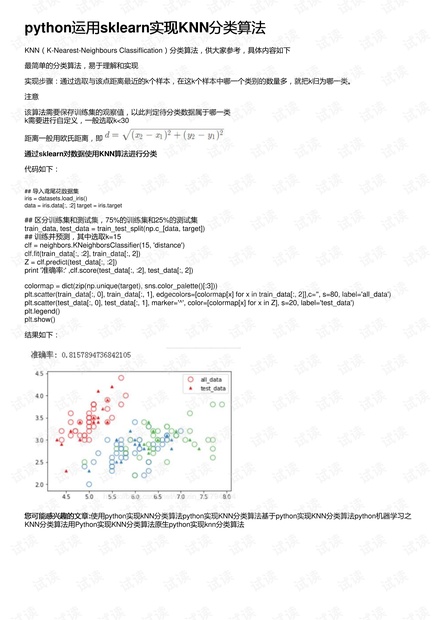
print '准确率:' ,clf.score(test_data[:, :2], test_data[:, 2])
colormap = dict(zip(np.unique(target), sns.color_palette()[:3]))
plt.scatter(train_data[:, 0], train_data[:, 1], edgecolors=[colormap[x] for x in train_data[:, 2]],c='', s=80, label='all_data')
plt.scatter(test_data[:, 0], test_data[:, 1], marker='^', color=[colormap[x] for x in Z], s=20, label='test_data')
plt.legend()
plt.show()
结果如下:
您可能感兴趣的文章您可能感兴趣的文章:使用python实现kNN分类算法python实现KNN分类算法基于python实现KNN分类算法python机器学习之
KNN分类算法用Python实现KNN分类算法原生python实现knn分类算法

weixin_38638647
- 粉丝: 7
- 资源: 993
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- 2023年中国辣条食品行业创新及消费需求洞察报告.pptx
- 2023年半导体行业20强品牌.pptx
- 2023年全球电力行业评论.pptx
- 2023年全球网络安全现状-劳动力资源和网络运营的全球发展新态势.pptx
- 毕业设计-基于单片机的液体密度检测系统设计.doc
- 家用清扫机器人设计.doc
- 基于VB+数据库SQL的教师信息管理系统设计与实现 计算机专业设计范文模板参考资料.pdf
- 官塘驿林场林防火(资源监管)“空天地人”四位一体监测系统方案.doc
- 基于专利语义表征的技术预见方法及其应用.docx
- 浅谈电子商务的现状及发展趋势学习总结.doc
- 基于单片机的智能仓库温湿度控制系统 (2).pdf
- 基于SSM框架知识产权管理系统 (2).pdf
- 9年终工作总结新年计划PPT模板.pptx
- Hytera海能达CH04L01 说明书.pdf
- 数据中心运维操作标准及流程.pdf
- 报告模板 -成本分析与报告培训之三.pptx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0