
基于基于Kubeflow的机器学习调度平台落地实战的机器学习调度平台落地实战
背景
随着机器学习和人工智能的迅猛发展,业界出现了许多开源的机器学习平台。由于机器学习与大数据天然的紧密结合,基于
Hadoop Yarn 的分布式任务调度仍是业界主流,但是随着容器化的发展,Docker + Kubernetes 的云原生组合,也展现出了很
强的生命力。
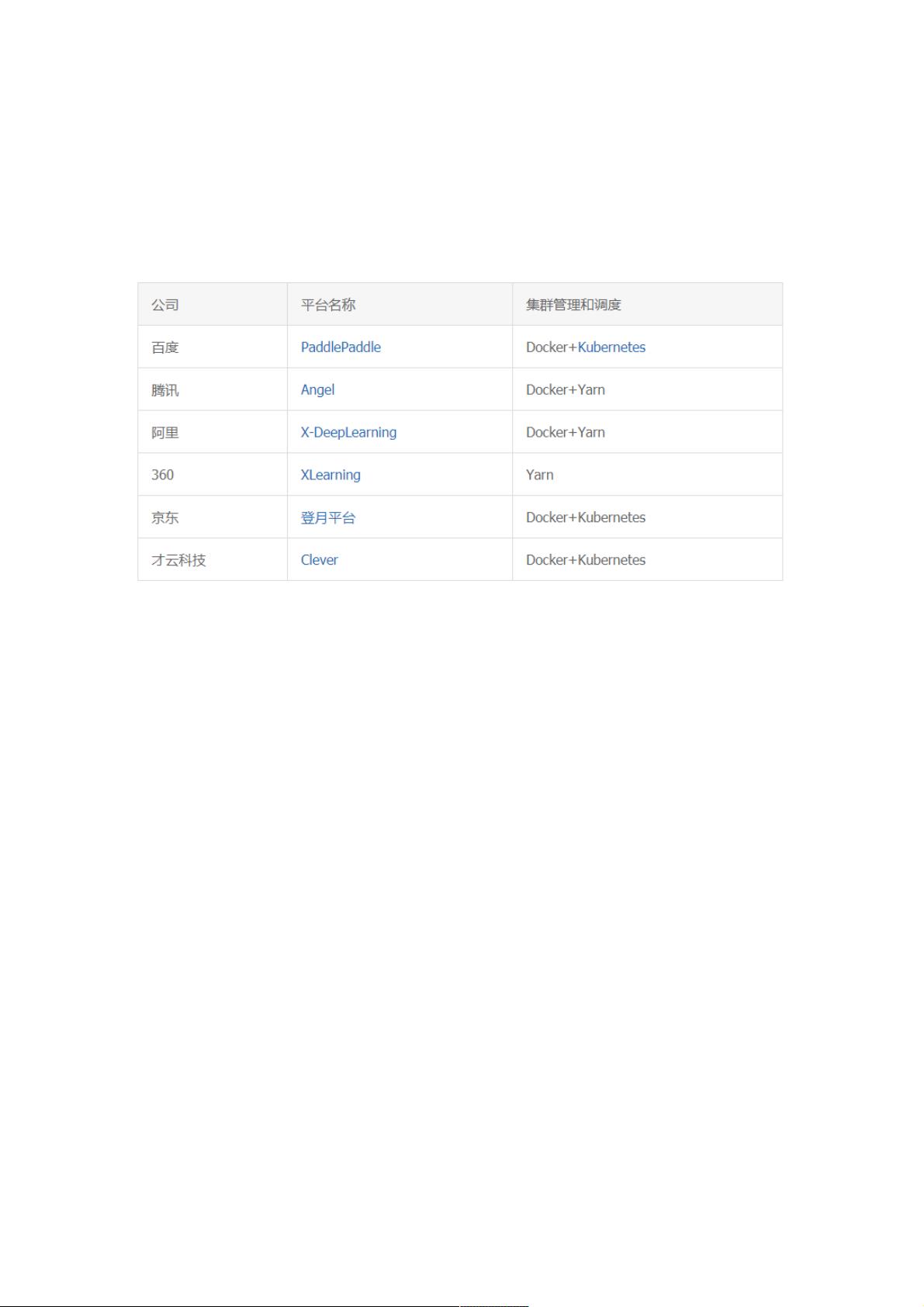
表 1. 互联网业界机器学习平台架构对比
痛点
在建设分布式训练平台的过程中,我们和机器学习的各个业务方,包括搜索推荐、图像算法、交易风控反作弊等,进行了深入
沟通,调研他们的痛点。从中我们发现,算法业务方往往专注于模型和调参,而工程领域是他们相对薄弱的一个环节。建设一
个强大的分布式平台,整合各个资源池,提供统一的机器学习框架,将能大大加快训练速度,提升效率,带来更多的可能性,
此外还有助于提升资源利用率。
痛点一:对算力的需求越来越强烈
算力代表了生产力。深度学习在多个领域的出色表现,给业务带来了更多的可能性,同时对算力提出了越来越高的要求。深度
学习模型参数的规模陡增,迭代的时间变的更长,从之前的小时级别,变成天级别,甚至月级别。以商品推荐为例,面对几亿
的参数,近百亿的样本数量,即使采用 GPU 机器,也需要长达一个星期的训练时间;而图像业务拥有更多的参数和更复杂的
模型,面对 TB 级的训练样本,单机场景下往往需要长达近一个月的训练时间。
再者,机器学习具有试错性非常强的特点,更快的训练速度可以带来更多的尝试,从而发掘更多的可能性。Tensorflow 从 0.8
版本开始支持分布式训练,至今为止,无论高阶还是低阶的 API,对分布式训练已经有了完善的支持。同时,Kubernetes 和
Hadoop 等具有完善的资源管理和调度功能,为 Tensorflow 分布式训练奠定资源层面的基础。
Tensorflow On Yarn 和 Tensorflow On Spark 是较早的解决方案,奇虎 360 的 Xlearning 也得到众人的青睐。而基于
Kubernetes 的 kubeflow 解决了 Yarn 的痛点,展现出旺盛的生命力。
上述方案无一例外的将各个部门分散的机器纳入到统一的资源池,并提供资源管理和调度功能,让基于 Excel 表的资源管理和
人肉调度成为过去,让用户更专注于算法模型,而非基础设施。在几十个 worker 下,无论是 CPU 还是 GPU 的分布式训练,
训练速度都能得到近乎线性的提升,将单机的训练时间从月级别缩短到一天以内,提升效率的同时也大大提升了资源利用率。
蘑菇街早期的业务方往往独立维护各自团队的 GPU 机器“小池子”,机器的资源分配和管理存在盲区,缺乏统一管理和调度。
GPU 的资源存在不均衡和资源利用率低下的问题。事实上,大数据团队之前已经将 CPU 类型的训练任务接入了 Xlearning,
尝到了分布式训练的甜头,但也发现一些问题:
公司目前的 Yarn 不支持 GPU 资源管理,虽然近期版本已支持该特性,但存在稳定性风险。
缺乏资源隔离和限制,同节点的任务容易出现资源冲突。
监控信息不完善。在发生资源抢占时,往往无法定位根本原因。
缺少弹性能力,目前资源池是静态的,如果能借助公有云的弹性能力,在业务高峰期提供更大的算力,将能更快的满足业务需
求。


剩余10页未读,继续阅读

weixin_38702726
- 粉丝: 10
- 资源: 930
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- zigbee-cluster-library-specification
- JSBSim Reference Manual
- c++校园超市商品信息管理系统课程设计说明书(含源代码) (2).pdf
- 建筑供配电系统相关课件.pptx
- 企业管理规章制度及管理模式.doc
- vb打开摄像头.doc
- 云计算-可信计算中认证协议改进方案.pdf
- [详细完整版]单片机编程4.ppt
- c语言常用算法.pdf
- c++经典程序代码大全.pdf
- 单片机数字时钟资料.doc
- 11项目管理前沿1.0.pptx
- 基于ssm的“魅力”繁峙宣传网站的设计与实现论文.doc
- 智慧交通综合解决方案.pptx
- 建筑防潮设计-PowerPointPresentati.pptx
- SPC统计过程控制程序.pptx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0