图形流水线优化策略与瓶颈分析
需积分: 10 28 浏览量
更新于2023-03-03
2
收藏 835KB PDF 举报
"该资源是一份45页的PDF文档,专注于优化图形流水线,由NVIDIA开发技术团队的Koji Ashida撰写。文档旨在帮助游戏开发者提高性能,创造新效果,优化图形引擎并处理bug。"
在计算机图形学中,图形流水线是一种高效处理图像数据的方法,它将复杂的渲染任务分解成多个阶段,每个阶段专门处理一部分工作。优化图形流水线是提升游戏和图形应用性能的关键,因为不同的应用程序和帧可能会有不同瓶颈,这些瓶颈直接影响数据吞吐率。Koji Ashida在文档中将深入探讨GPU的所有处理阶段以及CPU如何可能成为图形应用的瓶颈。
首先,GPU(图形处理器)是图形流水线的核心,负责大量并行计算,如顶点处理、纹理贴图、光照计算和像素渲染等。优化GPU的每个阶段都至关重要,因为任何一环的瓶颈都会限制整体性能。例如,顶点着色器可能在处理复杂几何形状时成为瓶颈,而纹理单元可能在处理大量纹理时受限。
CPU则负责运行应用程序,生成渲染指令,并通过驱动程序与GPU通信。CPU的性能瓶颈可能出现在数据传输速度、指令调度或线程管理等方面。如果CPU无法及时提供数据,GPU就会空闲,反之亦然,这称为“CPU-GPU同步问题”。
文档还会讨论驱动程序的角色,它是CPU和GPU之间的桥梁。优化的驱动可以提高数据传输效率,减少延迟,从而避免成为瓶颈。开发者需要理解如何利用最新的驱动特性来优化他们的应用。
此外,内存带宽也是一个关键因素。GPU和CPU访问的内存系统可能不同,如果数据交换频繁且效率低,就可能导致性能下降。理解内存层次结构,如L1、L2缓存和主内存,以及如何有效地利用它们,对于消除内存瓶颈至关重要。
最后,帧缓冲区的写入和显示也是流水线的一部分。优化这一过程涉及减少延迟,确保图像数据快速写入并显示出来,以达到更高的刷新率和流畅的游戏体验。
优化图形流水线涉及到多个层面,包括GPU硬件、CPU性能、驱动程序效率、内存管理和帧缓冲策略。通过深入理解这些环节并针对性地进行优化,开发者能够显著提升图形应用的性能和用户体验。这份文档将为读者提供宝贵的指导,帮助他们识别和解决图形流水线中的瓶颈问题。

8
帧缓冲带宽限制
Frame buffer bandwidth limited
改变所有渲染对象的颜色深度 (16-bit vs. 32-bit)
如果帧率改变了,应用程序就是帧缓冲带宽限制的
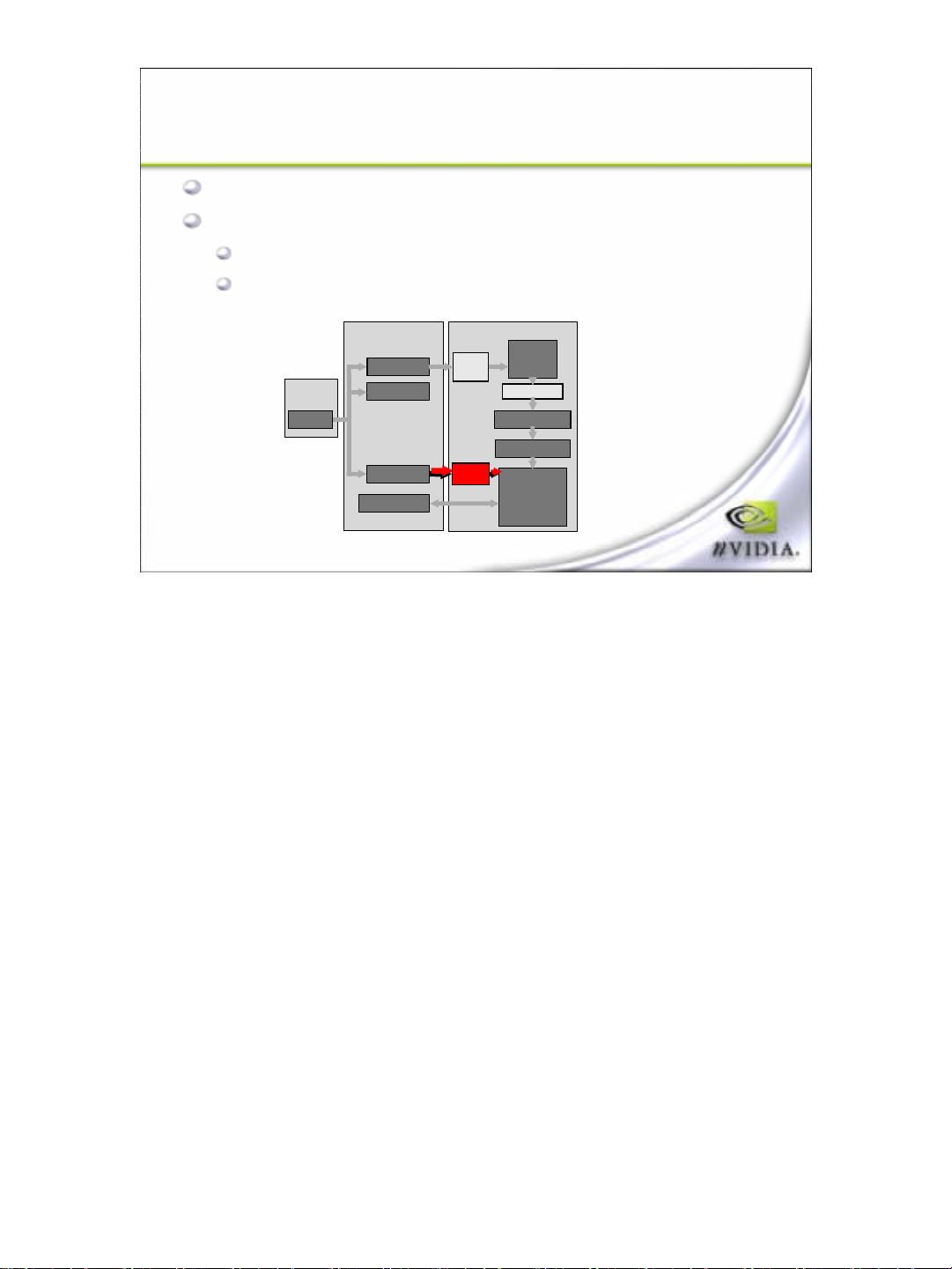
On-Chip Cache Memory
Video Memory
System
Memory
Rasterization
CPU
Vertex
Shading
(T&L)
Triangle Setup
Fragment
Shading
and
Raster
Operations
Textures
Frame Buffer
Geometry
Commands
pre-
TnL
cache
post-TnL cache
texture
cache
So let's start at the bottom of the pipeline. This is the part where the
graphics engine is trying to read from the frame or to frame. Simply to
access off-screen surfaces, not necessarily textures. So the easiest way to
identify if this is your bottleneck is to vary your bit depth. So if you're running
at 32 bits per pixel, run it at 16. If the frame rate varies then you're probably
frame buffer limited. This isn't necessarily the case all the time but it does
happen.
剩余44页未读,继续阅读
463 浏览量
626 浏览量
点击了解资源详情
463 浏览量
496 浏览量
2009-12-13 上传
129 浏览量
2019-01-30 上传
2012-01-26 上传









