Google MapReduce编程模型:简化大数据处理
"Google Map Reduce 中文版 论文"
Google MapReduce是一种编程模型,专为大规模数据集的处理和生成而设计。它由Jeffrey Dean和Sanjay Ghemawat在Google开发,允许用户通过定义两个关键函数——Map和Reduce,来处理海量数据。Map函数接收键值对作为输入,对其进行操作并生成一系列中间键值对。Reduce函数则负责聚合所有具有相同键的中间结果,将它们整合成单个输出。
MapReduce的核心理念是将复杂、分布式的数据处理任务简化,使得程序员无需具备专业的并行处理或分布式系统知识也能高效地编写程序。运行时系统自动处理数据分布、任务调度、机器故障恢复以及节点间的通信。这种模型极大地降低了处理大规模数据的复杂性。
MapReduce系统在由普通计算机组成的大型集群上运行,具备高可扩展性。一个典型的应用可能涉及上千台机器处理TB级别的数据。由于其易用性,许多开发者已经编写了数百个MapReduce程序,且每天在Google的集群上有数千个作业在运行。
在过去,Google为了处理大量原始数据,如网页抓取、Web请求日志等,构建了许多特定目的的程序,以生成各种数据产品,如倒排索引、网页图谱、主机页面数量摘要等。这些计算虽然概念上简单,但因数据量巨大,往往需要在数百或数千台计算机上并行执行,导致处理代码变得复杂,需要考虑并发、数据分布、容错等问题。
为了解决这一复杂性,MapReduce抽象出这些共性问题,封装到一个库中。这一思想受到Lisp和其他函数式编程语言中map操作的启发,将并行处理、错误恢复和数据分布等底层细节隐藏起来,使程序员能专注于核心的计算逻辑,从而简化了大规模数据处理的任务。
MapReduce的运行流程通常包括以下几个步骤:
1. 分片(Shuffle):输入数据被分割成多个分片,分布到集群的不同节点上。
2. 映射(Map):每个分片上的Map任务并行执行,对数据进行处理并生成中间键值对。
3. 排序(Sort):中间键值对按键进行排序,确保相同的键会被分到一起。
4. 归约(Reduce):Reduce任务处理排序后的键值对,聚合相同键的所有值,生成最终结果。
这种模型的出现极大地推动了大数据处理领域的发展,成为了Hadoop等开源框架的基础,为大数据分析、机器学习和云计算提供了强大的支持。MapReduce的设计理念也被广泛应用于其他分布式计算系统,成为现代数据处理的标准范式之一。
(4) 存储时使用的便宜的 IDE 硬盘,直接放在每一个机器上。并且有一个分布式的文件系统
来管理这些分布在各个机器上的硬盘。文件系统通过复制的方法来在不可靠的硬件上保
证可用性和可靠性。
(5) 用户向调度系统提交请求。每一个请求都包含一组任务,映射到这个计算机 cluster 里的
一组机器上执行。
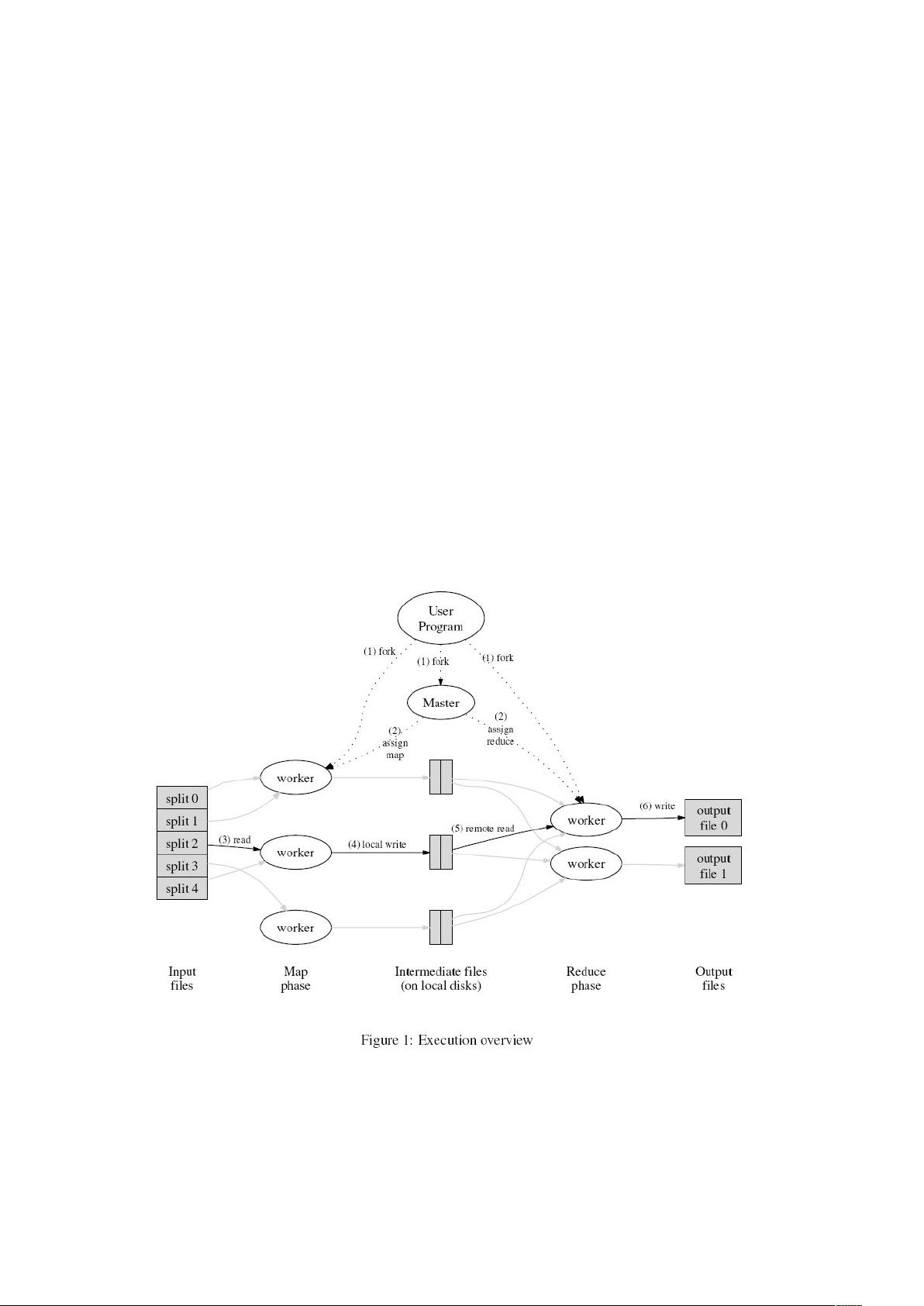
3.1 执行概览
Map 操作通过把输入数据进行分区(partition)(比如分为 M 块),就可以分布到不同的机器上
执行了。输入块的拆成多块,可以并行在不同机器上执行。Reduce 操作是通过对中间产生的 key
的分布来进行分布的,中间产生的 key 可以根据某种分区函数进行分布(比如 hash(key) mod
R),分布成为 R 块。分区(R)的数量和分区函数都是由用户指定的。
图 1 是我们实现的 MapReduce 操作的整体数据流。当用户程序调用 MapReduce 函数,就会引起
如下的操作(图一中的数字标示和下表的数字标示相同)。
第 5 页
剩余24页未读,继续阅读
2017-09-07 上传
2019-08-16 上传
2018-11-12 上传
2018-06-07 上传
2017-05-03 上传
2013-08-27 上传
2014-04-24 上传

普通网友
- 粉丝: 53
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 新代数控API接口实现CNC数据采集技术解析
- Java版Window任务管理器的设计与实现
- 响应式网页模板及前端源码合集:HTML、CSS、JS与H5
- 可爱贪吃蛇动画特效的Canvas实现教程
- 微信小程序婚礼邀请函教程
- SOCR UCLA WebGis修改:整合世界银行数据
- BUPT计网课程设计:实现具有中继转发功能的DNS服务器
- C# Winform记事本工具开发教程与功能介绍
- 移动端自适应H5网页模板与前端源码包
- Logadm日志管理工具:创建与删除日志条目的详细指南
- 双日记微信小程序开源项目-百度地图集成
- ThreeJS天空盒素材集锦 35+ 优质效果
- 百度地图Java源码深度解析:GoogleDapper中文翻译与应用
- Linux系统调查工具:BashScripts脚本集合
- Kubernetes v1.20 完整二进制安装指南与脚本
- 百度地图开发java源码-KSYMediaPlayerKit_Android库更新与使用说明
