
106
107
程序员
2010 10
106
107
程序员
2010 10
Architecture
架构
本
文结合我开发的一套简易搜索
引擎框架
,
和大家分享普通搜
索引擎的架构与实现
。
本搜索引擎开发平台为
Windows
,
使用
C
、
C++
、
Java
、
Python
等语言混
合开发
,
使用
Berkeley DB
、
MySQL
进
行数据持久化存储
。
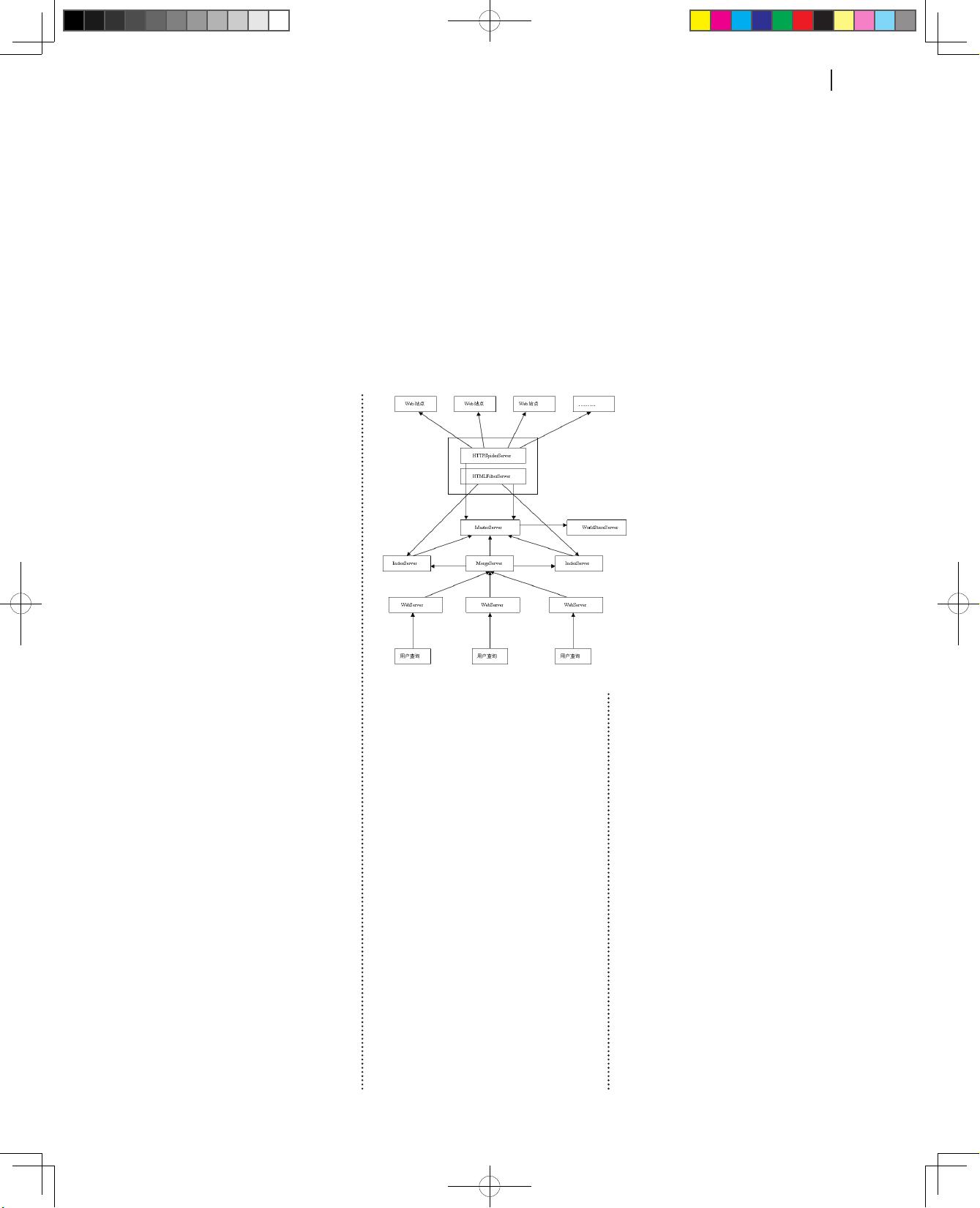
搜索服务器架构
此套搜索引擎
,
由以下服务器构
成
:
专门用于爬虫的文本爬虫服务器
/
图片爬虫服务器
/
多媒体爬虫服务器
,
统称为
HTTPSpiderServer
;
专门用于
分析和提取
HTML
文本的页面分析服务
器
,
命名为
HTMLFilterServer
;
专门用
于存储页面关键字索引
、
进行关键字查
询的索引服务器
,
命名为
IndexServer
;
专门用于协调管理所有服务器的总控服
务器
,
命名为
MasterServer
;
专门用于
存储全局数据信息和映射关系
,
负责增
量式更新的世界仓库服务器
,
命名为
WorldStoreServer
;
专门用于负责用户
输入查询
,
并进行查询结果合并的归并
服务器
,
命名为
Merge
Server
;
专门负
责接收外部页面输入
、
负载外部
I/O
,
实现内外网隔离的网页服务器
,
命名为
WebServer
。
整体的架构如图
1
所示
。
该引擎目前主要包含两大部分功
能
:
一
,
网页爬取
、
分析
、
建立索引
、
入库存储
;
二
,
用户查询处理
。
首先
,
集群通过爬虫服务器爬取互联网各个
站点页面
,
存储到磁盘
,
通过页面分
析服务器
,
对下载的页面信息进行数据
提取
、
分词
,
然后持久化保存到后台索
引服务器中
,
同时
,
在世界仓库服务器
中建立全局对应信息
。
用户通过页面输
入想要查询的文本数据
,
将请求发送给
网页服务器
,
网页服务器再通过后台线
程将该请求转发给内部的归并服务器
,
归并服务器首先会对用户的输入进行分
词
,
得到关键字集后
,
访问对应的索引
服务器查询数据
,
并对查询结果进行调
优排序
,
最后通过网页服务器发送给用
户页面显示
。
下面
,
我们针对集群中每一种具体
功能的服务器进行详细解说
。
总控服务器
总控服务器
,
也称全局服务器
、
中心服务器
。
作为整套集群的管
理协调
者
,
除世界仓库服务器外
,
其他服务器
在启动之后
,
首先必须连接总控
服务器
,
汇报和注册所属服务器
类型和相关信息
,
接受总控服务
器的统一协调和管理
。
目前
,
总
控服务器主要功能在于进行爬虫
服务器和页面分析服务器的负载
均衡调度
,
负责分配负载最小的
服务器进行数据处理
,
另外还负
责通知页面分析服务器和归并服
务器当前集群中所有索引服务器
信息
,
以便让这几种服务器之间
建立联系等
。
在总控服务器内
部
,
每一个爬虫服务器和页面分
析服务器
,
都存在一个当前任务
列表
,
存储当前处理事务的信息
,
从而
实现整套系统精确的负载均衡
。
世界仓库服务器
从整体划分上来说
,
世界仓库服
务器属于总控服务器管制的一部分
,
专
门进行数据的存储和管理
。
在设计之
初
,
为避免将总控服务器设计得过于庞
大和复杂
,
另外考虑到后期会针对全
局数据做更多的功能拓展
,
所以我们单
独提出世界仓库服务器
,
将全局数据存
储和处理从总控服务器中拆分出来
,
逻
辑上划分成单独的服务器
,
专门进行
全
局数据的存储
、
查询和管理
。
目前世界
服务器主要功能包括
:
进行垃圾页面的
过滤
、
分配待爬取的页面数据
、
保存已
经爬取和分析的最终结果数据和负责增
量式更新等
。
内部使用两种数据存储
引擎
:
Berkeley DB
和
MySQL
。
借助于
■
文
/
李成
简易搜索引擎架构与实现
搜索引擎如何实现
?
作者以最简单的搜索引擎为例
,
全面展示搜索引擎的架构与实现
,
可以
说
“
麻雀虽小
,
五脏俱全
”。
图1 搜索服务器的整体的架构
10-技术.indd 107 2010-9-20 22:27:15

gardongao
- 粉丝: 0
- 资源: 5
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- c++校园超市商品信息管理系统课程设计说明书(含源代码) (2).pdf
- 建筑供配电系统相关课件.pptx
- 企业管理规章制度及管理模式.doc
- vb打开摄像头.doc
- 云计算-可信计算中认证协议改进方案.pdf
- [详细完整版]单片机编程4.ppt
- c语言常用算法.pdf
- c++经典程序代码大全.pdf
- 单片机数字时钟资料.doc
- 11项目管理前沿1.0.pptx
- 基于ssm的“魅力”繁峙宣传网站的设计与实现论文.doc
- 智慧交通综合解决方案.pptx
- 建筑防潮设计-PowerPointPresentati.pptx
- SPC统计过程控制程序.pptx
- SPC统计方法基础知识.pptx
- MW全能培训汽轮机调节保安系统PPT教学课件.pptx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论4