
pandas数据的异常值判断、可视化以及异常值的处理数据的异常值判断、可视化以及异常值的处理
pandas数据的异常值判断、可视化、处理方式数据的异常值判断、可视化、处理方式
回想一下我们小时候参加唱歌比赛,最后算分的时候总会去掉一个最高分,去掉一个最低分,将剩下的分数进行去平均。这里
面就有筛选异常值的思想。一个非常夸张的异常值可能会造成对最后统计结果产生比较大的影响。所以,在这里,我们介绍两
种办法来判断异常值,并使用箱线图进行显示。
异常值的判断异常值的判断
1、使用均值和标准差进行判断、使用均值和标准差进行判断
mean 为数据的均值
std 为数据的标准差
数据的正常范围为 【mean-2 × std,mean+2 × std】
接下来我们使用代码来看看
import pandas as pd
import numpy as np
tips = pd.read_csv('tips.csv')
tipmean=tips['tip'].mean()
tipstd = tips['tip'].std()
topnum1 =tipmean+2*tipstd
bottomnum1 = tipmean-2*tipstd
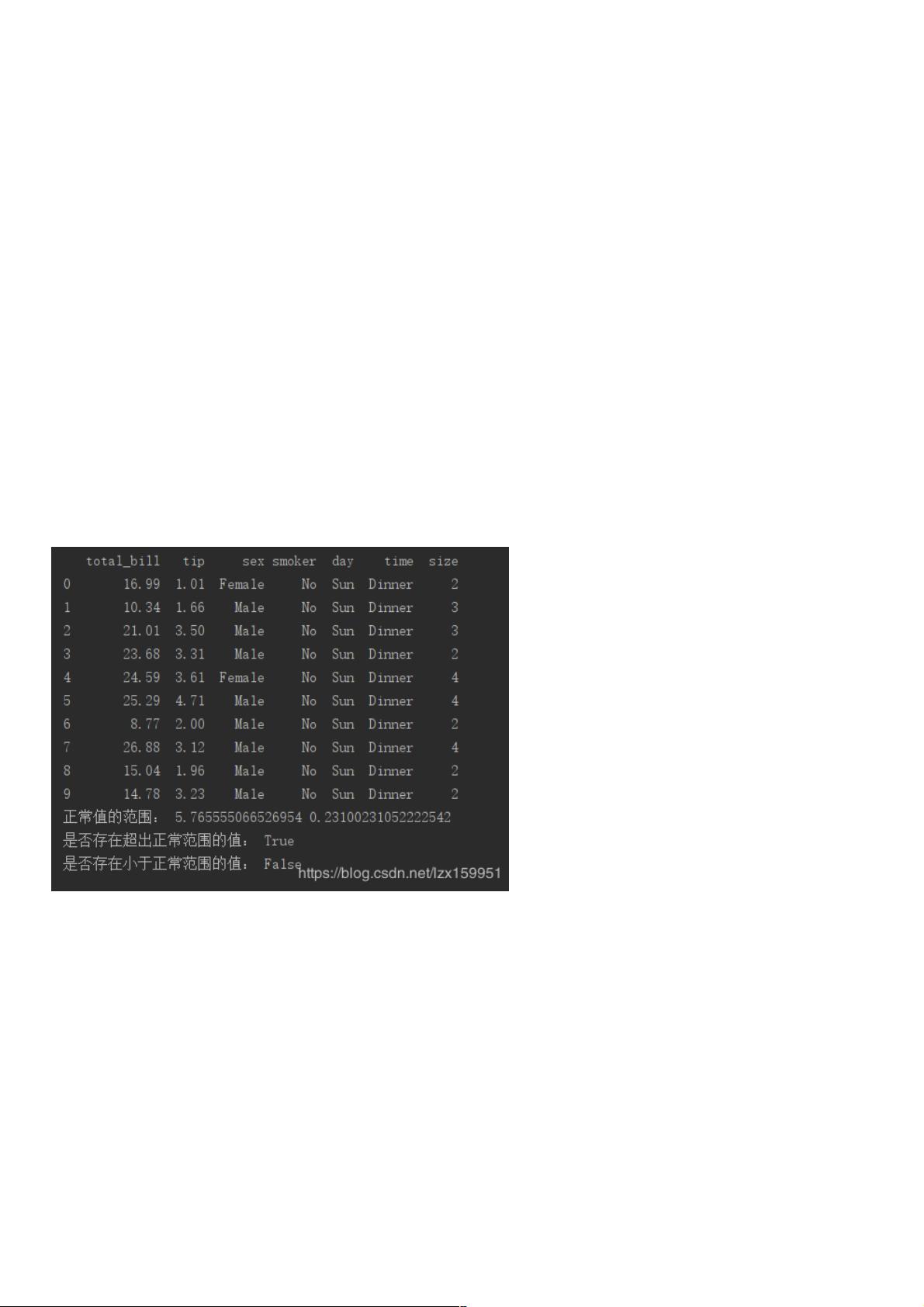
print(tips.head(10))
print("正常值的范围:",topnum1,bottomnum1)
print("是否存在超出正常范围的值:",any(tips['tip']>topnum1))
print("是否存在小于正常范围的值:",any(tips['tip']<bottomnum1))
咱们先看输出结果吧:
首先咱们读入了tips.csv文件,将前十条数据输出到控制台中
我们这次主要使用的是文件中的tip这一列数据,通过mean()、std()两种方法分别计算出了这一列数据的均值和标准差。
通过any()函数分别判断数据中是否存在异常值
结果显示,存在超出正常范围的异常值,不存在小于正常范围的异常值。
使用上四中位数和下四中位数进行异常值判定使用上四中位数和下四中位数进行异常值判定
mean1 为上四中位数(就是将数据按从小到大排列,取3/4这个位置的数)
mean2 为下四中位数(同上,取1/4位置的数)
mean3 为中位差 mean3 = mean1-mean2
正常值的范围应在【mean2-1.5×mean3,mean1+1.5×mean2】
下面看代码:
import pandas as pd
import numpy as np
tips = pd.read_csv('tips.csv')
mean1 = tips['tip'].quantile(q=0.25)#下四分位差
mean2 = tips['tip'].quantile(q=0.75)#上四分位差
mean3 = mean2-mean1#中位差
topnum2 = mean2+1.5*mean3

weixin_38714370
- 粉丝: 2
- 资源: 905
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- c++校园超市商品信息管理系统课程设计说明书(含源代码) (2).pdf
- 建筑供配电系统相关课件.pptx
- 企业管理规章制度及管理模式.doc
- vb打开摄像头.doc
- 云计算-可信计算中认证协议改进方案.pdf
- [详细完整版]单片机编程4.ppt
- c语言常用算法.pdf
- c++经典程序代码大全.pdf
- 单片机数字时钟资料.doc
- 11项目管理前沿1.0.pptx
- 基于ssm的“魅力”繁峙宣传网站的设计与实现论文.doc
- 智慧交通综合解决方案.pptx
- 建筑防潮设计-PowerPointPresentati.pptx
- SPC统计过程控制程序.pptx
- SPC统计方法基础知识.pptx
- MW全能培训汽轮机调节保安系统PPT教学课件.pptx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0