

书书书
第
40
卷
第
6
期
2017
年
6
月
计
算
机
学
报
CHINESE
JOURNAL
OF
COMPUTERS
Vol.40 No.6
June
2017
收稿日期
:
2016
-
07
-
27
;
在线出版日期
:
2017
-
01
-
18.
周飞 燕
,
女
,
1986
年 生
,
博 士 研 究 生
,
主要研究方向为计算机辅助心血管疾病诊断
.
E
-
mail
:
zhf
yy
f15
@
126.com.
金林鹏
,
男
,
1984
年生
,
博士
,
主要研究方向为机器学习
.
董
军
(
通信作者
),
男
,
1964
年生
,
博士
,
研究员
,
博
士生导师
,
主要研究领域为人工智能及其在健康监护
、
传统文化中的应用
.E
-
mail
:
j
don
g
2010
@
sinano.ac.cn.
卷积神经网络研究综述
周飞燕
1
),
2
)
金林鹏
1
),
2
)
董
军
1
)
1
)
(
中国科学院苏州纳米技术与纳米仿生研究所
江苏 苏州
215123
)
2
)
(
中国科学院大学
北京
100049
)
摘
要
作为一个十余年来快速发展的崭新领域
,
深度学习受到了越来越多研究者的关注
,
它在特征提取和建模
上都有着相较于浅层模型显然的优势
.
深度学习善于从原始输入数据中挖掘越来越抽象的特征表示
,
而这些表示
具有良好的泛化能力
.
它克服了过去人工智能中被认为难以解决的一些问题
.
且随着训练数据集数量的显著增长
以及芯片处理能力的剧增
,
它在目标检测和计算机视觉
、
自然语言处理
、
语音识别和语义分析等领域成效卓然
,
因
此也促进了人工智能的发展
.
深度学习是包含多级非线性变换的层级机器学习方法
,
深层神经网络是目前的主要
形式
,
其神经元间的连接模式受启发于动物视觉皮层组织
,
而卷积神经网络则是其中一种经典而广泛应用的结构
.
卷积神经网络的局部连接
、
权值共享及池化操作等特性使之可以有效地降低网络的复杂度
,
减少训练参数的数目
,
使模型对平移
、
扭曲
、
缩放具有一定程度的不变性
,
并具有强鲁棒性和容错能力
,
且也易于训练和优化
.
基于这些优
越的特性
,
它在各种信号和信息处理任务中的性能优于标准的全连接神经网络
.
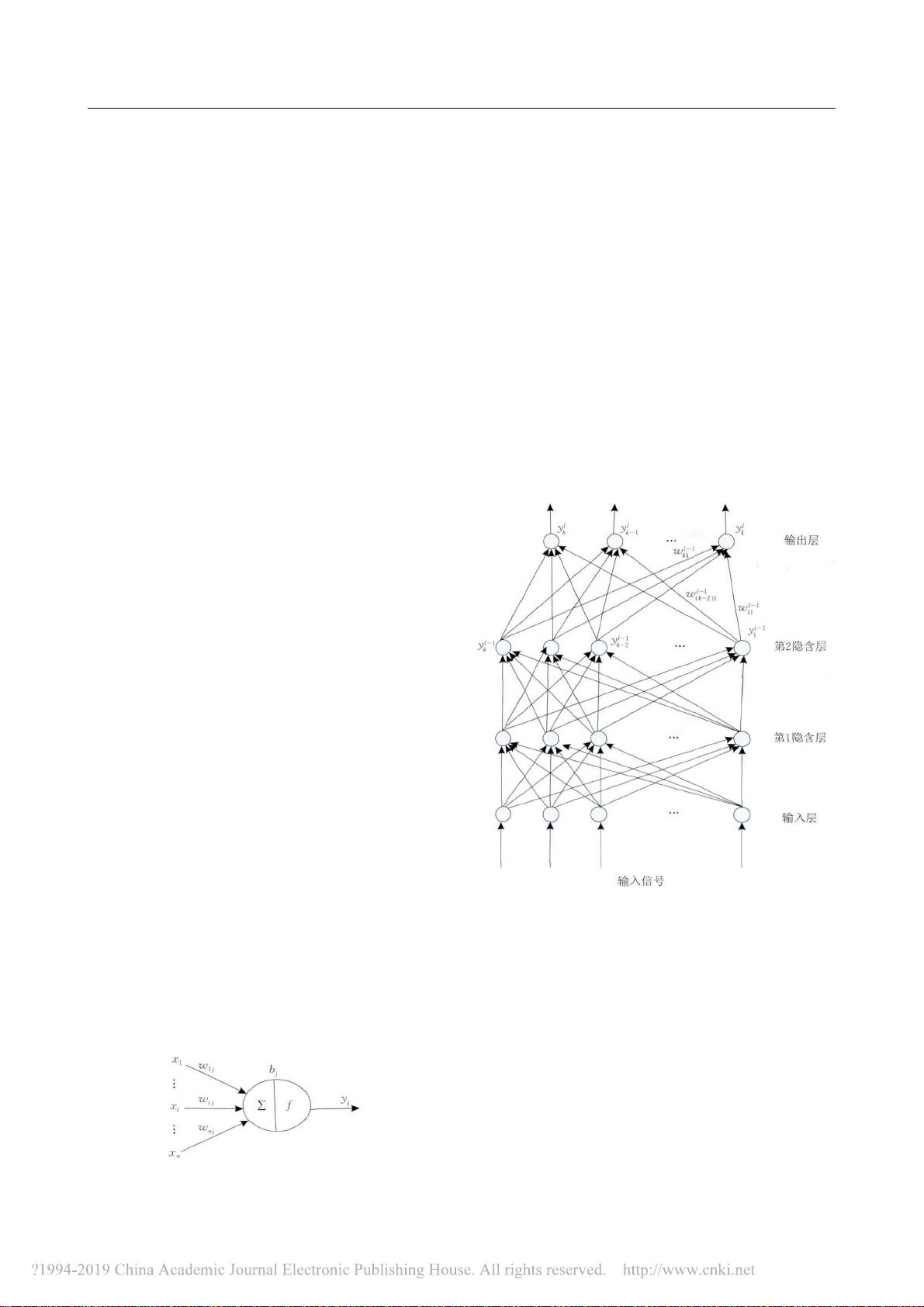
该文首先概述了卷积神经网络的
发展历史
,
然后分别描述了神经元模型
、
多层感知器的结构
.
接着
,
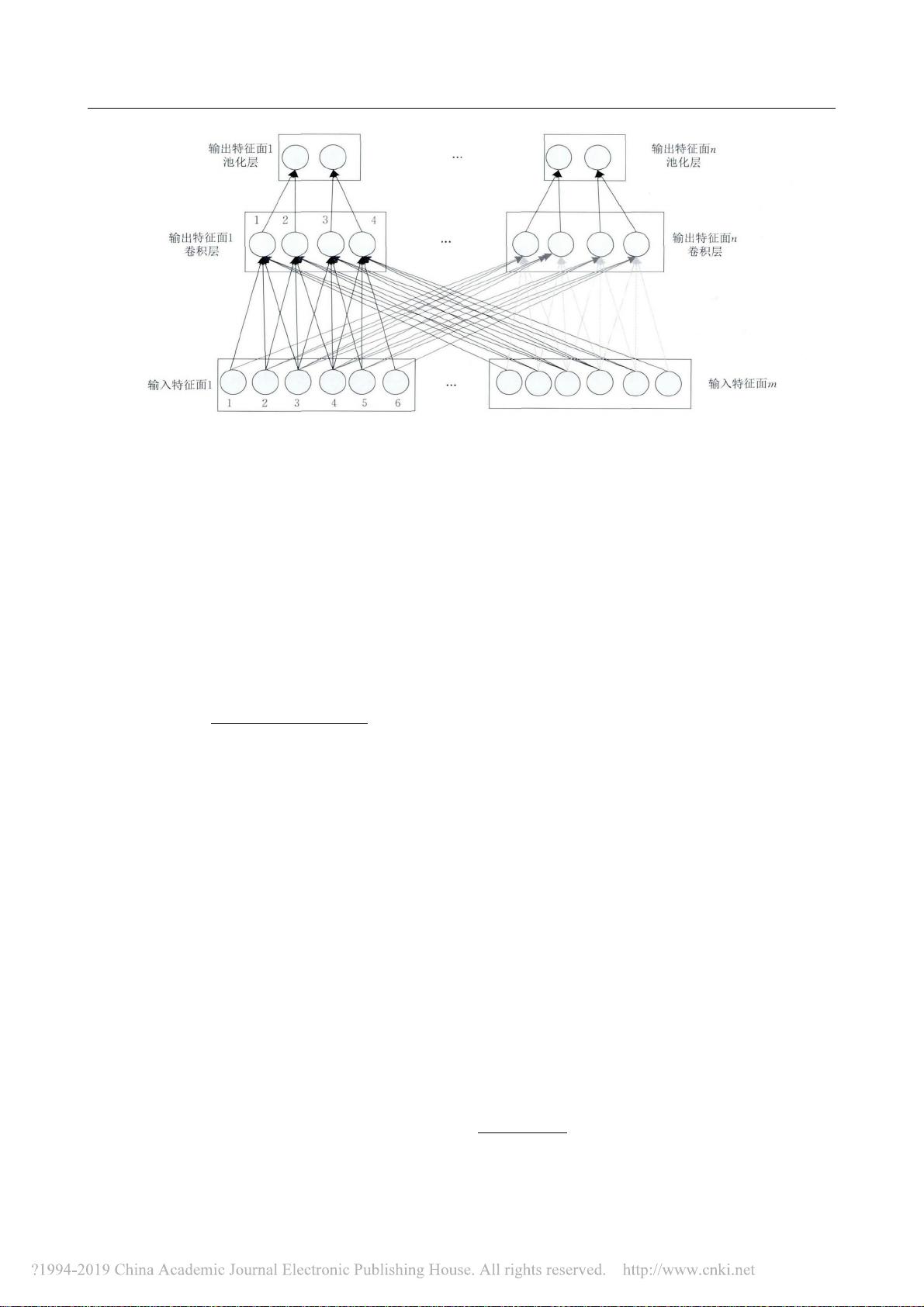
详细分析了卷积神经网络的结构
,
包括卷积层
、
池化层
、
全连接层
,
它们发挥着不同的作用
.
然后
,
讨论了网中网模型
、
空间变换网络等改进的卷积神经网络
.
同时
,
还分别介绍了卷积神经网络的监督学习
、
无监督学习训练方法以及一些常用的开源工具
.
此外
,
该文以图像分类
、
人脸识别
、
音频检索
、
心电图分类及目标检测等为例
,
对卷积神经网络的应用作了归纳
.
卷积神经网络与递归神经
网络的集成是一个途径
.
为了给读者以尽可能多的借鉴
,
该文还设计并试验了不同参数及不同深度的卷积神经网
络来分析各参数间的相互关系及不同参数设置对结果的影响
.
最后
,
给出了卷积神经网络及其应用中待解决的若
干问题
.
关键词
卷积神经网络
;
深度学习
;
网络结构
;
训练方法
;
领域数据
中图法分类号
TP18
DOI
号
10.11897
/
SP.J.1016.2017.01229
Review
of
Convolutional
Neural
Network
ZHOU
Fei
-
Yan
1
),
2
)
JIN
Lin
-
Pen
g
1
),
2
)
DONG
Jun
1
)
1
)
(
Suzhou
Institute
o
f
Nano
-
Tech
and
Nano
-
Bionics
,
Chinese
Academ
y
o
f
Sciences
,
Suzhou
,
Jian
g
su
215123
)
2
)
(
Universit
y
o
f
Chinese
Academ
y
o
f
Sciences
,
Bei
j
in
g
100049
)
Abstract
As
a
new
and
ra
p
idl
y
g
rowin
g
field
for
more
than
ten
y
ears
,
dee
p
learnin
g
has
g
ained
more
and
more
attention
from
different
researchers.Com
p
ared
with
shallow
architectures
,
it
has
g
reat
advanta
g
es
in
both
feature
extractin
g
and
model
fittin
g
.And
it
is
ver
y
g
ood
at
discoverin
g
increasin
g
l
y
abstract
feature
re
p
resentations
whose
g
eneralization
abilit
y
is
stron
g
from
the
raw
in
p
ut
data.It
also
has
successfull
y
solved
some
p
roblems
which
were
considered
difficult
to
solve
in
artificial
intelli
g
ence
in
the
p
ast.Furthermore
,
with
the
outstandin
g
l
y
increased
size
of
data
used
for
trainin
g
and
the
drastic
increases
in
chi
p
p
rocessin
g
ca
p
abilities
,
it
has
resulted
in
si
g
nifi
-
cant
p
ro
g
ress
and
been
used
in
a
broad
area
of
a
pp
lications
such
as
ob
j
ect
detection
,
com
p
uter
vision
,
natural
lan
g
ua
g
e
p
rocessin
g
,
s
p
eech
reco
g
nition
and
semantic
p
arsin
g
and
so
on
,
thus
also


剩余22页未读,继续阅读

olivia_ye
- 粉丝: 10
- 资源: 85
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- c++校园超市商品信息管理系统课程设计说明书(含源代码) (2).pdf
- 建筑供配电系统相关课件.pptx
- 企业管理规章制度及管理模式.doc
- vb打开摄像头.doc
- 云计算-可信计算中认证协议改进方案.pdf
- [详细完整版]单片机编程4.ppt
- c语言常用算法.pdf
- c++经典程序代码大全.pdf
- 单片机数字时钟资料.doc
- 11项目管理前沿1.0.pptx
- 基于ssm的“魅力”繁峙宣传网站的设计与实现论文.doc
- 智慧交通综合解决方案.pptx
- 建筑防潮设计-PowerPointPresentati.pptx
- SPC统计过程控制程序.pptx
- SPC统计方法基础知识.pptx
- MW全能培训汽轮机调节保安系统PPT教学课件.pptx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0