

可能是目前效果最好的开源生成式聊天机器人项目可能是目前效果最好的开源生成式聊天机器人项目—–深入理解深入理解“用于中文闲聊的用于中文闲聊的GPT2模模
型型”项目项目
本文为对于GPT2 for Chinese chitchat项目的理解与学习
项目代码链接:
https://github.com/yangjianxin1/GPT2-chitchat
深入理解深入理解“用于中文闲聊的用于中文闲聊的GPT2模型模型”项目项目论文部分提炼1. Improving Language Understandingby Generative Pre-Training(GPT)摘要介绍最近工作NLP的半监督学习无监督预训
练辅助训练目标框架无监督预训练监督预训练特定任务的输入转换文字蕴涵(Textual entailment)相似性问答与常识推理2. Language Models are Unsupervised Multitask
Learners(GPT-2)摘要介绍方法输入表示模型实验Children’s Book Test(CBT)LAMBADAWinograd Schema ChallengeReading
ComprehensionSummarizationTranslationQuestion AnsweringGeneralization vs Memorization近期工作结论3. DIALOGPT : Large-Scale Generative Pre-trainingfor Conversational
Response Generation摘要介绍数据集方法模型结构互信息最大化关于强化学习的尝试训练加速DSTC-7 Dialogue Generation Challenge关于自动测试分数高于人类的解释局限与挑
战结论代码学习及调试项目结构train.py主要功能模块汇总setup_train_args()set_random_seed()create_logger()create_model()preprocess_raw_data()preprocess_mmi_raw_data()训
练流程(可以先从这里看起,遇到问题再Ctrl+F定位对应模块)训练普通对话模型训练MMI对话模型普通对话生成(interact.py)top_k_top_p_filteringMMI对话生成
(interact_mmi.py)
论文部分提炼论文部分提炼
1. Improving Language Understandingby Generative Pre-Training((GPT))
摘要摘要
自然语言理解包括一系列不同的任务,如文本蕴涵、问答、语义相似性评估和文档分类。尽管大型的未标记文本语料库非常丰富,但用于学习这些特定任务的标记数据却非常稀少,
这使得对有偏向性的模型来说,要充分执行这些任务是一个挑战。与以前的方法相比,我们在微调期间使用任务感知的输入转换来实现有效的转换,同时要求对模型体系结构进行最
小的更改。我们在一系列自然语言理解的基准上证明了我们的方法的有效性,我们的面向一般任务模型优于使用专门为每项任务设计体系结构的训练模型,在所研究的12项任务中,
有9项显著提高了技术水平。
介绍介绍
在自然语言处理(NLP)中,有效地从原始文本中学习是减轻对监督学习依赖的关键。
然而,由于两个主要原因,利用未标记文本中超过单词级别的信息是一个挑战。
首先,不清楚什么类型的优化目标在学习对传输有用的文本表示方面最有效。最近的研究着眼于不同的目标,如语言建模,机器翻译,语篇连贯,每一种方法在不同的任务上都优于
其他方法。
第二,对于将这些学习到的表象传递给目标任务的最有效方式,目前还没有达成共识。
现有技术涉及将任务特定的更改与模型体系结构相结合。使用内部学习方案并添加辅助学习目标。这些不确定性使得开发有效的语言处理半监督学习方法变得非常困难。本文采用无
监督预训练和监督微调相结合的方法,探讨了一种半监督的语言理解任务方法。我们的目标是学习一种普遍的表达方式,这种表达方式很少适应各种各样的任务。我们假设使用人工
标注的训练示例(目标任务)访问一个大的未标记文本语料库和多个数据集。我们的设置不要求这些目标任务与未标记的语料库位于同一域中。
我们采用两阶段训练程序。首先,我们使用语言对未标记的数据进行建模,以学习神经网络模型的初始参数。随后,我们使用相应的有监督目标将这些参数应用于目标任务。
对于我们的模型架构,我们使用Transformer,它已经被证明在各种任务上都有很强的执行能力,比如机器翻译、文档生成和语法分析。与RNN等替代方案相比,这种模型选择为我
们提供了一个更结构化的内存,用于处理文本中的长期依赖项,从而在各种任务中产生健壮的转换性能。 在转换过程中,我们使用从交叉样式( traversal-style)方法派生的特定于
任务的输入自适应,该过程将结构化文本输入作为单个连续的令牌序列。正如我们在实验中所证明的,这些调整使我们能够有效地微调,对预先训练的模型的架构进行最小的更改。
最近工作最近工作
NLP的半监督学习的半监督学习
这种范式广泛应用于序列标记或文本分类,最早的方法是使用未标记的数据来计算单词级或短语级的统计信息,然后将其用作一个监督模型中的特征。在过去的几年里,研究人员已
经证明了使用单词嵌入,即在未标记的语料库上进行训练,来提高任务的平均性能。然而,这些方法主要是传递单词级的信息,而我们的目标是获取更高级别的语义。
最近的方法已经研究了从未标记的数据中学习和使用超过单词级别的语义,短语级或句子级的嵌入,可以使用未标记的语料库进行训练,已经被用来将文本编码成适合各种目标任务
的向量表示。
无监督预训练无监督预训练
无监督预训练是半监督学习的一种特殊情况,其目的是寻找一个好的初始点,而不是修改监督学习目标。早期的工作探索了该技术在图像分类和分类任务中的应用,随后的研究表
明,预训练可以作为一种正则化方案,使深层神经网络具有更好的泛化能力。在最近的工作中,该方法被用来帮助训练深度神经网络完成各种任务,如图像分类、语音识别、实体消
歧和机器翻译。
最接近我们的工作是使用目标语言对神经网络进行预训练,然后在有人监督的情况下对其进行微调。然而,尽管预训练阶段有助于捕获一些语言信息,但它们对LSTM模型的使用将
其可预测性限制在较短的范围内。与此相反,我们选择的 Transformer网络允许我们捕获更长范围的语言结构,这在我们的实验中得到了证明。此外,我们还展示了我们的模型在更
广泛的任务上的有效性,包括自然语言推理、释义和故事完成。其他方法使用预先训练语言或机器翻译模型的隐藏表示作为辅助特征,同时训练目标模型的监督模型。这涉及到每个
目标分离的任务的大量新参数,而在传输期间,我们需要对模型体系结构进行最小的更改。
辅助训练目标辅助训练目标
增加辅助无监督训练目标是半监督学习的另一种形式。Collobert和Weston的早期工作使用了各种各样的辅助NLP任务,如词性标注、分块、命名实体识别和语言模型化来改进语义角
色标注,在目标任务目标上添加一个辅助语言模型,并展示了序列标记任务的性能增益。我们的实验也使用一个辅助的目标,但是正如我们所展示的,无监督的预训练已经学习了与
目标任务相关的几个语言方面。
框架框架
我们的训练程序分为两个阶段。第一阶段是在一个大的文本语料库上学习一个高容量的语言模型。接下来是一个微调阶段,在这个阶段中,我们将模型调整为带有标记数据的判别任
务。
无监督预训练无监督预训练
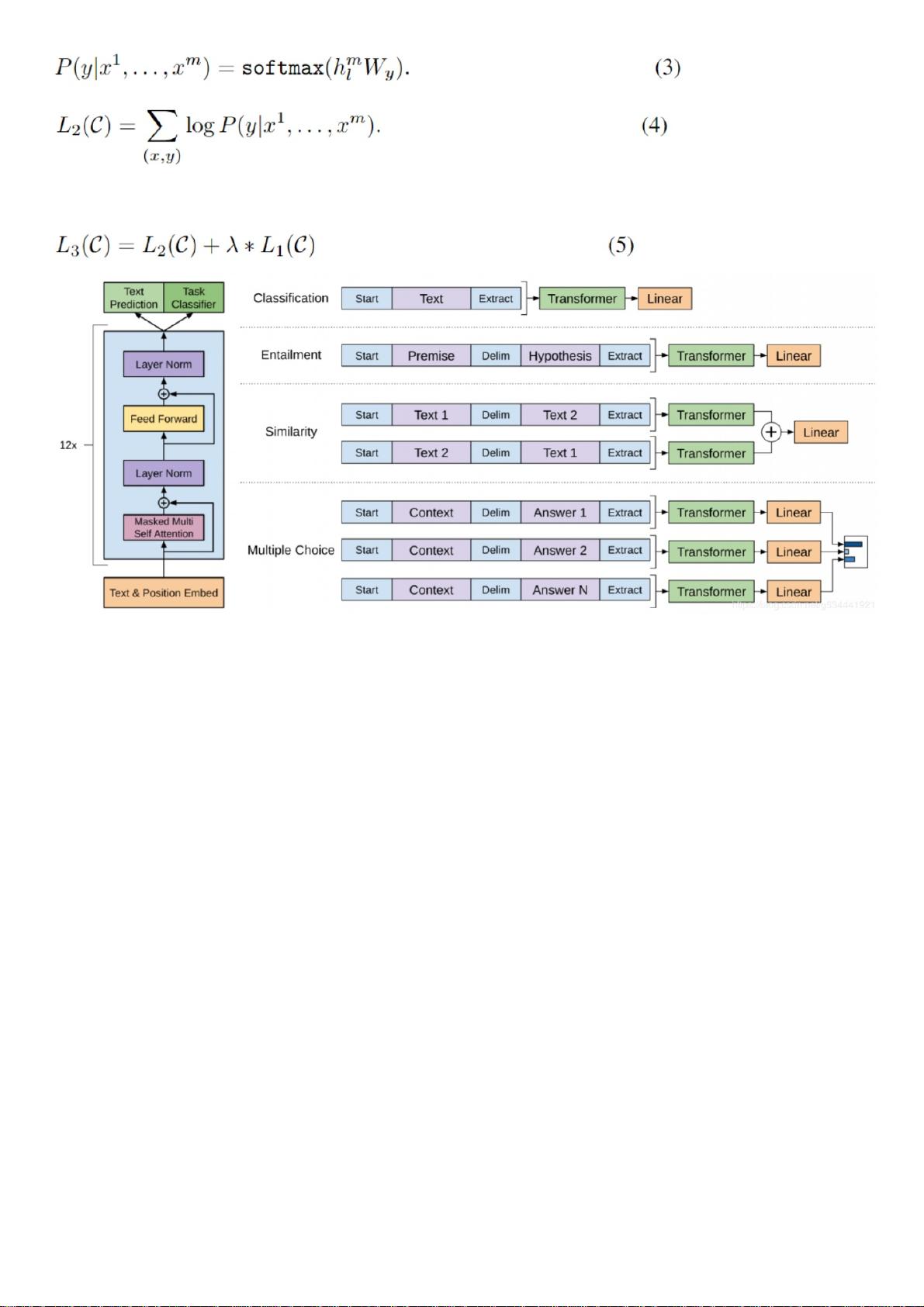
给定一个无监督语料库的标记S= {u1,…,un},我们使用一个标准的语言模型来最大化以下可能性
其中,k是上下文窗口的大小,P为使用参数Θ的神经网络建模的条件概率型。这些参数是用随机梯度下降训练的。
在我们的实验中,我们使用多层Transformer解码器[34]作为语言模型,它是Transformer的变体,此模型对输入上下文标记应用多头自注意操作,然后是位置前馈层,以生成分布在
目标标记上的输出:
其中U是令牌的上下文向量,n是层数,We是令牌嵌入矩阵,Wp是位置嵌入矩阵。
监督预训练监督预训练
在用公式1中的目标模型训练后,我们将参数调整到有监督的目标任务。我们假设一个带标签的数据集C,其中每个实例由一系列输入标记x1,…,xm和标签y组成。输入通过我们预
先训练的模型来获得最终Transformer组的激活hml,然后将其输入一个参数为Wy的加线性输出层(added linear output layer)来预测y:

剩余19页未读,继续阅读

weixin_38748740
- 粉丝: 4
- 资源: 940
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- zigbee-cluster-library-specification
- JSBSim Reference Manual
- c++校园超市商品信息管理系统课程设计说明书(含源代码) (2).pdf
- 建筑供配电系统相关课件.pptx
- 企业管理规章制度及管理模式.doc
- vb打开摄像头.doc
- 云计算-可信计算中认证协议改进方案.pdf
- [详细完整版]单片机编程4.ppt
- c语言常用算法.pdf
- c++经典程序代码大全.pdf
- 单片机数字时钟资料.doc
- 11项目管理前沿1.0.pptx
- 基于ssm的“魅力”繁峙宣传网站的设计与实现论文.doc
- 智慧交通综合解决方案.pptx
- 建筑防潮设计-PowerPointPresentati.pptx
- SPC统计过程控制程序.pptx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0