
详解详解Tensorflow数据读取有三种方式(数据读取有三种方式(next_batch))
本篇文章主要介绍了Tensorflow数据读取有三种方式(next_batch),小编觉得挺不错的,现在分享给大家,也
给大家做个参考。一起跟随小编过来看看吧
Tensorflow数据读取有三种方式:数据读取有三种方式:
1. Preloaded data: 预加载数据
2. Feeding: Python产生数据,再把数据喂给后端。
3. Reading from file: 从文件中直接读取
这三种有读取方式有什么区别呢? 我们首先要知道TensorFlow(TF)是怎么样工作的。
TF的核心是用C++写的,这样的好处是运行快,缺点是调用不灵活。而Python恰好相反,所以结合两种语言的优势。涉及计
算的核心算子和运行框架是用C++写的,并提供API给Python。Python调用这些API,设计训练模型(Graph),再将设计好的
Graph给后端去执行。简而言之,Python的角色是Design,C++是Run。
一、预加载数据:一、预加载数据:
import tensorflow as tf
# 设计Graph
x1 = tf.constant([2, 3, 4])
x2 = tf.constant([4, 0, 1])
y = tf.add(x1, x2)
# 打开一个session --> 计算y
with tf.Session() as sess:
print sess.run(y)
二、二、python产生数据,再将数据喂给后端产生数据,再将数据喂给后端
import tensorflow as tf
# 设计Graph
x1 = tf.placeholder(tf.int16)
x2 = tf.placeholder(tf.int16)
y = tf.add(x1, x2)
# 用Python产生数据
li1 = [2, 3, 4]
li2 = [4, 0, 1]
# 打开一个session --> 喂数据 --> 计算y
with tf.Session() as sess:
print sess.run(y, feed_dict={x1: li1, x2: li2})
说明:在这里x1, x2只是占位符,没有具体的值,那么运行的时候去哪取值呢?这时候就要用到sess.run()中的feed_dict参
数,将Python产生的数据喂给后端,并计算y。
这两种方案的缺点:
1、预加载:将数据直接内嵌到Graph中,再把Graph传入Session中运行。当数据量比较大时,Graph的传输会遇到效率问
题。
2、用占位符替代数据,待运行的时候填充数据。
前两种方法很方便,但是遇到大型数据的时候就会很吃力,即使是Feeding,中间环节的增加也是不小的开销,比如数据类型
转换等等。最优的方案就是在Graph定义好文件读取的方法,让TF自己去从文件中读取数据,并解码成可使用的样本集。
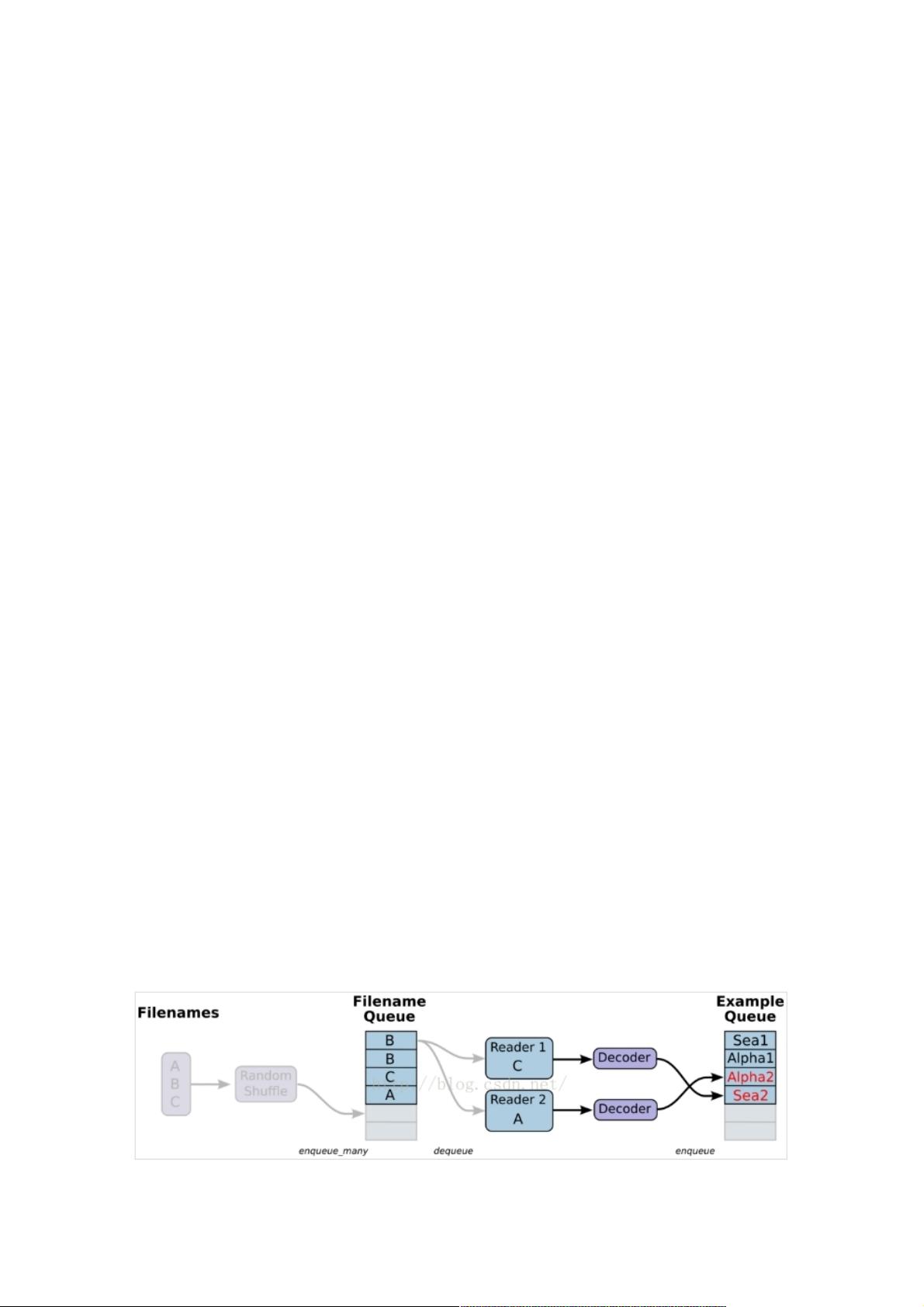
三、从文件中读取,简单来说就是将数据读取模块的图搭好三、从文件中读取,简单来说就是将数据读取模块的图搭好
1、准备数据,构造三个文件,A.csv,B.csv,C.csv
$ echo -e "Alpha1,A1Alpha2,A2Alpha3,A3" > A.csv
$ echo -e "Bee1,B1Bee2,B2Bee3,B3" > B.csv
$ echo -e "Sea1,C1Sea2,C2Sea3,C3" > C.csv

weixin_38601878
- 粉丝: 5
- 资源: 961
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- 医院人力资源规划PPT模板.pptx
- 毕业论文ssm412影院在线售票系统.docx
- 大学毕业论文-—基于单片机的超声波流量计.doc
- 毕业设计(论文)--沉降监测网拟稳平差及程序设计.doc
- 基于ssm+mysql学生信息管理系统源码数据库论文.docx
- 浅谈linux操作系统的安全.doc
- 于基at89s51单片机超声波测距系统的设计-学位论文.doc
- 毕业论文安卓130短信管理(app).doc
- PPT常见问题教程.pdf
- 基于ssm+mysql高校毕业设计管理系统设计与实现.docx
- 医院信息化建设方案培训课件.ppt
- 最新审记软件行业办公室管理制度.pdf
- 基于PHP的网上书店的设计与实现.pptx
- 微机作业-c++基础从0到1
- 左框架三维造型、数控工艺及编程毕业设计.doc
- (完整word)软件著作权-源代码范本.doc
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0