
XGBoost——机器学习(理论机器学习(理论+图解图解+安装方法安装方法+python代码)代码)
文章目录一瞥文章目录一瞥一、集成算法思想二、XGBoost基本思想三、MacOS安装XGBoost四、用python实现XGBoost算法五、xgboost的优化:六、xgboost的优势:1、正则化2、并行处理
3、高度的灵活性4、缺失值处理5、剪枝6、内置交叉验证7、在已有的模型基础上继续七、常用API 介绍1.数据接口 Data Interface2. 参数设置Setting Parameters3.开始训练Training
保存模型4.提前停止Early Stopping5.预测Prediction 使用早停进行预测6.绘图Plotting八、代码实践
在竞赛题中经常会用到XGBoost算法,用这个算法通常会使我们模型的准确率有一个较大的提升。既然它效果这么好,那么它从头到尾做了一件什么事呢?以及它是怎么样去做的
呢?
我们先来直观的理解一下什么是XGBoost。XGBoost算法是和决策树算法联系到一起的。决策树算法在我的另一篇博客中讲过了.
xgboost 的全称是eXtreme Gradient Boosting,由华盛顿大学的陈天奇博士提出,在Kaggle的希格斯子信号识别竞赛中使用,因其出众的效率与较高的预测准确度而引起了广泛的关
注。
与GBDT的区别
GBDT算法只利用了一阶的导数信息,xgboost对损失函数做了二阶的泰勒展开,并在目标函数之外加入了正则项对整体求最优解,用以权衡目标函数的下降和模型的复杂程度,避免
过拟合。所以不考虑细节方面,两者最大的不同就是目标函数的定义,接下来就着重从xgboost的目标函数定义上来进行介绍。
xgboost的模型
xgboost对应的模型就是一堆CART树。一堆树如何做预测呢?就是将每棵树的预测值加到一起作为最终的预测值,可谓简单粗暴。
一、集成算法思想一、集成算法思想
在决策树中,我们知道一个样本往左边分或者往右边分,最终到达叶子结点,这样来进行一个分类任务。 其实也可以做回归任务。
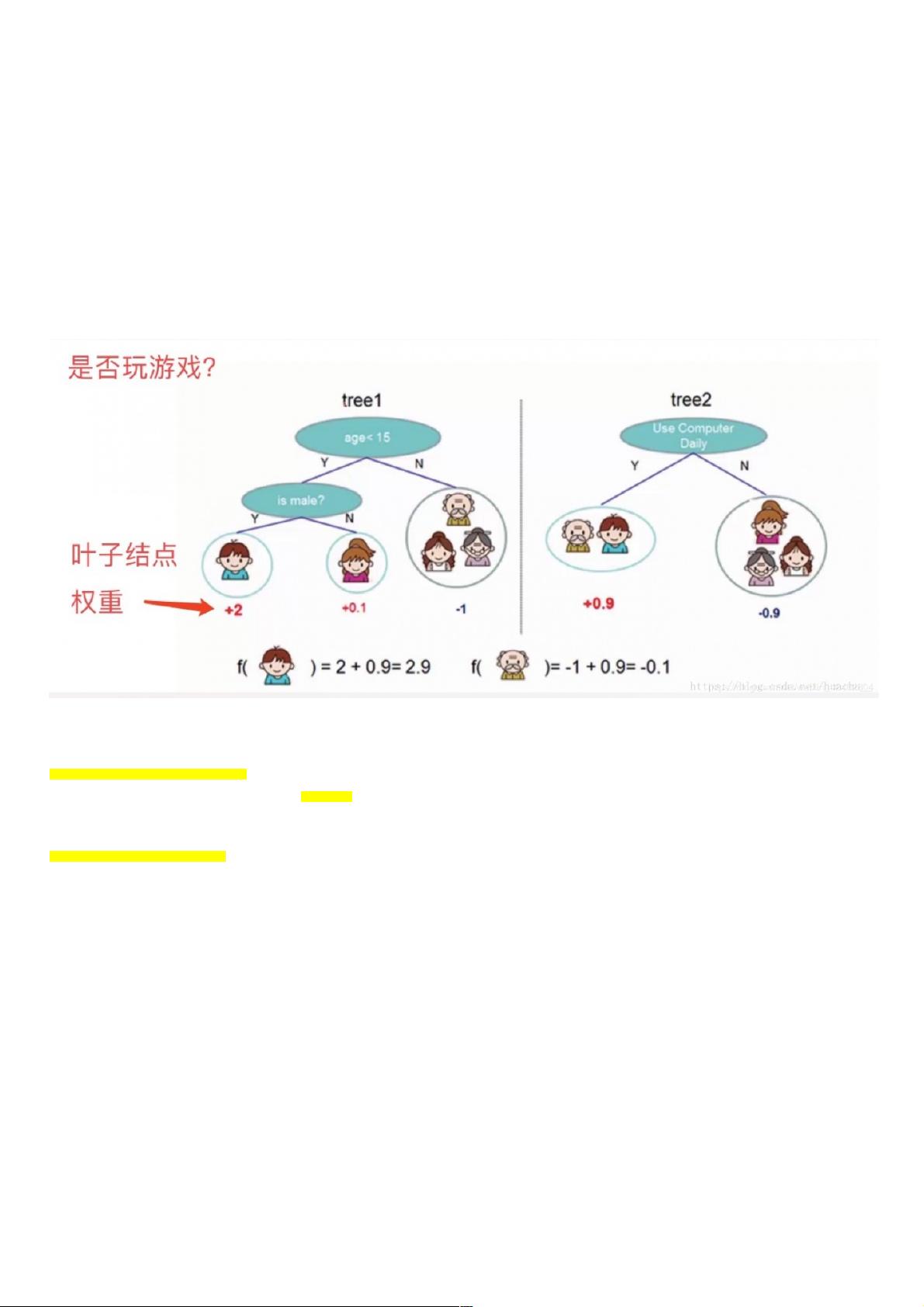
看上面一个图例左边:有5个样本,现在想看下这5个人愿不愿意去玩游戏,这5个人现在都分到了叶子结点里面,对不同的叶子结点分配不同的权重项,正数代表这个人愿意去玩游
戏,负数代表这个人不愿意去玩游戏。所以我们可以通过叶子结点和权值的结合,来综合的评判当前这个人到底是愿意还是不愿意去玩游戏。上面「tree1」那个小男孩它所处的叶子
结点的权值是+2(可以理解为得分)。
用单个决策树好像效果一般来说不是太好,或者说可能会太绝对。通常我们会用一种集成的方法,
就是一棵树效果可能不太好,用两棵树呢?
看图例右边的「tree2」,它和左边的不同在于它使用了另外的指标,出了年龄和性别,还可以考虑使用电脑频率这个划分属性。通过这两棵树共同帮我们决策当前这个人愿不愿意玩
游戏,小男孩在「tree1」的权值是+2,在「tree2」的权值是+0.9, 所以小男孩最终的权值是+2.9(可以理解为得分是+2.9)。老爷爷最终的权值也是通过一样的过程得到的。
所以说,我们通常在做分类或者回归任务的时候,需要想一想一旦选择用一个分类器可能表达效果并不是很好,那么就要考虑用这样一个集成的思想。上面的图例只是举了两个分类
器,其实还可以有更多更复杂的
弱分类器,一起组合成一个强分类器。
二、二、XGBoost基本思想基本思想
XGBoost的集成表示是什么?怎么预测?求最优解的目标是什么?看下图的说明你就能一目了然。

weixin_38711149
- 粉丝: 4
- 资源: 902
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- 数据结构1800题含完整答案详解.doc
- 医疗企业薪酬系统设计与管理方案.pptx
- 界面与表面技术界面理论与表面技术要点PPT学习教案.pptx
- Java集合排序及java集合类详解(Collection、List、Map、Set)讲解.pdf
- 网页浏览器的开发 (2).pdf
- 路由器原理与设计讲稿6-交换网络.pptx
- 火电厂锅炉过热汽温控制系统设计.doc
- 企业识别CIS系统手册[收集].pdf
- 物业管理基础知识.pptx
- 第4章财务预测.pptx
- 《集成电路工艺设计及器件特性分析》——实验教学计算机仿真系.pptx
- 局域网内共享文件提示没有访问权限的问题借鉴.pdf
- 第5章网络营销策略.pptx
- 固井质量测井原理PPT教案.pptx
- 毕业实习总结6篇.doc
- UGNX建模基础篇草图模块PPT学习教案.pptx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0