
天气预报天气预报 :天气数据集爬取:天气数据集爬取 + 可视化可视化 + 13种模型预测种模型预测
前几天一直在研究 Python 爬虫技术,只为从互联网上获取数据集。
本文就是利用前几天学到的爬虫知识使用 Python 爬取天气数据集,并做的一期讨论日期与最低气温能是否是最高气温的影响因素,进而判断能否精确预测第二天的天气情况日期与最低气温能是否是最高气温的影响因素,进而判断能否精确预测第二天的天气情况。
由于本文开始写作与5月9日,当天想预测第二天也就是5月10日的气温数据,但由于内容较多,到10日下午才写完。所以数据预测的内容有些“陈旧”,还请读者多多包涵。
目录目录
1 天气数据集爬取
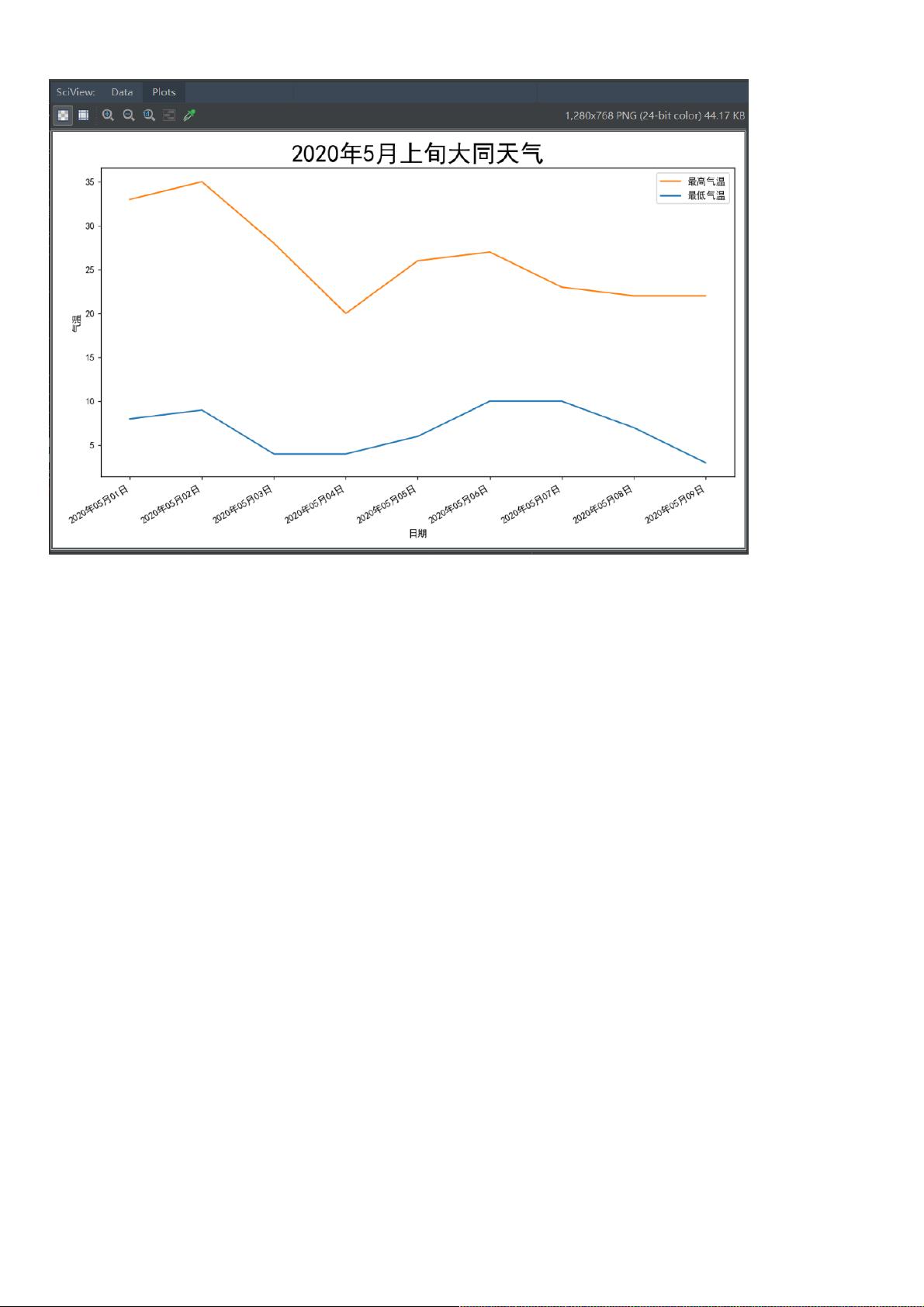
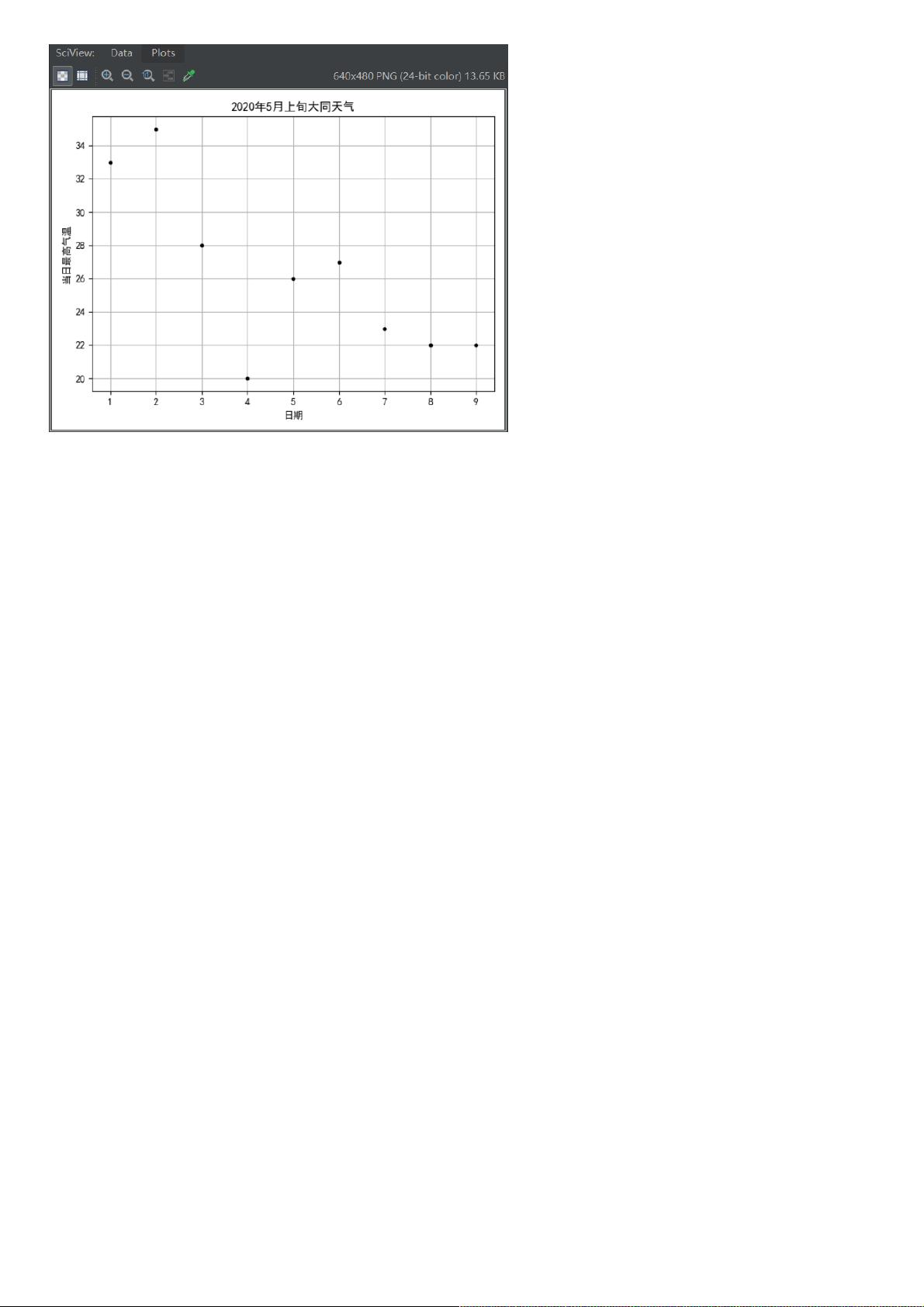
2 数据可视化
3 模型预测数据
3.1 单变量线性回归
模型一:单变量线性回归模型
3.2 多变量线性回归
模型二:基于LinearRegression实现的多变量线性回归模型
模型三:基于成本函数和梯度下降实现的多变量线性回归模型
3.3 以”线性回归”的方式来拟合高阶曲线
模型四:一阶线性拟合
模型五:二阶曲线拟合
模型六:三阶曲线拟合
3.4 线性回归预测天气
模型七:线性回归预测模型
3.5 线性回归的其它计算方法
模型八:基于协方差-方差公式实现的线性回归模型
模型九:基于成本函数和批量梯度下降算法实现的线性回归模型
模型十:基于SGDRegressor随机梯度下降算法的实现
3.6 对数几率回归
模型十一:使用LogisticRegression进行逻辑回归模型
模型十二:基于成本函数和梯度下降算法进行逻辑回归模型
模型十三:基于scipy.optimize优化运算库实现对数几率回归模型
4 总结
5 声明
1 天气数据集爬取天气数据集爬取
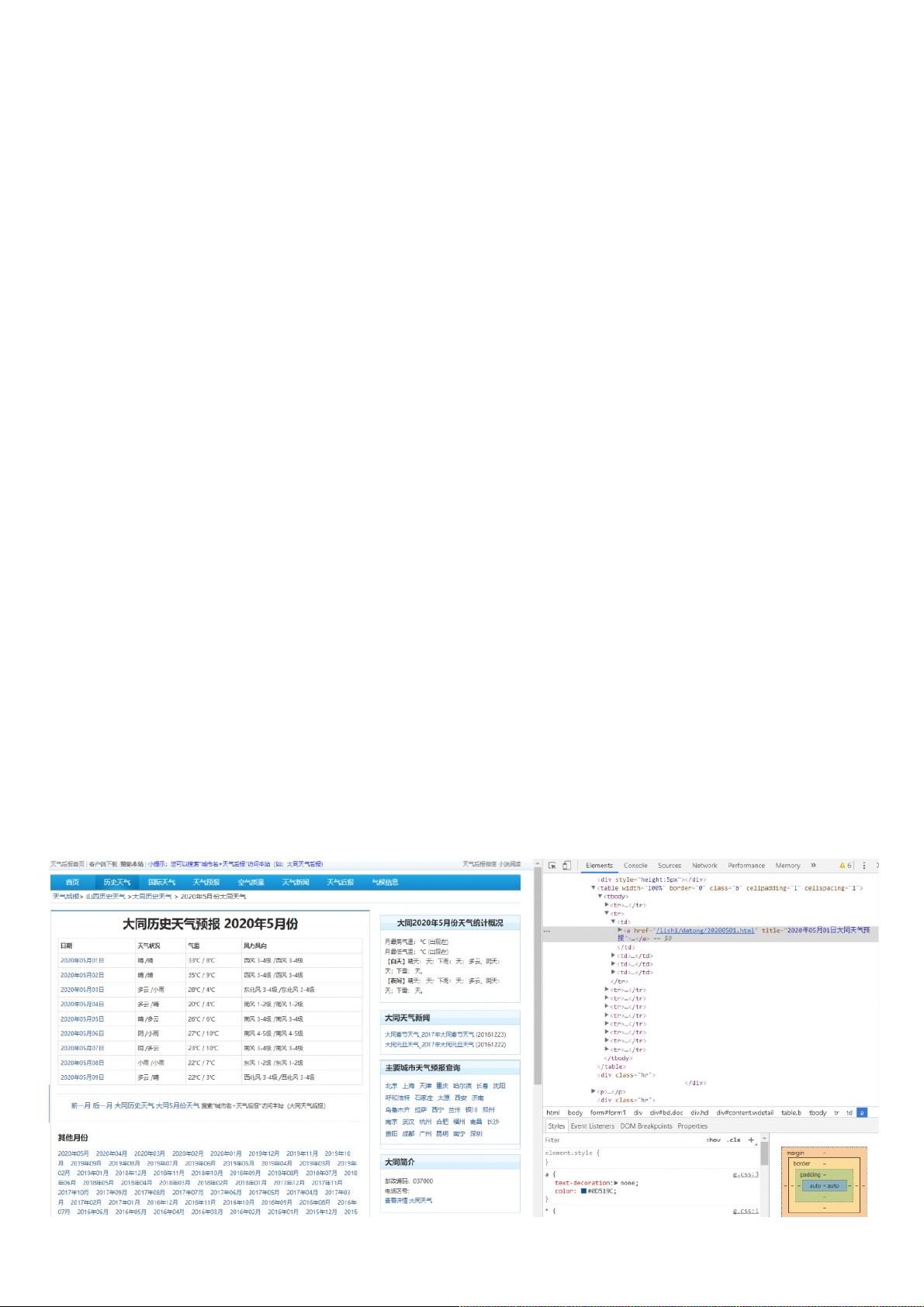
爬取思路爬取思路:确定目标确定目标(目标网站:大同历史天气预报 2020年5月份)
请求网页请求网页(第三方库 requests)
解析网页解析网页(数据提取)
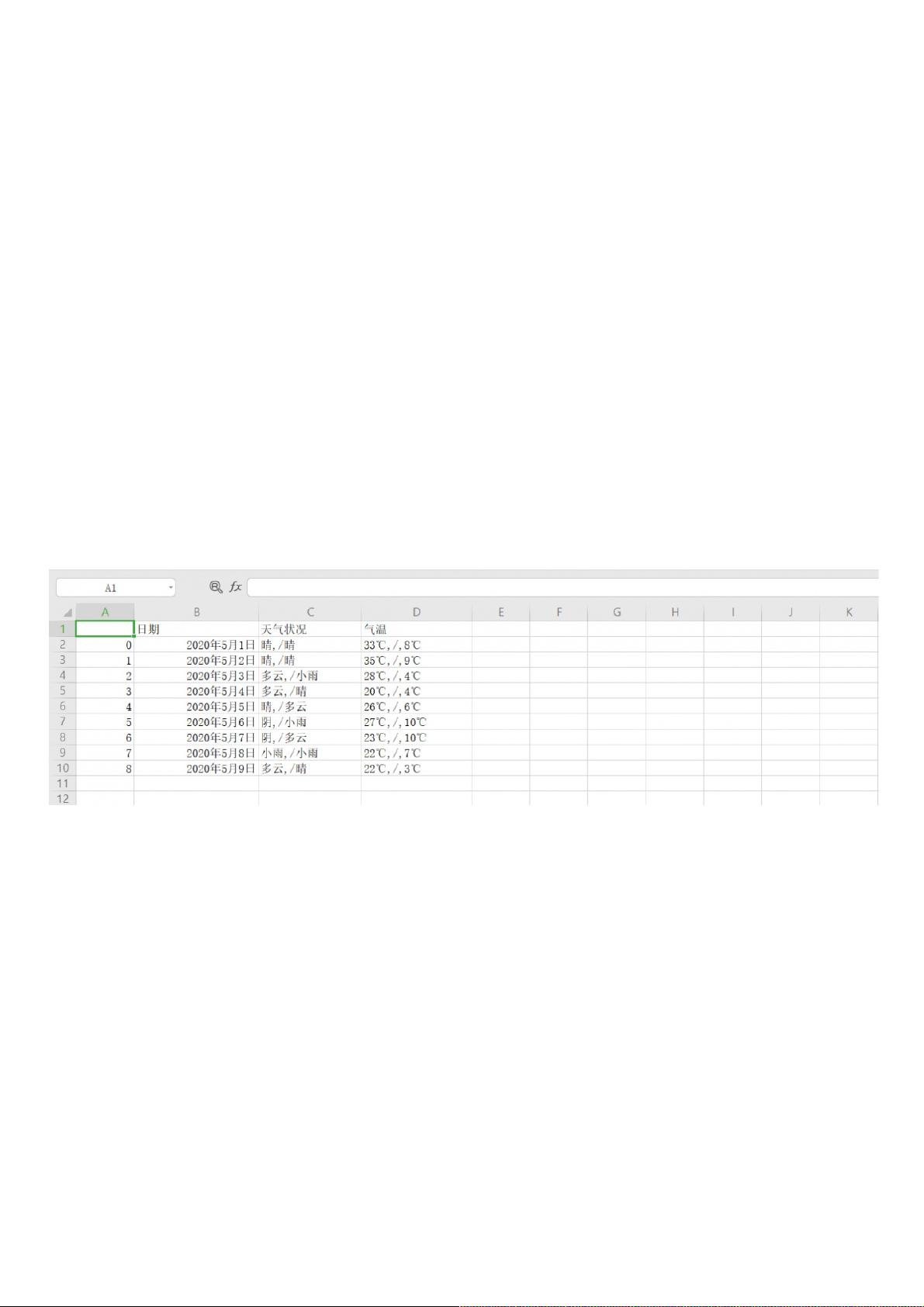
保存数据保存数据(这里以 .csv 格式存储到本地)
因为之前作过爬虫方面的文章,且本文重点放在数据可视化及预测上,故具体爬虫思路不在这里一一赘述。
读者可参考下方代码中的注释进一步理解,亦可参考我发表过的文章,这里给出链接:
①Python爬虫:10行代码真正实现“可见即可爬”
②正则表达式心中有,还愁爬虫之路不好走?
import requests
from bs4 import BeautifulSoup
剩余17页未读,继续阅读

weixin_38670420
- 粉丝: 6
- 资源: 949
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- zigbee-cluster-library-specification
- JSBSim Reference Manual
- c++校园超市商品信息管理系统课程设计说明书(含源代码) (2).pdf
- 建筑供配电系统相关课件.pptx
- 企业管理规章制度及管理模式.doc
- vb打开摄像头.doc
- 云计算-可信计算中认证协议改进方案.pdf
- [详细完整版]单片机编程4.ppt
- c语言常用算法.pdf
- c++经典程序代码大全.pdf
- 单片机数字时钟资料.doc
- 11项目管理前沿1.0.pptx
- 基于ssm的“魅力”繁峙宣传网站的设计与实现论文.doc
- 智慧交通综合解决方案.pptx
- 建筑防潮设计-PowerPointPresentati.pptx
- SPC统计过程控制程序.pptx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论5