
基于脉动阵列的卷积计算模块硬件设计基于脉动阵列的卷积计算模块硬件设计
针对FPGA实现卷积神经网络中卷积计算的过程中,高并行度带来长广播、多扇入/扇出的数据通路问题,采用
脉动阵列来实现卷积神经网络中卷积计算模块,将权重固定到每个处理单元中,并按照输入和输出特征图的维
度来设置脉动阵列的大小,最后通过Vivado高层次综合实现卷积计算模块的硬件设计。实验结果表明,本设计
在实现1级流水化时序要求的同时,具有较低的资源占用和良好的扩展性。
0 引言引言
在过去的几年里,深度神经网络(Deep Neural Network,DNN)在图像分类、目标检测
[1]
及图像分割等领域起到十分重要的
作用。这些使用的各种DNNs及其拓扑结构中,卷积神经网络(Convolutional Neural Network,CNN)是其中最为常见的实现方
式。目前在硬件加速方案中,主要有基于CPU、GPU以及FPGA三种主流方案。考虑到 CPU性能限制和GPU功耗高的问题,
采用FPGA来实现卷积神经网络成为了一种可行的实现方式,例如文献[2]在FPGA中实现神经网络目标检测系统,其检测速度
与能效均优于CPU。采用传统的Verilog HDL或者VHDL硬件描述语言实现卷积神经网络较为困难
[3]
,高层次综合(High Level
Synthesis,HLS)将C/C++代码通过特定的编译器转化为相应的RTL级的代码,降低了卷积神经网络的开发难度,减少了卷积
神经网络的开发周期。
使用FPGA实现卷积神经网络中卷积计算模块的过程中,通常采用循环平铺和循环展开
[4]
的方式实现。这种方式以扩大并行
度来达到网络的时间复杂度。但是当输入和输出特征图维度增加时,扩大并行度会带来硬件设计中长广播、多扇入/扇出的数
据通路,导致卷积计算模块无法在较高的主频上运行。因此,很多神经网络加速器都使用脉动阵列来优化加速器架构设计,如
谷歌TPU加速器
[5]
、ShiDianNao加速器
[6]
等。而在这些加速器架构设计中大多是采用im2col
[7]
的方式,即将参与卷积计算的输
入特征图和权重展开为两个矩阵,然后进行矩阵乘法运算。这种实现方式因为卷积步长的存在而产生大量的数据重叠,不利于
在FPGA的片上块存储器(Block RAM,BRAM)内进行存储。
为了解决上述存在的问题,本文提出一种基于脉动阵列的卷积计算模块设计,将由并行展开所带来的长数据通路变为每个
处理单元的短数据通路;并按照存储矩阵的坐标向卷积计算模块中输入特征图数据,以解决im2col方式存在的数据重叠,不利
于BRAM存储的问题。整体设计使用Vivado HLS开发环境进行实现与优化。
1 本文工作本文工作
1.1 脉动阵列实现卷积计算模块脉动阵列实现卷积计算模块
脉动阵列(Systiloc Array)
[8]
是1970年KUNG H T
[9]
提出的一种应用在片上多处理器的体系结构,由多个相同的、结构简单的计
算单元(Processing Element,PE)以网格状形式连接而成,具有并行性、规律性和局部通信的特征。信号处理算法如卡尔曼滤
波
[10]
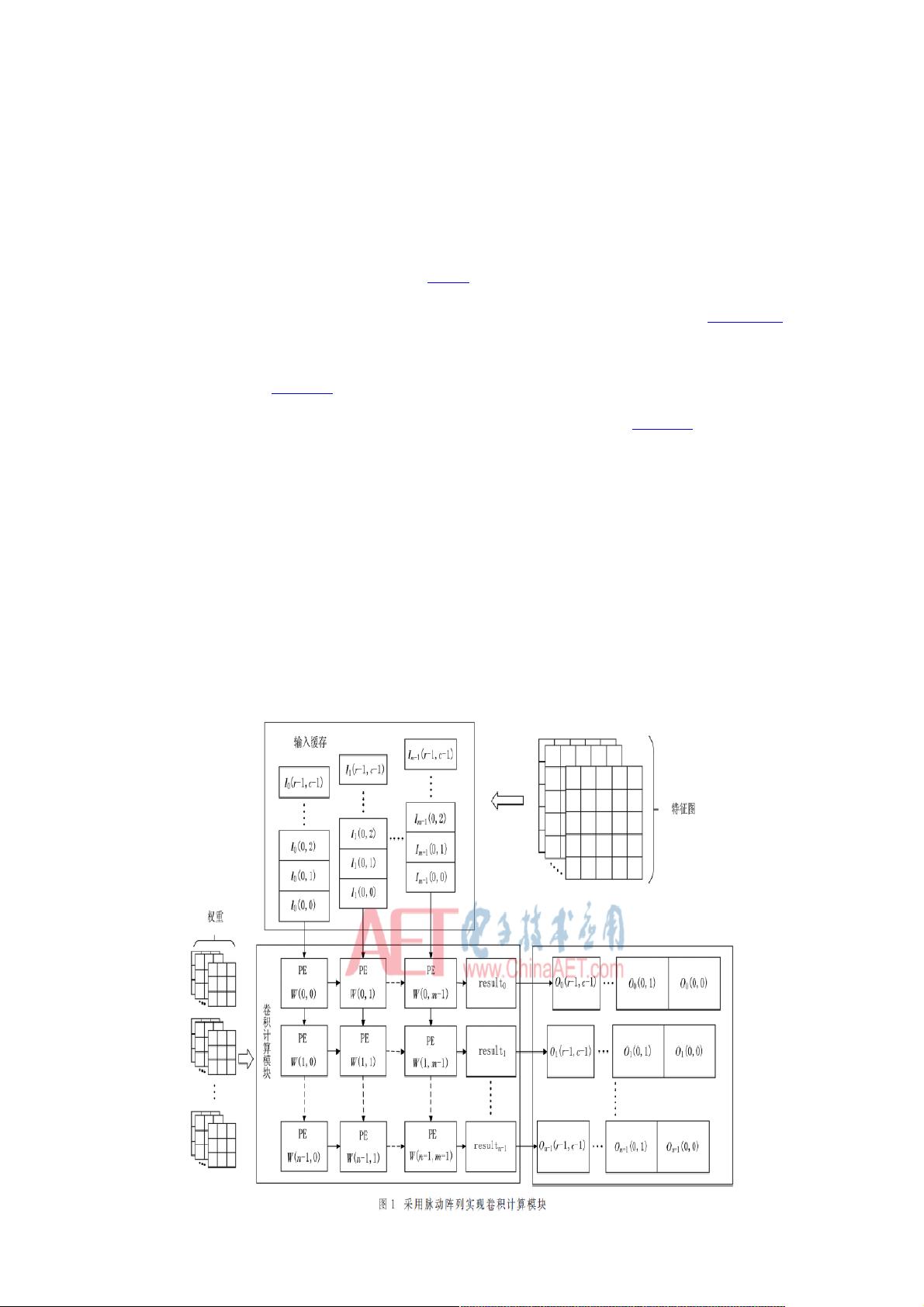
和数值线性代数算法都可以用脉动阵列来实现。本文卷积计算模块中采用的脉动阵列实现方式如图1所示。
在图1中,I表示输入特征图,W表示权重参数,O表示输出特征图,r、c分别表示特征图的长和宽,m、n分别表示输入特征

等你下课⊙▽⊙
- 粉丝: 291
- 资源: 963
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- RTL8188FU-Linux-v5.7.4.2-36687.20200602.tar(20765).gz
- c++校园超市商品信息管理系统课程设计说明书(含源代码) (2).pdf
- 建筑供配电系统相关课件.pptx
- 企业管理规章制度及管理模式.doc
- vb打开摄像头.doc
- 云计算-可信计算中认证协议改进方案.pdf
- [详细完整版]单片机编程4.ppt
- c语言常用算法.pdf
- c++经典程序代码大全.pdf
- 单片机数字时钟资料.doc
- 11项目管理前沿1.0.pptx
- 基于ssm的“魅力”繁峙宣传网站的设计与实现论文.doc
- 智慧交通综合解决方案.pptx
- 建筑防潮设计-PowerPointPresentati.pptx
- SPC统计过程控制程序.pptx
- SPC统计方法基础知识.pptx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0