

第 1 章 初识 Flink
Flink 是 Apache 基金会旗下的一个开源大数据处理框架。目前,Flink 已经成为各大公司
大数据实时处理的发力重点,特别是国内以阿里为代表的一众互联网大厂都在全力投入,为
Flink 社区贡献了大量源码。如今 Flink 已被很多人认为是大数据实时处理的方向和未来,许多
公司也都在招聘和储备掌握 Flink 技术的人才。
那 Flink 到底是什么,又有什么样的优点,能够让大家对它如此青睐呢?
本章我们就来做一个详细的了解。首先讲述 Flink 的源起和设计理念,接着介绍 Flink 如
今的应用领域;进而通过梳理数据处理架构的发展演变,解答为什么要用 Flink 的疑问。进而
梳理 Flink 的特点,并同另一个流行的大数据处理框架 Spark 进行比较,从而更深刻地理解 Flink
的底层架构和优势所在。
1.1 Flink 的源起和设计理念
Flink 起源于一个叫作 Stratosphere 的项目,它是由 3 所地处柏林的大学和欧洲其他一些大
学在 2010~2014 年共同进行的研究项目,由柏林理工大学的教授沃克尔·马尔科(Volker Markl)
领衔开发。2014 年 4 月,Stratosphere 的代码被复制并捐赠给了 Apache 软件基金会,Flink 就
是在此基础上被重新设计出来的。
在德语中,“flink”一词表示“快速、灵巧”。项目的 logo 是一只彩色的松鼠,当然了,
这不仅是因为 Apache 大数据项目对动物的喜好(是否联想到了 Hadoop、Hive?),更是因为
松鼠这种小动物完美地体现了“快速、灵巧”的特点。关于 logo 的颜色,还一个有趣的缘由:
柏林当地的松鼠非常漂亮,颜色是迷人的红棕色;而 Apache 软件基金会的 logo,刚好也是一
根以红棕色为主的渐变色羽毛。于是,Flink 的松鼠 Logo 就设计成了红棕色,而且拥有一个漂
亮的渐变色尾巴,尾巴的配色与 Apache 软件基金会的 logo 一致。这只松鼠色彩炫目,既呼应
了 Apache 的风格,似乎也预示着 Flink 未来将要大放异彩。Flink 的 Logo 如图 1-1 所示。
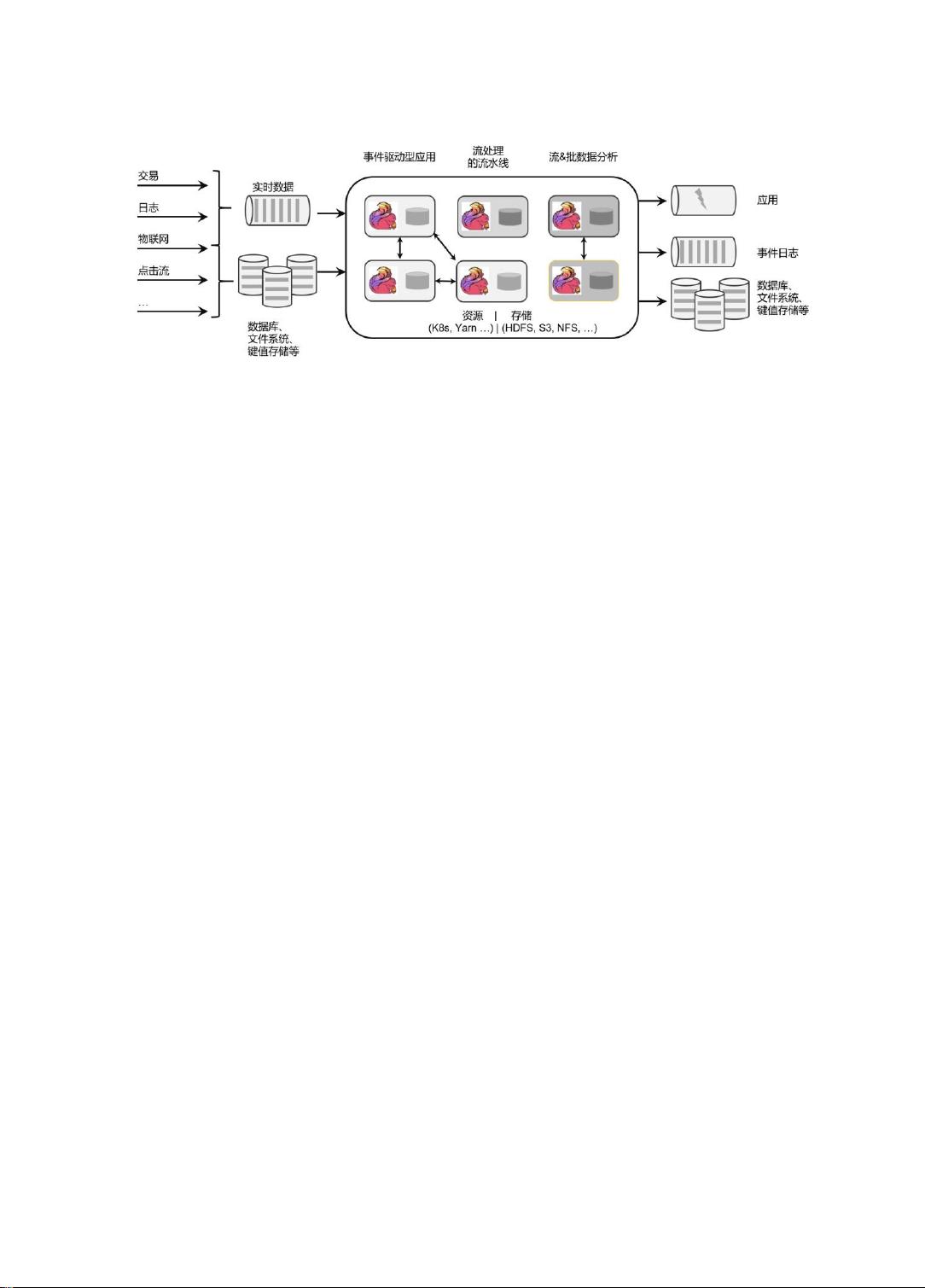
图 1-1 Flink 的 Logo 图



剩余405页未读,继续阅读


落花雨时
- 粉丝: 688
- 资源: 15
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- RTL8188FU-Linux-v5.7.4.2-36687.20200602.tar(20765).gz
- c++校园超市商品信息管理系统课程设计说明书(含源代码) (2).pdf
- 建筑供配电系统相关课件.pptx
- 企业管理规章制度及管理模式.doc
- vb打开摄像头.doc
- 云计算-可信计算中认证协议改进方案.pdf
- [详细完整版]单片机编程4.ppt
- c语言常用算法.pdf
- c++经典程序代码大全.pdf
- 单片机数字时钟资料.doc
- 11项目管理前沿1.0.pptx
- 基于ssm的“魅力”繁峙宣传网站的设计与实现论文.doc
- 智慧交通综合解决方案.pptx
- 建筑防潮设计-PowerPointPresentati.pptx
- SPC统计过程控制程序.pptx
- SPC统计方法基础知识.pptx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论3