

资源由 www.eimhe.com 美河学习在线收集分享
1
Hbase 分布式数据库
一、Hbase 数据库概述;
二、Hbase 体系结构;
三、Hbase 数据库模型;
四、总结 Hbase 整体特点;
五、案例:搭建 Hbase 分布式数据库系统;
一、Hbase 数据库概述;
概述:Hbase 是一个基于 HDFS 的面向列的分布式数据库,源于 Google 的 BigTable 基于 GFS
进行分布式数据存储一样,前文提到,Hbase 是基于流式数据访问,对于第时间延迟的数据
访问并不适合在 HDFS 上运行,所以需要实时性的随机访问超大规模的数据集,使用 Hbase
则是更好的选择;
作用:Hbase 作为典型的非关系型数据库,Nosql 数据库主要分为以下几类:
基于键值对存储的类型;
基于文档存储的类型;
基于列存储的类型;
基于图形数据存储的类型;
在 Nosql 领域中,Hbase 本身不是最优秀的,但得益于与 hadoop 的整合,为其带来了强大
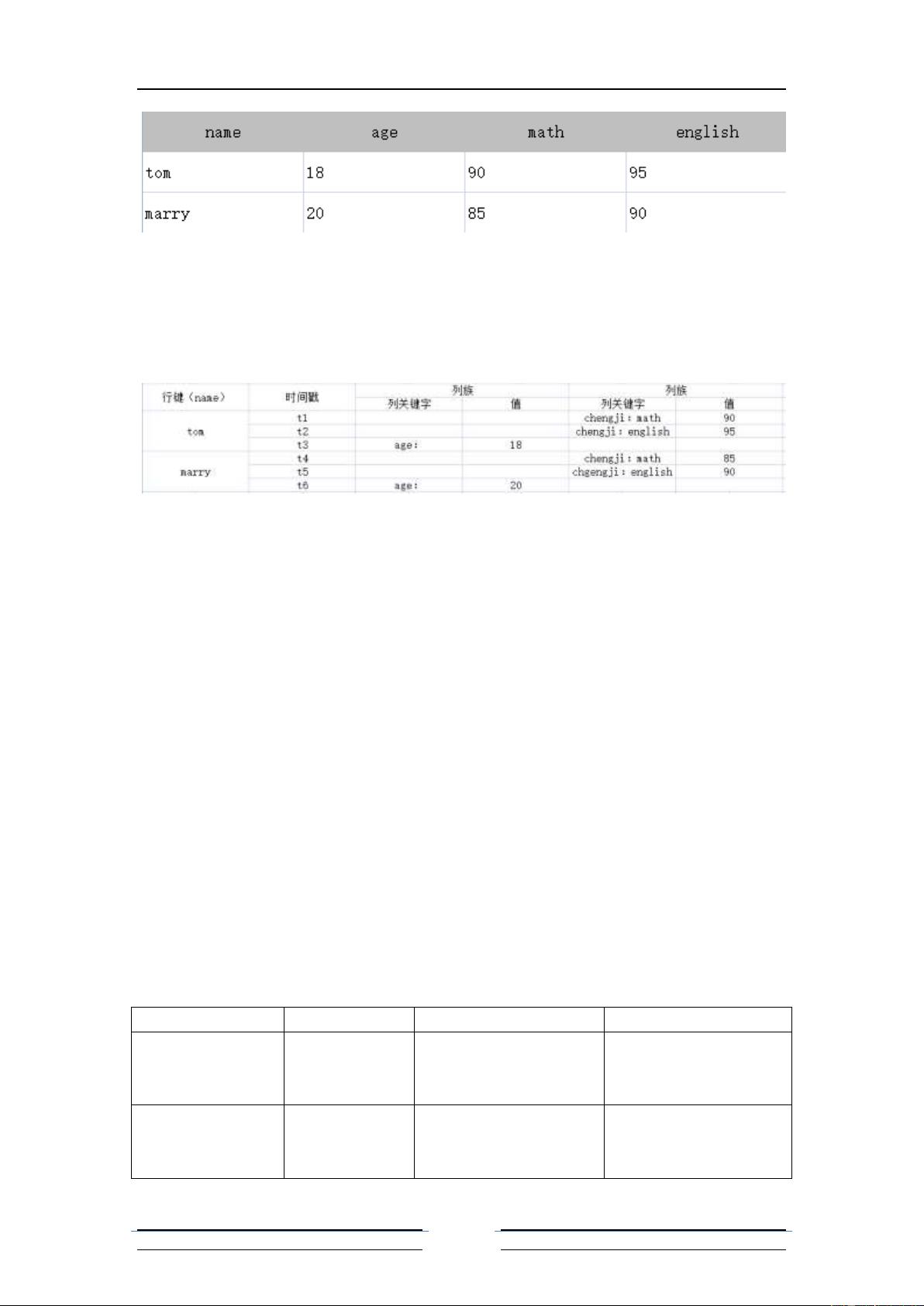
的扩展空间。Hbase 本质只有插入操作,更新删除等操作都是通过插入操作来完成,这是由
于底层 HDFS 流式访问(一次写入,多次读取)决定的,每次插入数据时,数据会带有“时
间戳”的标记,形成多个版本,Hbase 对于一个数据会保留其固定的版本数量,如果在查询
时,也是显示出距离当前时间最近的一个新版本;
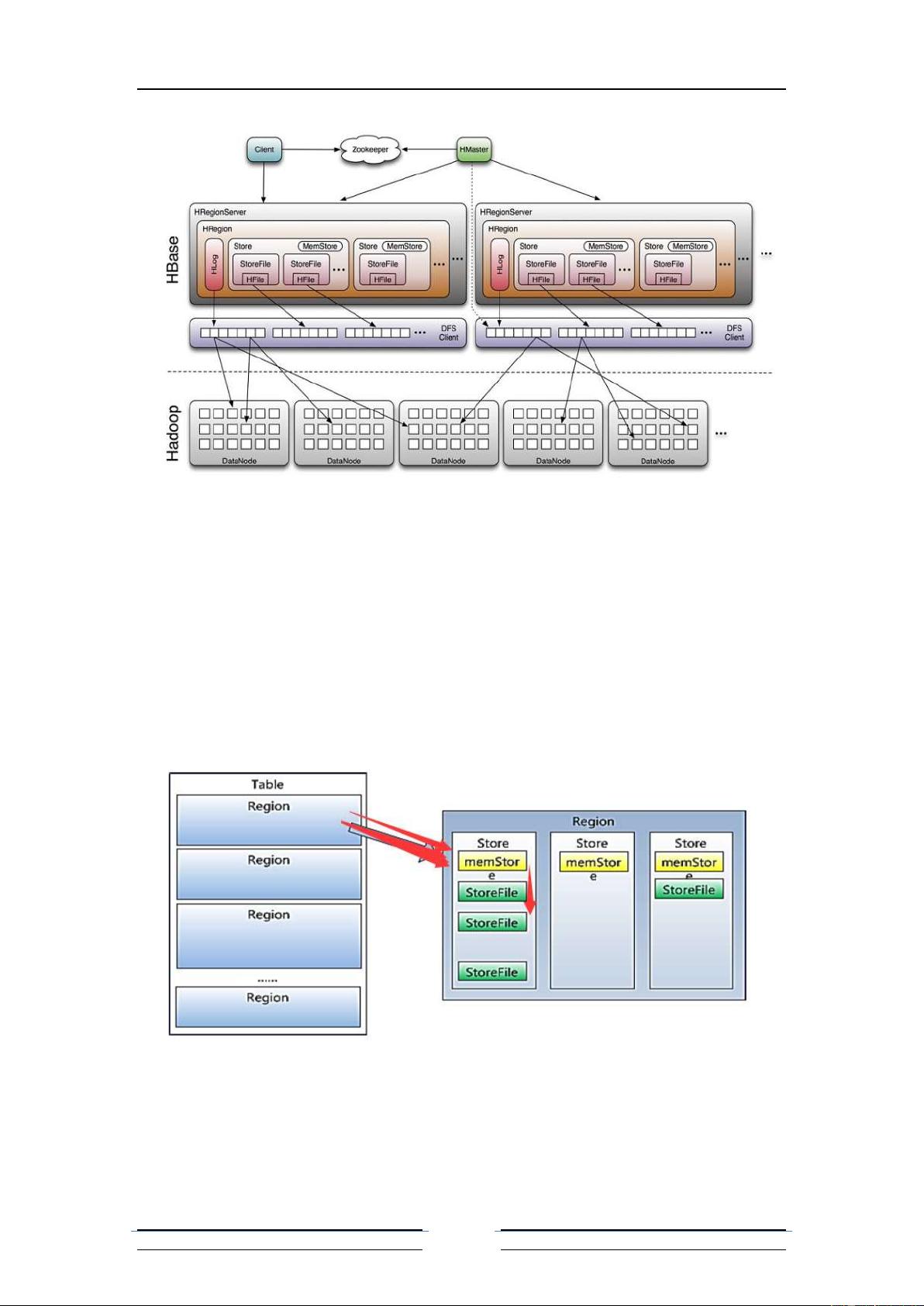
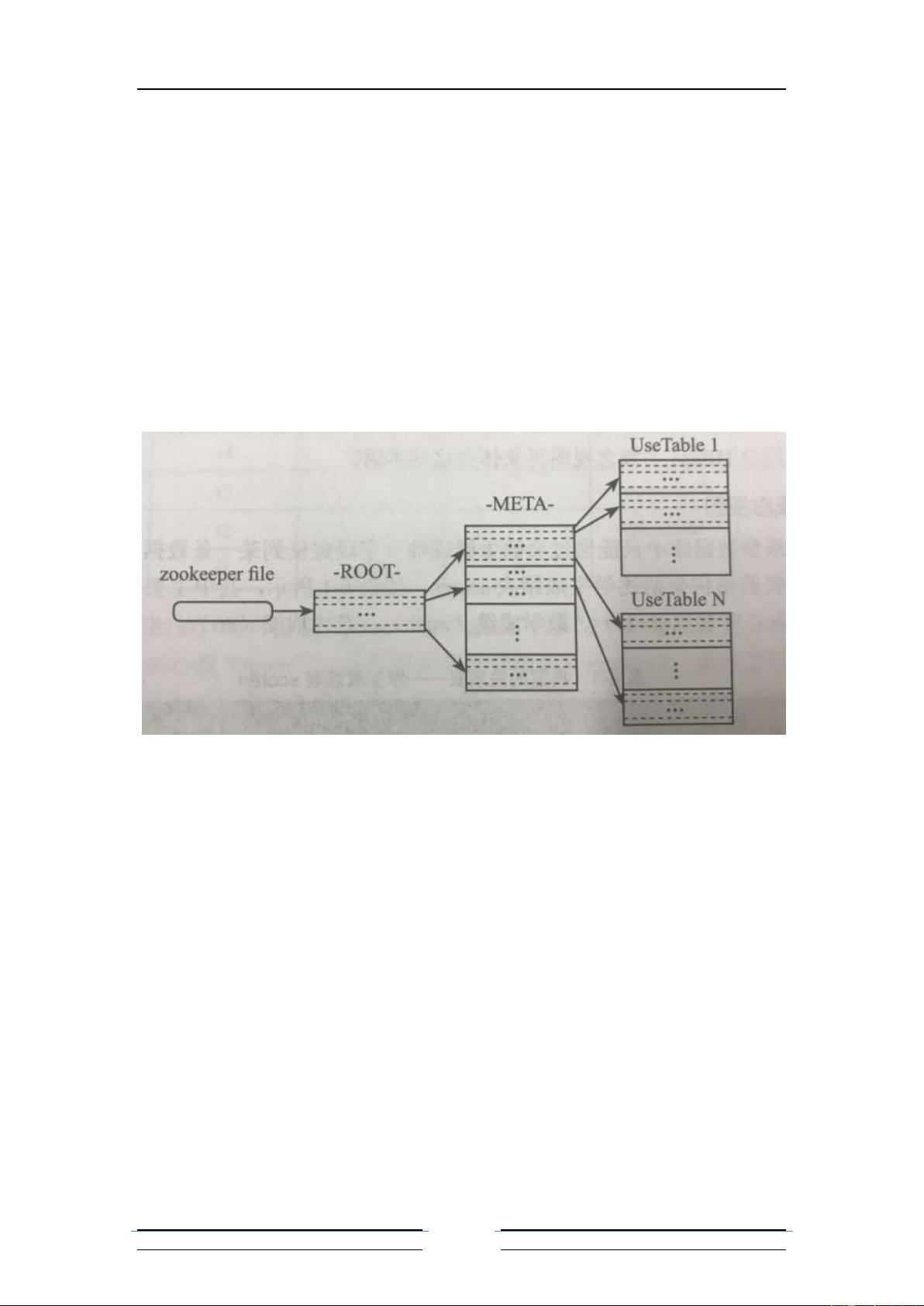
二、Hbase 体系结构;
体系结构:
剩余15页未读,继续阅读

machen_smiling
- 粉丝: 506
- 资源: 1958
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- 面 向 对 象 课 程 设 计(很详细)
- 复杂可编程逻辑器件ppt课件.ppt
- 2021.12-2021居住客群消费趋势年报-贝壳-20页.pdf
- (完整word版)基于单片机的智能交通灯控制系统设计.doc
- 四川天羚绒业公司电子商务营销策略研究.docx
- TI-DS125BR111.pdf
- Oracle培训基础1.ppt
- SAP-Warehouse-Insights-中文介绍
- sed&awk;手册
- MATLAB6.0数学手册精简版
- 年数据库技术大会万振龙数据治理与大数据平台设计40.pptx
- 计算机组装维修教程11
- 全国统一数据资产登记体系建设白皮书.pdf
- 北邮概率论与随机过程课件 教学内容: 1、事件的独立性; 2、伯努利试验概型。
- 电子商务与民航信息化(PPT).ppt
- SAP等公司的面试题
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0