使用Pandas进行相关性分析:从散点图到相关系数
52 浏览量
更新于2023-03-16
5
收藏 133KB PDF 举报
本文主要探讨了数据特征分析中的相关性分析,特别提到了在Python的Pandas库中使用`corr`方法进行相关性计算。文章介绍了三种常用的方法来判断变量间的相关性:图示初判(散点图)、Pearson相关系数以及Spearman秩相关系数。
1. 图示初判
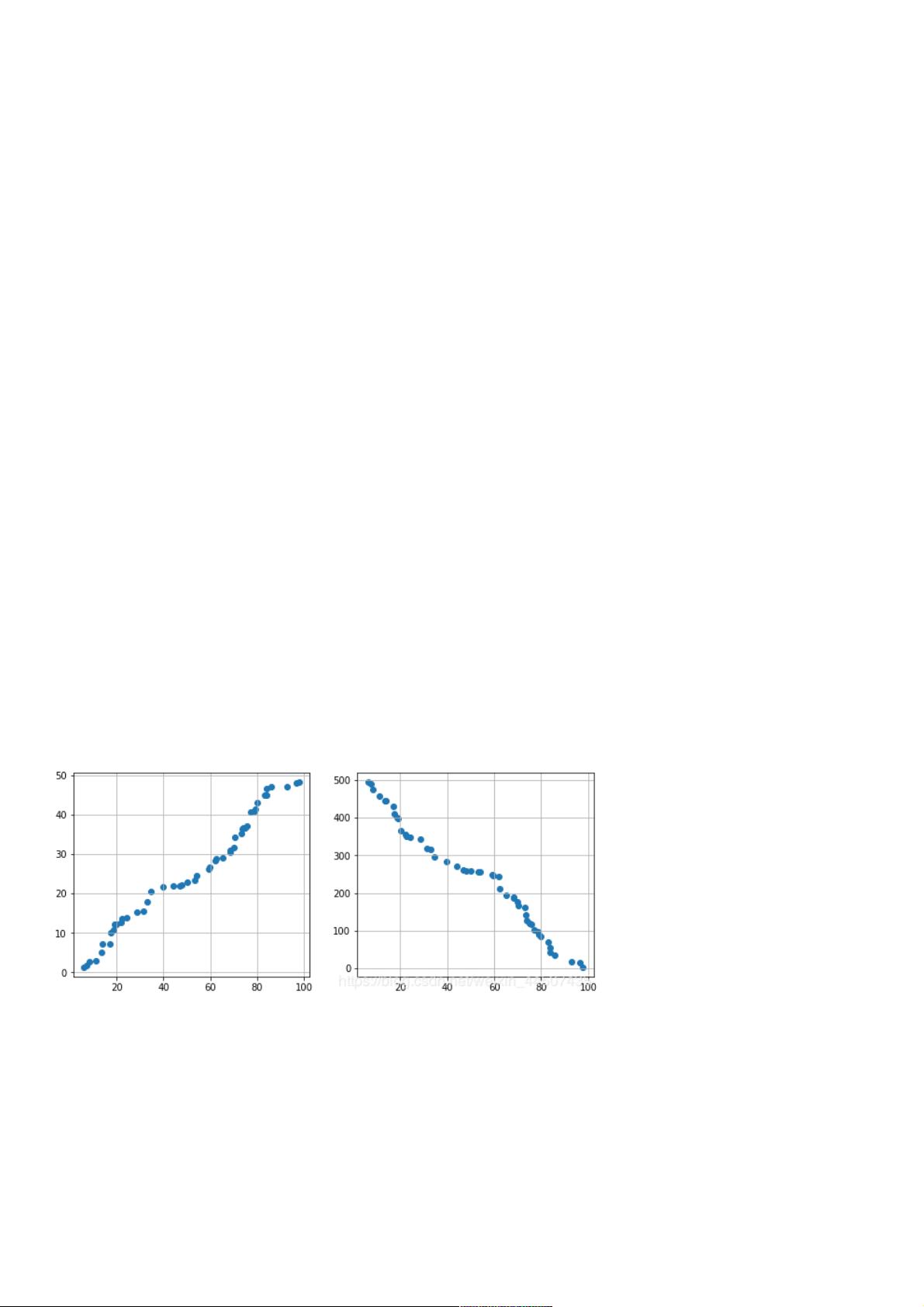
散点图是一种直观的方式来初步判断两个变量之间的相关性。通过绘制散点图,我们可以观察数据点的分布趋势,从而推断出它们之间是否存在正相关、负相关或无相关性。例如,正线性相关表现为数据点沿着对角线向上分布,而负线性相关则表现为数据点沿着对角线向下分布。此外,散点图矩阵可用于同时检查多个变量之间的相互关系,每一行和列对应一个变量,矩阵中的每个单元格都是对应变量的散点图。
2. Pearson相关系数(皮尔逊相关系数)
Pearson相关系数是衡量两个连续变量之间线性相关性的指标,其值范围在-1到1之间。1表示完全正相关,-1表示完全负相关,0表示没有线性相关。通过计算两个变量的协方差除以它们的标准差的乘积,可以得到Pearson相关系数。在Pandas中,可以使用`corr()`方法计算数据框中所有列对之间的Pearson相关系数。
3. Spearman秩相关系数(斯皮尔曼相关系数)
当数据存在非线性关系或存在异常值时,Spearman秩相关系数是一个更好的选择。它不考虑原始数值,而是基于变量的秩(数值的相对顺序)来计算相关性。Spearman相关系数同样介于-1和1之间,计算方式是两变量秩之差的平方和的六次根的负一倍。在Pandas中,可以使用`corrwith()`方法结合`rank()`方法计算Spearman相关系数。
相关性分析在数据分析中至关重要,因为它可以帮助我们理解不同特征之间的关系,进而支持模型构建、特征选择和业务洞察。例如,在机器学习中,高相关的特征可能导致模型过拟合,因此需要进行特征选择或特征工程来降低冗余。在业务场景中,了解产品销售与广告投入、用户行为与满意度等之间的相关性,有助于制定更有效的策略。
总结来说,本文提供的方法为数据科学家和分析师提供了一套基础工具,用于探究数据集中的特征关联,以便更好地理解数据的本质并作出基于数据的决策。在实际应用中,根据数据的特性和问题的需求,选择合适的相关性度量方法是至关重要的。
数据特征分析:相关性分析(数据特征分析:相关性分析(Pandas中的中的corr方法)方法)
文章目录文章目录1.图示初判两个变量之间的相关性(散点图)多变量之间的相关性(散点图矩阵)2.Pearson相关系数3.Spearman相
关系数
分析连续变量之间的线性相关程度的强弱
介绍如下几种方法:
图示初判
Pearson相关系数(皮尔逊相关系数)
Sperman秩相关系数(斯皮尔曼相关系数)
1.图示初判图示初判
拿到一组数据,可以先绘制散点图查看各数据之间的相关性:
两个变量之间的相关性(散点图)两个变量之间的相关性(散点图)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy import stats
%matplotlib inline
# 图示初判
# (1)变量之间的线性相关性
data1 = pd.Series(np.random.rand(50)*100).sort_values()
data2 = pd.Series(np.random.rand(50)*50).sort_values()
data3 = pd.Series(np.random.rand(50)*500).sort_values(ascending = False)
# 创建三个数据:data1为0-100的随机数并从小到大排列,data2为0-50的随机数并从小到大排列,data3为0-500的随机数并
从大到小排列,
fig = plt.figure(figsize = (10,4))
ax1 = fig.add_subplot(1,2,1)
ax1.scatter(data1, data2)
plt.grid()
# 正线性相关
ax2 = fig.add_subplot(1,2,2)
ax2.scatter(data1, data3)
plt.grid()
# 负线性相关
多变量之间的相关性(散点图矩阵)多变量之间的相关性(散点图矩阵)
# 图示初判
# (2)散点图矩阵初判多变量间关系
data = pd.DataFrame(np.random.randn(200,4)*100, columns = ['A','B','C','D'])
pd.plotting.scatter_matrix(data,figsize=(8,8),#注意Pandas中的用法与之前不同
c = 'k',
marker = '+',
diagonal='hist',
alpha = 0.8,
range_padding=0.1)
下载后可阅读完整内容,剩余2页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-04-30 上传
2024-10-28 上传
2023-04-24 上传
2023-06-11 上传

weixin_38639237
- 粉丝: 3
- 资源: 958
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现小波阈值去噪:Visushrink硬软算法对比
- 易语言实现画板图像缩放功能教程
- 大模型推荐系统: 优化算法与模型压缩技术
- Stancy: 静态文件驱动的简单RESTful API与前端框架集成
- 掌握Java全文搜索:深入Apache Lucene开源系统
- 19计应19田超的Python7-1试题整理
- 易语言实现多线程网络时间同步源码解析
- 人工智能大模型学习与实践指南
- 掌握Markdown:从基础到高级技巧解析
- JS-PizzaStore: JS应用程序模拟披萨递送服务
- CAMV开源XML编辑器:编辑、验证、设计及架构工具集
- 医学免疫学情景化自动生成考题系统
- 易语言实现多语言界面编程教程
- MATLAB实现16种回归算法在数据挖掘中的应用
- ***内容构建指南:深入HTML与LaTeX
- Python实现维基百科“历史上的今天”数据抓取教程
