
Pytorch 数据加载与数据预处理方式数据加载与数据预处理方式
今天小编就为大家分享一篇Pytorch 数据加载与数据预处理方式,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧
数据加载分为加载torchvision.datasets中的数据集以及加载自己使用的数据集两种情况。
torchvision.datasets中的数据集中的数据集
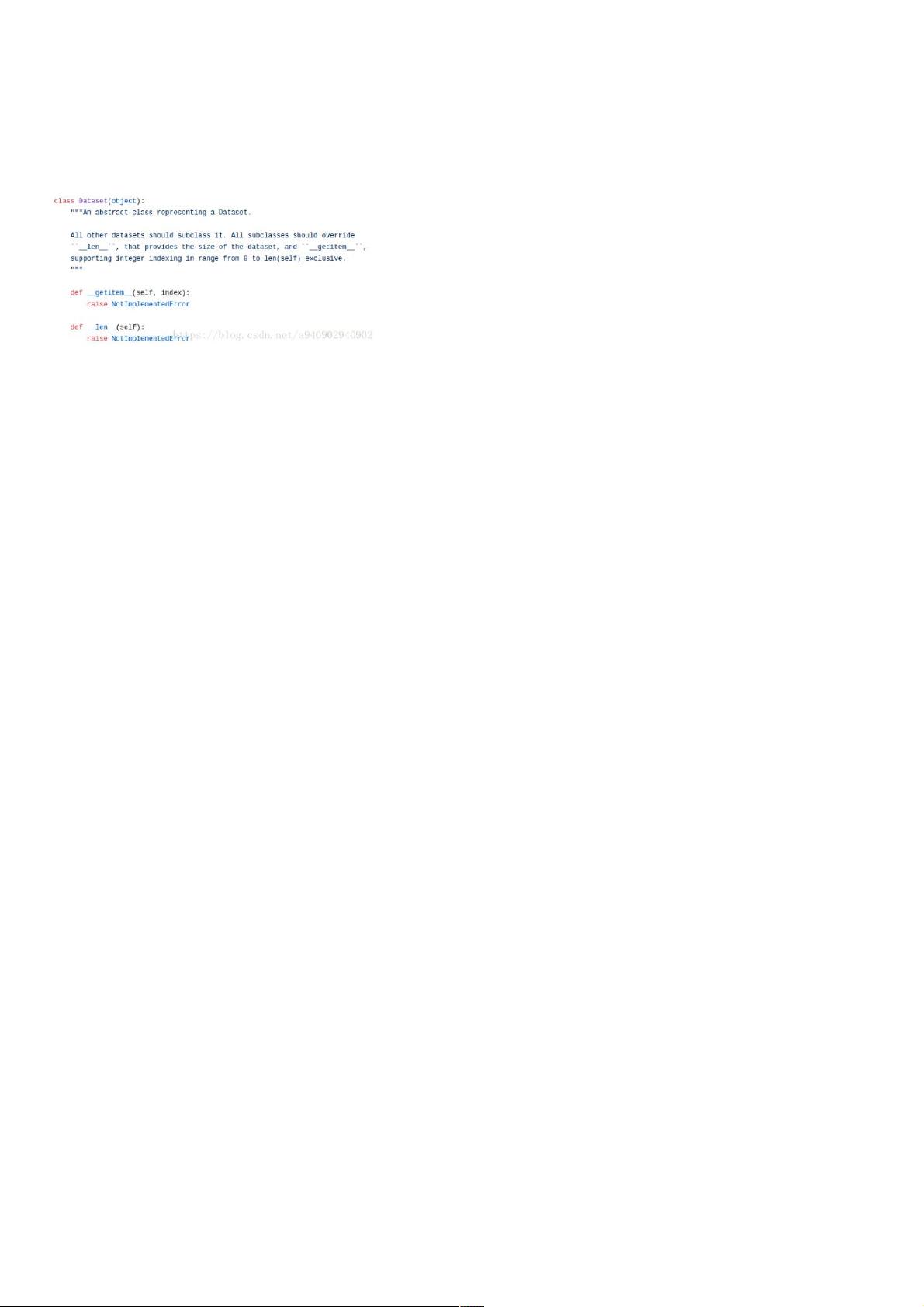
torchvision.datasets中自带MNIST,Imagenet-12,CIFAR等数据集,所有的数据集都是torch.utils.data.Dataset的子类,都包含 _ _ len _ (获取数据集长度)和 _ getItem _ _ (获取数
据集中每一项)两个子方法。
Dataset源码如上,可以看到其中包含了两个没有实现的子方法,之后所有的Dataet类都继承该类,并根据数据情况定制这两个子方法的具体实现。
因此当我们需要加载自己的数据集的时候也可以借鉴这种方法,只需要继承torch.utils.data.Dataset类并重写 init ,len,以及getitem这三个方法即可。这样组着的类可以直接作为参数传入到
torch.util.data.DataLoader中去。
以以CIFAR10为例为例 源码:源码:
class torchvision.datasets.CIFAR10(root, train=True, transform=None, target_transform=None, download=False)
root (string) – Root directory of dataset where directory cifar-10-batches-py exists or will be saved to if download is set to True.
train (bool, optional) – If True, creates dataset from training set, otherwise creates from test set.
transform (callable, optional) – A function/transform that takes in an PIL image and returns a transformed version. E.g, transforms.RandomCrop
target_transform (callable, optional) – A function/transform that takes in the target and transforms it.
download (bool, optional) – If true, downloads the dataset from the internet and puts it in root directory. If dataset is already downloaded, it is not downloaded again.
加载自己的数据集加载自己的数据集
对于torchvision.datasets中有两个不同的类,分别为DatasetFolder和ImageFolder,ImageFolder是继承自DatasetFolder。
下面我们通过源码来看一看folder文件中DatasetFolder和ImageFolder分别做了些什么
import torch.utils.data as data
from PIL import Image
import os
import os.path
def has_file_allowed_extension(filename, extensions): //检查输入是否是规定的扩展名
"""Checks if a file is an allowed extension.
Args:
filename (string): path to a file
Returns:
bool: True if the filename ends with a known image extension
"""
filename_lower = filename.lower()
return any(filename_lower.endswith(ext) for ext in extensions)
def find_classes(dir):
classes = [d for d in os.listdir(dir) if os.path.isdir(os.path.join(dir, d))] //获取root目录下所有的文件夹名称
classes.sort()
class_to_idx = {classes[i]: i for i in range(len(classes))} //生成类别名称与类别id的对应Dictionary
return classes, class_to_idx
def make_dataset(dir, class_to_idx, extensions):
images = []
dir = os.path.expanduser(dir)// 将~和~user转化为用户目录,对参数中出现~进行处理
for target in sorted(os.listdir(dir)):
d = os.path.join(dir, target)
if not os.path.isdir(d):
continue
for root, _, fnames in sorted(os.walk(d)): //os.work包含三个部分,root代表该目录路径 _代表该路径下的文件夹名称集合,fnames代表该路径下的文件名称集合
for fname in sorted(fnames):
if has_file_allowed_extension(fname, extensions):
path = os.path.join(root, fname)
item = (path, class_to_idx[target])
images.append(item) //生成(训练样本图像目录,训练样本所属类别)的元组
return images //返回上述元组的列表
class DatasetFolder(data.Dataset):
"""A generic data loader where the samples are arranged in this way: ::
root/class_x/xxx.ext
root/class_x/xxy.ext
root/class_x/xxz.ext
root/class_y/123.ext
root/class_y/nsdf3.ext
root/class_y/asd932_.ext
Args:
root (string): Root directory path.
loader (callable): A function to load a sample given its path.
extensions (list[string]): A list of allowed extensions.
transform (callable, optional): A function/transform that takes in
a sample and returns a transformed version.
E.g, ``transforms.RandomCrop`` for images.
target_transform (callable, optional): A function/transform that takes
in the target and transforms it.

weixin_38619967
- 粉丝: 5
- 资源: 928
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- RTL8188FU-Linux-v5.7.4.2-36687.20200602.tar(20765).gz
- c++校园超市商品信息管理系统课程设计说明书(含源代码) (2).pdf
- 建筑供配电系统相关课件.pptx
- 企业管理规章制度及管理模式.doc
- vb打开摄像头.doc
- 云计算-可信计算中认证协议改进方案.pdf
- [详细完整版]单片机编程4.ppt
- c语言常用算法.pdf
- c++经典程序代码大全.pdf
- 单片机数字时钟资料.doc
- 11项目管理前沿1.0.pptx
- 基于ssm的“魅力”繁峙宣传网站的设计与实现论文.doc
- 智慧交通综合解决方案.pptx
- 建筑防潮设计-PowerPointPresentati.pptx
- SPC统计过程控制程序.pptx
- SPC统计方法基础知识.pptx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0