CCTC 2016: 邵赛赛详解Spark与YARN协同优化
在CCTC 2016中国云计算技术大会上,Hortonworks的技术专家邵赛赛发表了一篇题为《Spark and YARN Better Together》的演讲,重点关注了如何更有效地将Apache Spark与Apache Hadoop YARN集成,以提升大数据处理性能。Spark on YARN是一种部署模式,它使得Spark应用程序能够在Hadoop YARN的资源管理框架下运行,从而实现资源的优化利用。
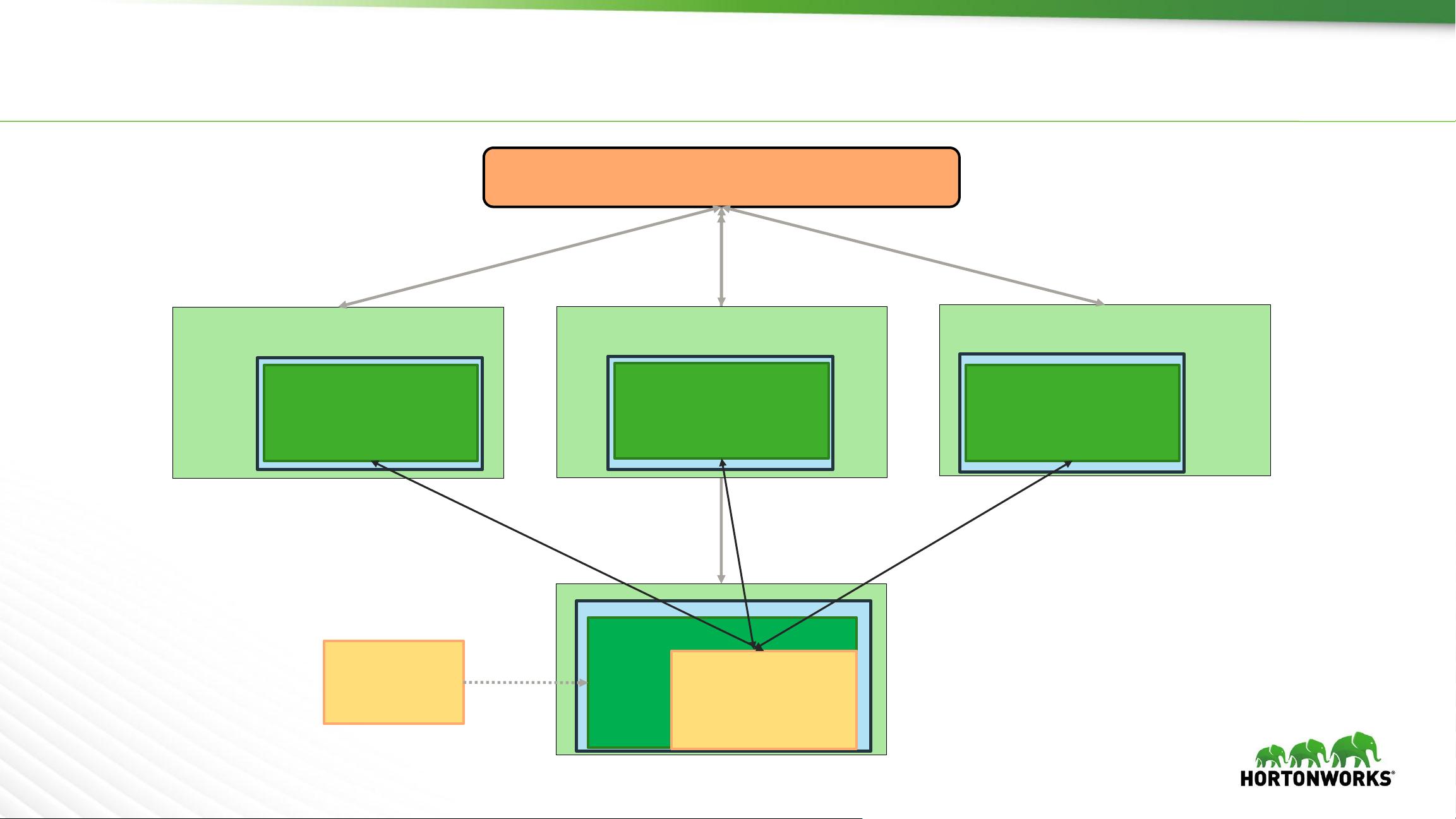
首先,Spark on YARN主要涉及两个关键组件:Cluster Manager( ResourceManager)和Executor。Cluster Manager负责协调和调度整个集群的资源,包括Driver和多个Executor实例。Driver是Spark应用的控制中心,负责任务的规划和协调,而Executor则执行实际的数据计算操作。在YARN的Client模式下,用户直接与ResourceManager交互;而在Cluster模式中,Spark通过Application Master (AM)与ResourceManager通信,以启动和管理Executor容器。
相比于传统的Cluster Managers,如Mesos或Standalone模式,YARN提供了几个优势。例如,Spark on YARN的应用必须提交到一个队列,这有助于资源分配的公平性。另外,Jars、files和archives可以通过分布式缓存分发,减少了网络I/O压力。此外,YARN引入了一个额外的Application Master,用于Spark的特定管理,确保了与Hadoop生态系统的良好整合。
演讲中还强调了在使用Spark on YARN时需要关注的问题,比如如何优化资源利用,如何确保任务的高效执行,以及如何处理分布式系统中的故障恢复。通过合理的配置和管理,可以充分利用YARN的弹性能力和Spark的计算能力,使得大规模数据处理更加高效。
邵赛赛的演讲深入探讨了如何通过YARN实现Spark的分布式部署,不仅阐述了两者结合的优势,还提供了实用的建议和最佳实践,对于理解如何在实际场景中优化Spark性能和扩展性具有很高的价值。对于任何在大数据处理领域使用Spark的工程师或者希望深入了解YARN的用户来说,这份演讲是一份宝贵的参考资料。
5
© Hortonworks Inc. 2011 – 2016. All Rights Reserved
NM
NM
NM
NM
Spark Running On YARN (Cluster Mode)
ResourceManager
Client
Container
Container
Container
Container
Executor
Executor
Executor
AM
Driver
剩余22页未读,继续阅读
993 浏览量
247 浏览量
398 浏览量
2023-06-13 上传
2023-06-13 上传
2023-05-16 上传
617 浏览量
255 浏览量
2016-05-17 上传

csdn_csdn__AI
- 粉丝: 2244
- 资源: 117
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高清艺术文字图标资源,PNG和ICO格式免费下载
- mui框架HTML5应用界面组件使用示例教程
- Vue.js开发利器:chrome-vue-devtools插件解析
- 掌握ElectronBrowserJS:打造跨平台电子应用
- 前端导师教程:构建与部署社交证明页面
- Java多线程与线程安全在断点续传中的实现
- 免Root一键卸载安卓预装应用教程
- 易语言实现高级表格滚动条完美控制技巧
- 超声波测距尺的源码实现
- 数据可视化与交互:构建易用的数据界面
- 实现Discourse外聘回复自动标记的简易插件
- 链表的头插法与尾插法实现及长度计算
- Playwright与Typescript及Mocha集成:自动化UI测试实践指南
- 128x128像素线性工具图标下载集合
- 易语言安装包程序增强版:智能导入与重复库过滤
- 利用AJAX与Spotify API在Google地图中探索世界音乐排行榜
