
defect rate of the bulbs. It could accomplish this task by testing each bulb,
but the cost would be substantial and would greatly increase the price per
bulb. An alternative approach is to select 1,000 bulbs from the daily
production of 500,000 bulbs and test each of the 1,000. The fraction of
defective bulbs in the 1,000 tested could be used to estimate the fraction
defective in the entire day’s production, provided that the 1,000 bulbs were
selected in the proper fashion. We will demonstrate in later chapters that
the fraction defective in the tested bulbs will probably be quite close to the
fraction defective for the entire day’s production of 500,000 bulbs.
2. Problem: Is there a relationship between quitting smoking and gaining
weight? To investigate the claim that people who quit smoking often
experience a subsequent weight gain, researchers selected a random
sample of 400 participants who had successfully participated in pro-
grams to quit smoking. The individuals were weighed at the beginning
of the program and again 1 year later. The average change in weight of
the participants was an increase of 5 pounds. The investigators con-
cluded that there was evidence that the claim was valid. We will develop
techniques in later chapters to assess when changes are truly significant
changes and not changes due to random chance.
3. Problem: What effect does nitrogen fertilizer have on wheat production?
For a study of the effects of nitrogen fertilizer on wheat production, a
total of 15 fields were available to the researcher. She randomly assigned
three fields to each of the five nitrogen rates under investigation. The
same variety of wheat was planted in all 15 fields. The fields were culti-
vated in the same manner until harvest, and the number of pounds of
wheat per acre was then recorded for each of the 15 fields. The experi-
menter wanted to determine the optimal level of nitrogen to apply to
any wheat field, but, of course, she was limited to running experiments
on a limited number of fields. After determining the amount of nitrogen
that yielded the largest production of wheat in the study fields, the
experimenter then concluded that similar results would hold for wheat
fields possessing characteristics somewhat the same as the study fields.
Is the experimenter justified in reaching this conclusion?
4. Problem: Determining public opinion toward a question, issue, product,
or candidate. Similar applications of statistics are brought to mind
by the frequent use of the New York Times/CBS News, Washington
Post /ABC News, CNN, Harris, and Gallup polls. How can these poll-
sters determine the opinions of more than 195 million Americans who
are of voting age? They certainly do not contact every potential voter in
the United States. Rather, they sample the opinions of a small number
of potential voters, perhaps as few as 1,500, to estimate the reaction of
every person of voting age in the country. The amazing result of this
process is that if the selection of the voters is done in an unbiased way
and voters are asked unambiguous, nonleading questions, the fraction
of those persons contacted who hold a particular opinion will closely
match the fraction in the total population holding that opinion at a
particular time. We will supply convincing supportive evidence of this
assertion in subsequent chapters.
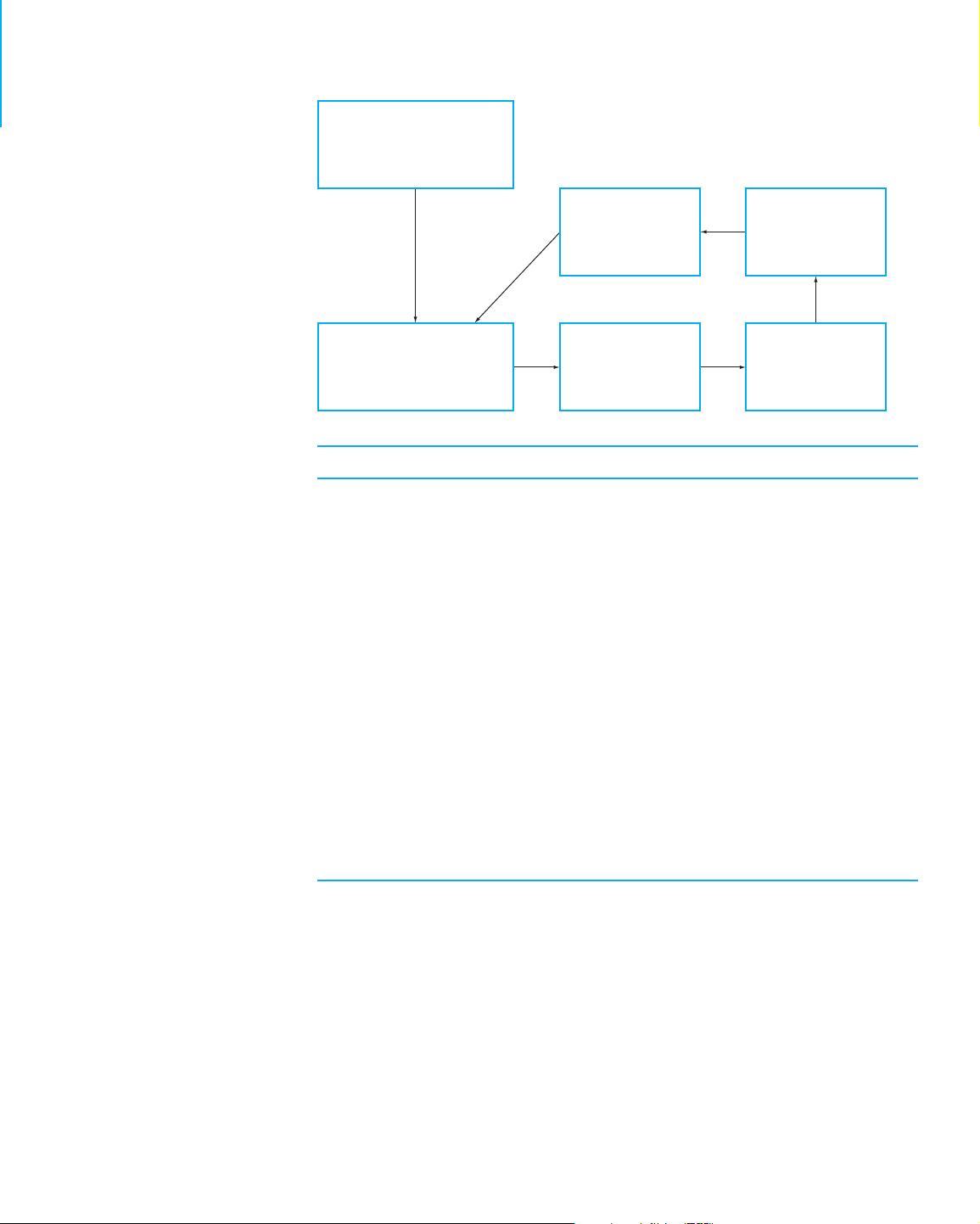
These problems illustrate the four-step process in Learning from Data. First,
there was a problem or question to be addressed. Next, for each problem a study
4 Chapter 1 Statistics and the Scientific Method
17582_01_ch01_p001-014.qxd 11/25/08 3:22 PM Page 4




 我的内容管理
收起
我的内容管理
收起
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助 







评论6