

.NET分布式编程——C#篇
今天,诸如企业编程、分布式编程、n 层和可扩展性等流行词汇出现在每一个产品的宣传中。
所以,要抓住.NET 中分布式开发的细微区别,就不能从字面上考虑这些术语,而应该考虑
这些特殊词汇的真实含义和上下文环境。而且,由于这本书主要是一本“操作指南”,所以,
清楚地理解为什么要分布应用程序以及如何设计一个分布式应用是非常重要的。在本章结尾
提出了五项原则,它们可以指导您在.NET 平台及其他平台上进行分布式开发。
最后,为了了解分布式编程的历史,本章回顾了原有的分布式开发模型,以及这些旧模型被
新模型取代的原因。如同您将要看到的,要解释清楚为什么微软创造出新的开发平台.NET
来取代 COM 需要花费很长时间。
1.1 分布式编程概述
什么是分布式编程?现在几乎很少有人再敢问这个问题。这个术语现在是如此普及,以至于
去询问它的含义会让人觉得非常尴尬。而其他人则认为没有必要再去询问这个术语的含义。
当我在按照惯例让学生定义分布式编程时,却很少能得到相同的答案。
分布式编程的特点是让几个物理上独立的组件作为一个单独的系统协同工作。在这里,“物
理上独立的组件”可能指多个 CPU,或者更普遍的是指网络中的多台计算机。分布式编程
可用于解决很多类型的问题,从预测天气到购买图书。作为分布式编程的核心,它做了如下
的假定:如果一台计算机能够在 5 秒钟内完成一项任务,那么 5 台计算机以并行的方式一起
工作时就能在 1 秒钟内完成一项任务。
当然,分布式编程不会如此简单。问题就在于“以并行方式协同工作”,很难让网络中的 5
台计算机高效协作。实际上,要达到如此高效,应用软件必须经过特殊设计。对此可以举一
个只有一匹马拉车的例子。马是强大的动物,但是从力量与重量之比来说,蚂蚁要比马强壮
很多倍(这里仅假设强壮 10 倍)。这样,如果聚集了与一匹马质量相同的一堆蚂蚁并利用它
们来工作,则可以拉动 10 倍于一匹马所能拉的物质。这是一个非常好的分布负载示例。这
种计算是合理的,但让数百万的蚂蚁身上都套着细小的缰绳去拉动货物却是不现实的。
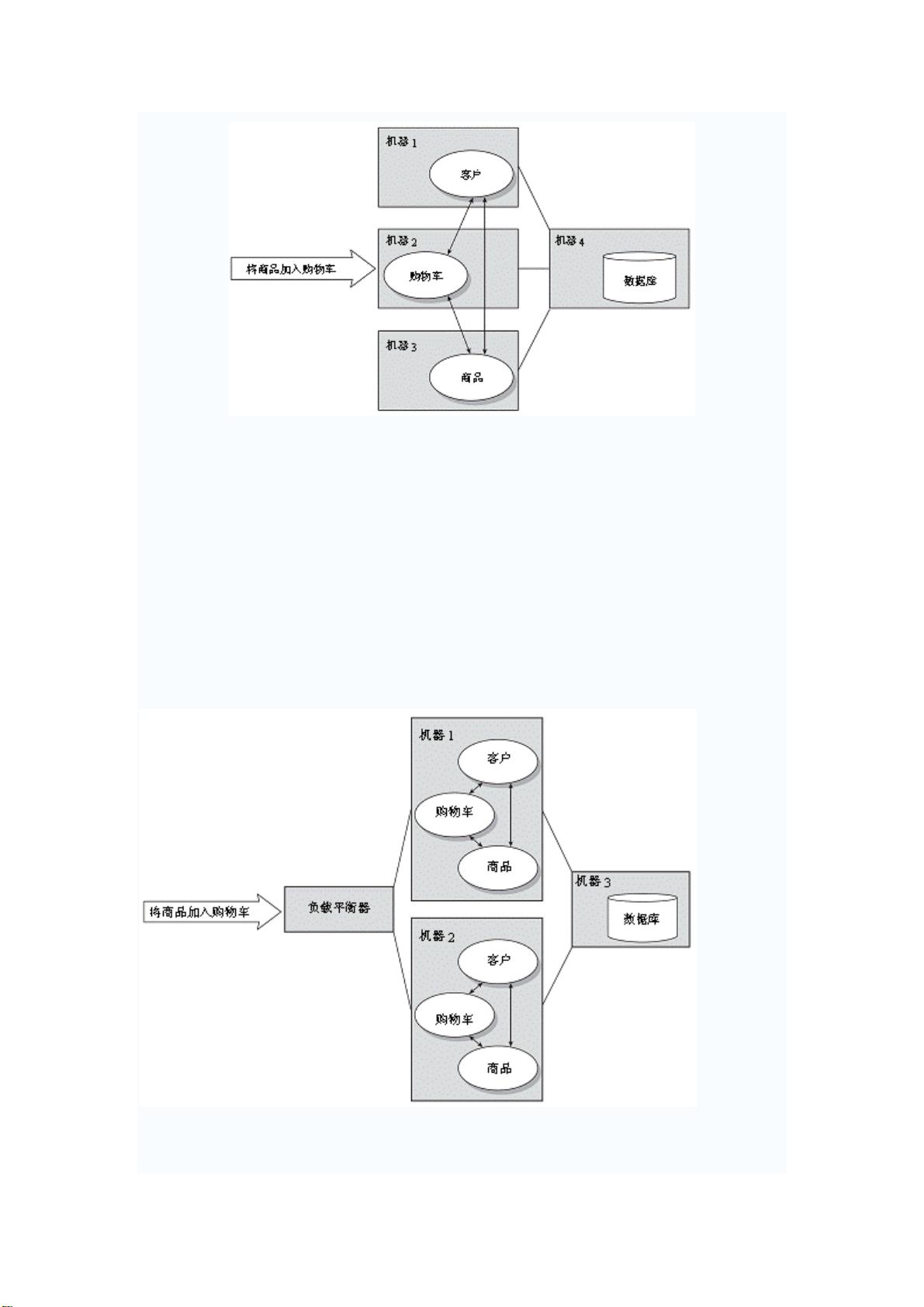
剩余153页未读,继续阅读

tlm0911
- 粉丝: 4
- 资源: 8
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- 27页智慧街道信息化建设综合解决方案.pptx
- 计算机二级Ms-Office选择题汇总.doc
- 单链表的插入和删除实验报告 (2).docx
- 单链表的插入和删除实验报告.pdf
- 物联网智能终端项目设备管理方案.pdf
- 如何打造品牌的模式.doc
- 样式控制与页面布局.pdf
- 武汉理工Java实验报告(二).docx
- 2021线上新品消费趋势报告.pdf
- 第3章 Matlab中的矩阵及其运算.docx
- 基于Web的人力资源管理系统的必要性和可行性.doc
- 基于一阶倒立摆的matlab仿真实验.doc
- 速运公司物流管理模式研究教材
- 大数据与管理.pptx
- 单片机课程设计之步进电机.doc
- 大数据与数据挖掘.pptx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论2