

1
Deep Facial Expression Recognition: A Survey
Shan Li and Weihong Deng
∗
, Member, IEEE
Abstract—With the transition of facial expression recognition (FER) from laboratory-controlled to challenging in-the-wild conditions
and the recent success of deep learning techniques in various fields, deep neural networks have increasingly been leveraged to learn
discriminative representations for automatic FER. Recent deep FER systems generally focus on two important issues: overfitting
caused by a lack of sufficient training data and expression-unrelated variations, such as illumination, head pose and identity bias. In this
paper, we provide a comprehensive survey on deep FER, including datasets and algorithms that provide insights into these intrinsic
problems. First, we introduce the available datasets that are widely used in the literature and provide accepted data selection and
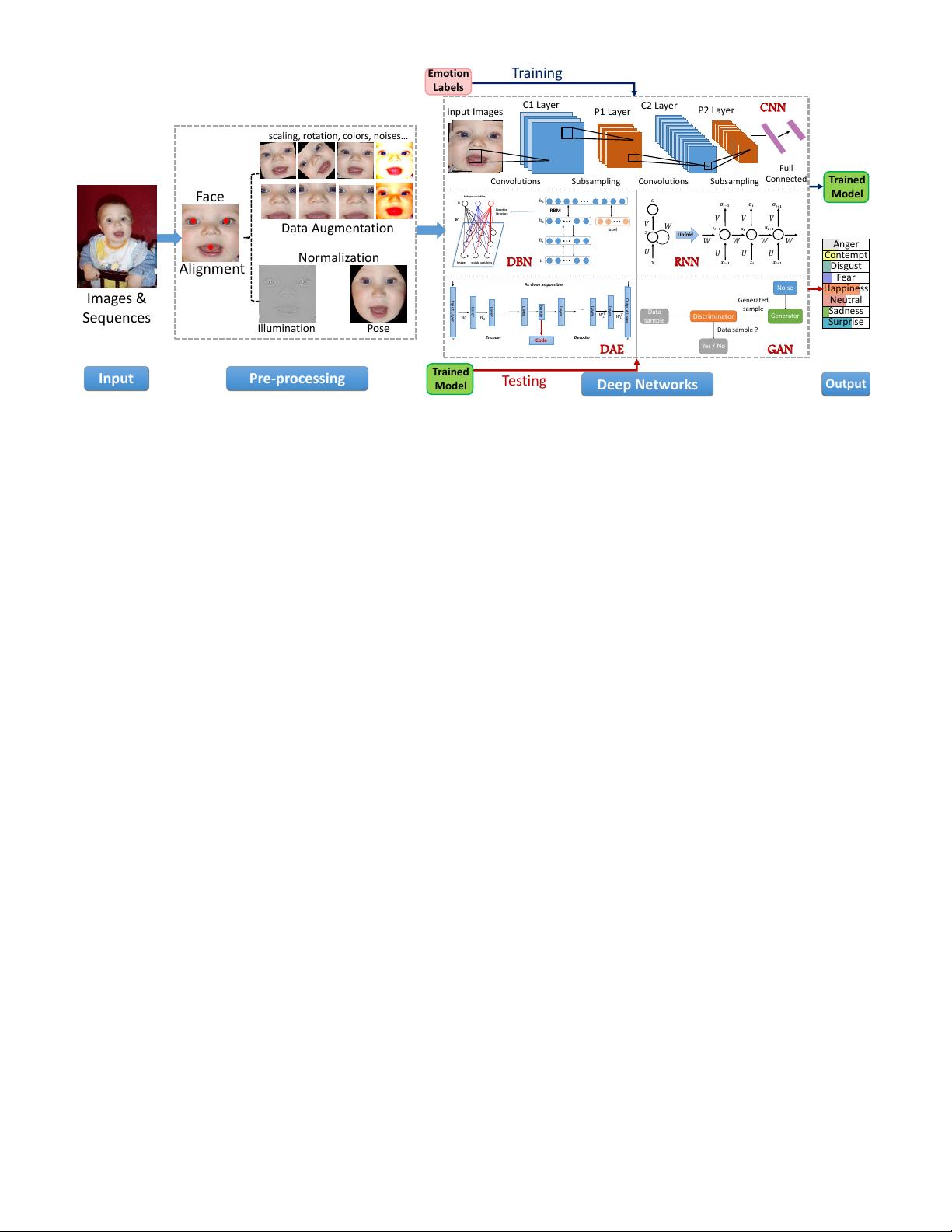
evaluation principles for these datasets. We then describe the standard pipeline of a deep FER system with the related background
knowledge and suggestions of applicable implementations for each stage. For the state of the art in deep FER, we review existing
novel deep neural networks and related training strategies that are designed for FER based on both static images and dynamic image
sequences, and discuss their advantages and limitations. Competitive performances on widely used benchmarks are also summarized
in this section. We then extend our survey to additional related issues and application scenarios. Finally, we review the remaining
challenges and corresponding opportunities in this field as well as future directions for the design of robust deep FER systems.
Index Terms—Facial Expressions Recognition, Facial expression datasets, Affect, Deep Learning, Survey.
F
1 INTRODUCTION
F
ACIAL expression is one of the most powerful, natural and
universal signals for human beings to convey their emotional
states and intentions [1], [2]. Numerous studies have been con-
ducted on automatic facial expression analysis because of its
practical importance in sociable robotics, medical treatment, driver
fatigue surveillance, and many other human-computer interaction
systems. In the field of computer vision and machine learning,
various facial expression recognition (FER) systems have been
explored to encode expression information from facial represen-
tations. As early as the twentieth century, Ekman and Friesen [3]
defined six basic emotions based on cross-culture study [4], which
indicated that humans perceive certain basic emotions in the same
way regardless of culture. These prototypical facial expressions
are anger, disgust, fear, happiness, sadness, and surprise. Contempt
was subsequently added as one of the basic emotions [5]. Recently,
advanced research on neuroscience and psychology argued that the
model of six basic emotions are culture-specific and not universal
[6].
Although the affect model based on basic emotions is limited
in the ability to represent the complexity and subtlety of our
daily affective displays [7], [8], [9], and other emotion description
models, such as the Facial Action Coding System (FACS) [10] and
the continuous model using affect dimensions [11], are considered
to represent a wider range of emotions, the categorical model
that describes emotions in terms of discrete basic emotions is
still the most popular perspective for FER, due to its pioneering
investigations along with the direct and intuitive definition of facial
expressions. And in this survey, we will limit our discussion on
FER based on the categorical model.
FER systems can be divided into two main categories accord-
ing to the feature representations: static image FER and dynamic
sequence FER. In static-based methods [12], [13], [14], the feature
• The authors are with the Pattern Recognition and Intelligent System Lab-
oratory, School of Information and Communication Engineering, Beijing
University of Posts and Telecommunications, Beijing, 100876, China.
E-mail:{ls1995, whdeng}@bupt.edu.cn.
representation is encoded with only spatial information from the
current single image, whereas dynamic-based methods [15], [16],
[17] consider the temporal relation among contiguous frames in
the input facial expression sequence. Based on these two vision-
based methods, other modalities, such as audio and physiological
channels, have also been used in multimodal systems [18] to assist
the recognition of expression.
The majority of the traditional methods have used handcrafted
features or shallow learning (e.g., local binary patterns (LBP) [12],
LBP on three orthogonal planes (LBP-TOP) [15], non-negative
matrix factorization (NMF) [19] and sparse learning [20]) for FER.
However, since 2013, emotion recognition competitions such as
FER2013 [21] and Emotion Recognition in the Wild (EmotiW)
[22], [23], [24] have collected relatively sufficient training data
from challenging real-world scenarios, which implicitly promote
the transition of FER from lab-controlled to in-the-wild settings. In
the meanwhile, due to the dramatically increased chip processing
abilities (e.g., GPU units) and well-designed network architecture,
studies in various fields have begun to transfer to deep learning
methods, which have achieved the state-of-the-art recognition ac-
curacy and exceeded previous results by a large margin (e.g., [25],
[26], [27], [28]). Likewise, given with more effective training data
of facial expression, deep learning techniques have increasingly
been implemented to handle the challenging factors for emotion
recognition in the wild. Figure 1 illustrates this evolution on FER
in the aspect of algorithms and datasets.
Exhaustive surveys on automatic expression analysis have
been published in recent years [7], [8], [29], [30]. These surveys
have established a set of standard algorithmic pipelines for FER.
However, they focus on traditional methods, and deep learning
has rarely been reviewed. Very recently, FER based on deep
learning has been surveyed in [31], which is a brief review without
introductions on FER datasets and technical details on deep FER.
Therefore, in this paper, we make a systematic research on deep
learning for FER tasks based on both static images and videos
(image sequences). We aim to give a newcomer to this filed an
overview of the systematic framework and prime skills for deep
arXiv:1804.08348v2 [cs.CV] 22 Oct 2018



剩余24页未读,继续阅读

yep。
- 粉丝: 19
- 资源: 2
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- stc12c5a60s2 例程
- Android通过全局变量传递数据
- c++校园超市商品信息管理系统课程设计说明书(含源代码) (2).pdf
- 建筑供配电系统相关课件.pptx
- 企业管理规章制度及管理模式.doc
- vb打开摄像头.doc
- 云计算-可信计算中认证协议改进方案.pdf
- [详细完整版]单片机编程4.ppt
- c语言常用算法.pdf
- c++经典程序代码大全.pdf
- 单片机数字时钟资料.doc
- 11项目管理前沿1.0.pptx
- 基于ssm的“魅力”繁峙宣传网站的设计与实现论文.doc
- 智慧交通综合解决方案.pptx
- 建筑防潮设计-PowerPointPresentati.pptx
- SPC统计过程控制程序.pptx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0