

End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF
Xuezhe Ma and Eduard Hovy
Language Technologies Institute
Carnegie Mellon University
Pittsburgh, PA 15213, USA
xuezhem@cs.cmu.edu, ehovy@cmu.edu
Abstract
State-of-the-art sequence labeling systems
traditionally require large amounts of task-
specific knowledge in the form of hand-
crafted features and data pre-processing.
In this paper, we introduce a novel neu-
tral network architecture that benefits from
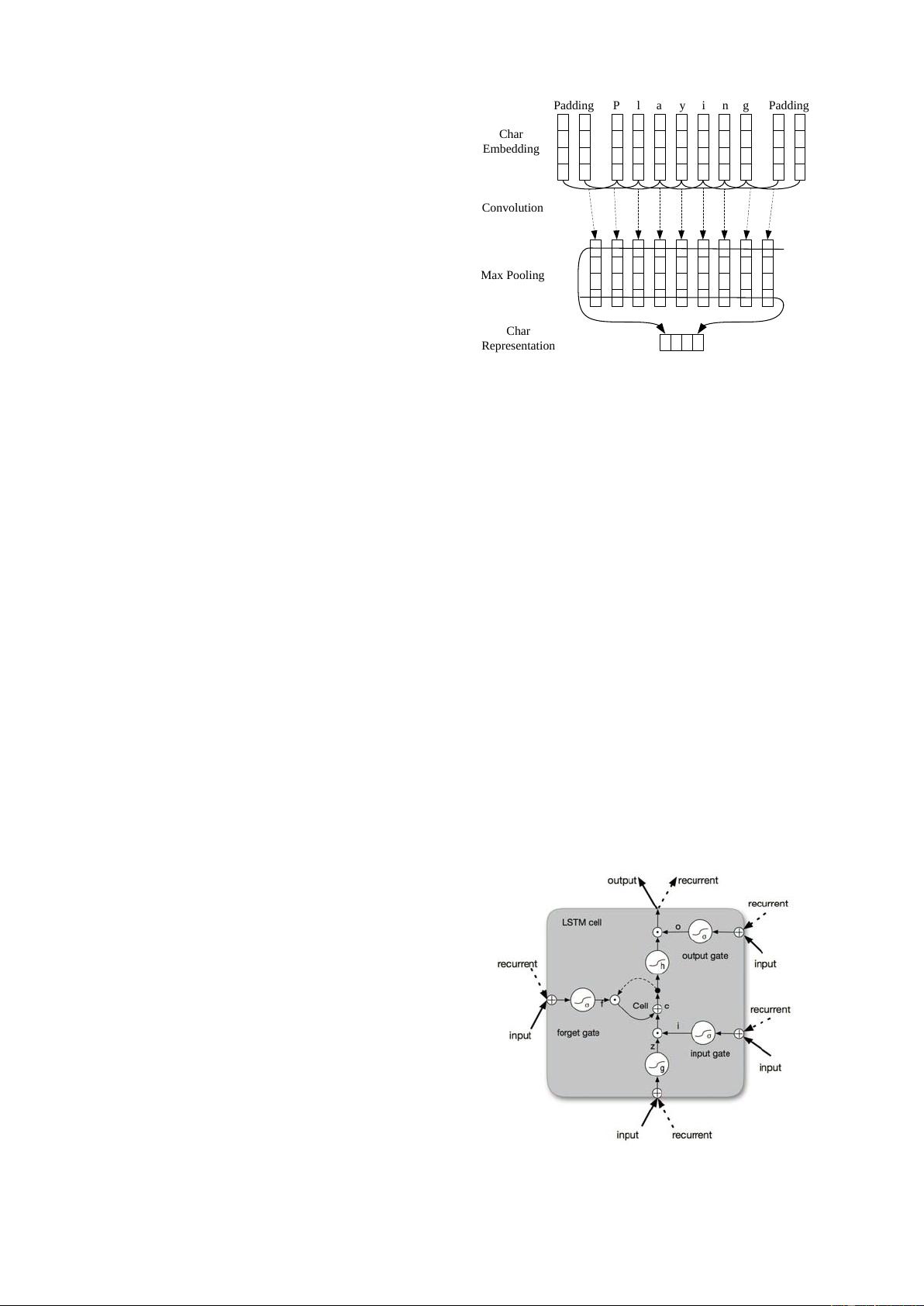
both word- and character-level representa-
tions automatically, by using combination
of bidirectional LSTM, CNN and CRF.
Our system is truly end-to-end, requir-
ing no feature engineering or data pre-
processing, thus making it applicable to
a wide range of sequence labeling tasks.
We evaluate our system on two data sets
for two sequence labeling tasks — Penn
Treebank WSJ corpus for part-of-speech
(POS) tagging and CoNLL 2003 cor-
pus for named entity recognition (NER).
We obtain state-of-the-art performance on
both datasets — 97.55% accuracy for POS
tagging and 91.21% F1 for NER.
1 Introduction
Linguistic sequence labeling, such as part-of-
speech (POS) tagging and named entity recogni-
tion (NER), is one of the first stages in deep lan-
guage understanding and its importance has been
well recognized in the natural language processing
community. Natural language processing (NLP)
systems, like syntactic parsing (Nivre and Scholz,
2004; McDonald et al., 2005; Koo and Collins,
2010; Ma and Zhao, 2012a; Ma and Zhao, 2012b;
Chen and Manning, 2014; Ma and Hovy, 2015)
and entity coreference resolution (Ng, 2010; Ma
et al., 2016), are becoming more sophisticated,
in part because of utilizing output information of
POS tagging or NER systems.
Most traditional high performance sequence la-
beling models are linear statistical models, includ-
ing Hidden Markov Models (HMM) and Condi-
tional Random Fields (CRF) (Ratinov and Roth,
2009; Passos et al., 2014; Luo et al., 2015), which
rely heavily on hand-crafted features and task-
specific resources. For example, English POS tag-
gers benefit from carefully designed word spelling
features; orthographic features and external re-
sources such as gazetteers are widely used in NER.
However, such task-specific knowledge is costly
to develop (Ma and Xia, 2014), making sequence
labeling models difficult to adapt to new tasks or
new domains.
In the past few years, non-linear neural net-
works with as input distributed word representa-
tions, also known as word embeddings, have been
broadly applied to NLP problems with great suc-
cess. Collobert et al. (2011) proposed a simple but
effective feed-forward neutral network that inde-
pendently classifies labels for each word by us-
ing contexts within a window with fixed size. Re-
cently, recurrent neural networks (RNN) (Goller
and Kuchler, 1996), together with its variants such
as long-short term memory (LSTM) (Hochreiter
and Schmidhuber, 1997; Gers et al., 2000) and
gated recurrent unit (GRU) (Cho et al., 2014),
have shown great success in modeling sequential
data. Several RNN-based neural network mod-
els have been proposed to solve sequence labeling
tasks like speech recognition (Graves et al., 2013),
POS tagging (Huang et al., 2015) and NER (Chiu
and Nichols, 2015; Hu et al., 2016), achieving
competitive performance against traditional mod-
els. However, even systems that have utilized dis-
tributed representations as inputs have used these
to augment, rather than replace, hand-crafted fea-
tures (e.g. word spelling and capitalization pat-
terns). Their performance drops rapidly when the
models solely depend on neural embeddings.
arXiv:1603.01354v5 [cs.LG] 29 May 2016

剩余11页未读,继续阅读

beaujor
- 粉丝: 5
- 资源: 12
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- RTL8188FU-Linux-v5.7.4.2-36687.20200602.tar(20765).gz
- c++校园超市商品信息管理系统课程设计说明书(含源代码) (2).pdf
- 建筑供配电系统相关课件.pptx
- 企业管理规章制度及管理模式.doc
- vb打开摄像头.doc
- 云计算-可信计算中认证协议改进方案.pdf
- [详细完整版]单片机编程4.ppt
- c语言常用算法.pdf
- c++经典程序代码大全.pdf
- 单片机数字时钟资料.doc
- 11项目管理前沿1.0.pptx
- 基于ssm的“魅力”繁峙宣传网站的设计与实现论文.doc
- 智慧交通综合解决方案.pptx
- 建筑防潮设计-PowerPointPresentati.pptx
- SPC统计过程控制程序.pptx
- SPC统计方法基础知识.pptx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0