MapReduce:海量数据处理的并行编程模型与应用
需积分: 12 199 浏览量
更新于2024-07-25
收藏 586KB PDF 举报
Hadoop MapReduce编程模型是一种高效处理大规模数据集的并行计算框架,最初由Google在2004年提出,用于解决如统计Google网页中单词频率这样海量数据处理的问题。当传统的单机处理方式无法胜任时,MapReduce通过将大任务分解为一系列可并行执行的小任务(Map和Reduce阶段),极大地提高了计算效率。
1. **问题与目标**:
MapReduce主要解决的问题是如何在分布式环境中进行数据处理,尤其是当数据量巨大,单机难以承受时。它的目标是实现对大数据集的快速、可靠且容错的处理,例如在Google的案例中,通过并行计算将网页索引的构建时间从4个月缩短至3小时。
2. **理论基础**:
MapReduce的设计灵感来源于函数式编程,特别是其特点如:不可变数据(避免数据修改),运算顺序无关性,以及函数作为参数(高阶函数)。这些特性使得MapReduce中的函数可以在数据上“映射”(Map)和“折叠”(Reduce)操作,实现了数据的局部处理和全局汇总。
3. **编程模型**:
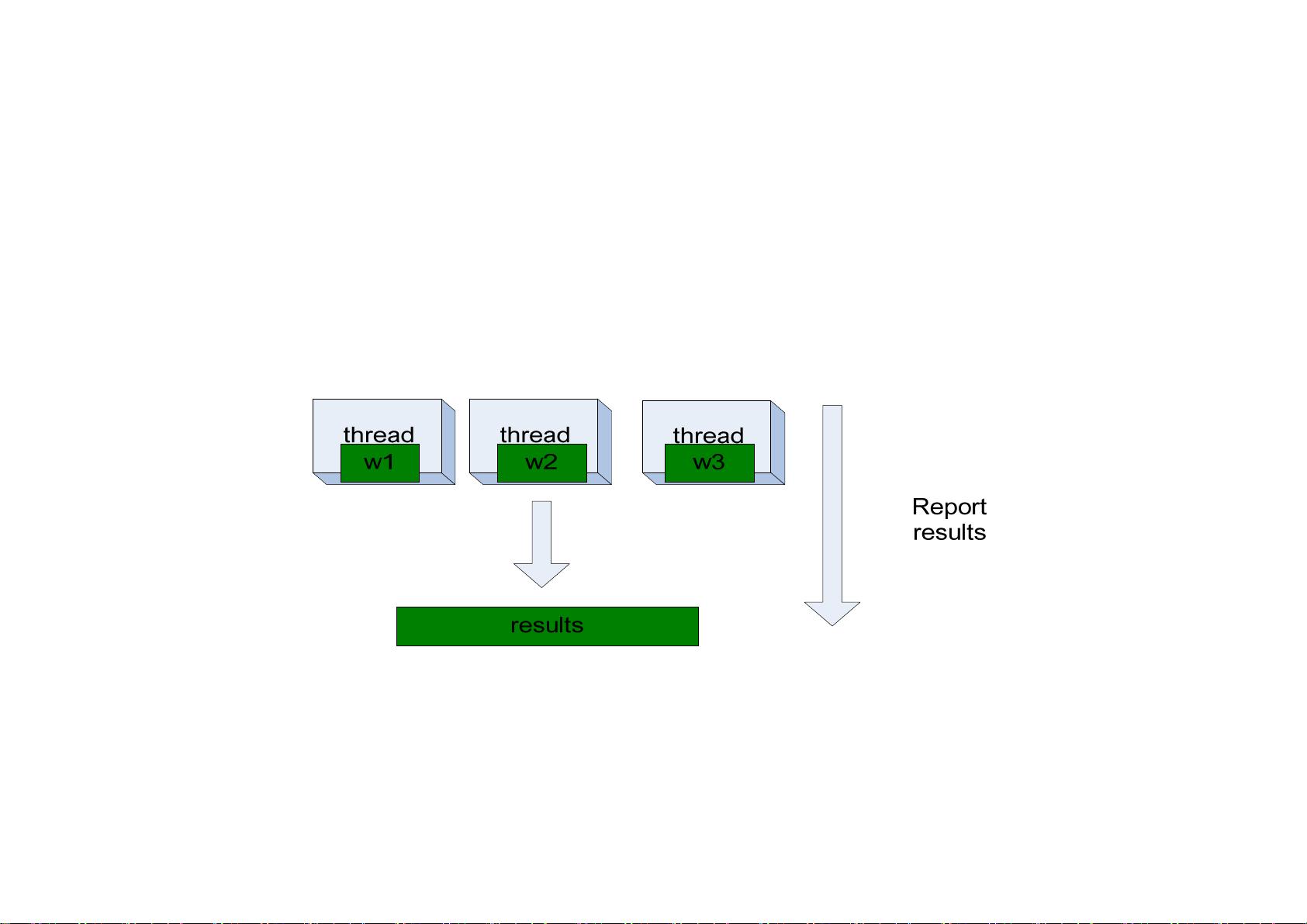
- **Map阶段**:每个节点接收一部分数据,执行自定义的Mapper函数,对数据进行预处理,生成键值对(key-value pairs)。Mapper函数通常是简单但重复的操作,例如提取单词并计数。
- **Shuffle阶段**:Mapper生成的中间结果被分区并传递到Reducer节点,通过网络进行数据交换,确保相同键的值被聚集在一起。
- **Reduce阶段**:Reducer接收到键的所有值,应用自定义的Reducer函数进行聚合操作,如求和、平均等,生成最终结果。
4. **实现与评测**:
实现MapReduce需要考虑多个因素,如数据划分、线程调度、错误处理(通过容错机制如Chukwa或Hadoop的HDFS提供备份)以及任务完成的监控。评测通常关注性能指标,如吞吐量、延迟和资源利用率。
5. **未来发展趋势**:
随着大数据和云计算的发展,MapReduce继续演进以适应新的需求。这包括优化分布式内存计算、引入实时处理能力、支持流处理和机器学习任务等。同时,新的编程框架如Apache Spark和Apache Flink也在一定程度上挑战了MapReduce的地位,提供了更灵活的数据处理方式。
6. **实际应用示例**:
MapReduce广泛应用于各种场景,比如文本分析(单词计数)、数据库查询(倒排索引)和排序,以及简单的数据挖掘任务。它展示了如何利用海量输入数据和集群环境,通过函数式编程范式简化程序设计,提高处理效率。
Hadoop MapReduce编程模型是一种强大的工具,它将复杂的大规模数据处理分解为易于管理的并行任务,实现了高性能的分布式数据处理,对于现代IT行业中的数据处理和分析至关重要。随着技术的进步,MapReduce将继续影响着数据处理的未来。


2022-11-21 上传
2018-09-12 上传
2013-09-08 上传
2023-05-10 上传
2023-05-10 上传
2024-10-29 上传
2022-11-02 上传
点击了解资源详情
点击了解资源详情

gaofei8704
- 粉丝: 3
- 资源: 8
 我的内容管理
展开
我的内容管理
展开







最新资源
- Resume-quiz
- 管理系统系列--友家民宿项目(后台管理系统,pc端网站,微信小程序).zip
- WaveEV波形查看工具
- Streamify:简单的应用程序以流式传输文件夹
- example-fhir-service
- vanilla-slider:纯JS编写的简单滑块
- braintree-go:Braintree的Go客户端库
- tapis-java:德州高级计算中心API
- 16路智能舵机控制板,手机控制(上位机、手机安卓APP及说明书)-电路方案
- belen-grunt-file:这是自动完成的咕unt声
- 管理系统系列--悠歌网络合作商家管理系统.zip
- post-app
- zetta-controller
- simple-validator:Simple Validator是Dart开发的DartFlutter的文本验证库。
- 管理系统系列--在线教育培训管理系统。包括教学视频,题库,学员,购买,学习进度,班级管理等.zip
- rails-blog
