BM算法详解:精确匹配与启发式规则
BM算法,全称为Boyer-Moore算法,是一种高效的精确字符串匹配算法,其主要特点是采用了从右向左的比较方式,并结合Bad-Character和Good-Suffix两条启发式规则,以提高匹配效率。该算法不同于KMP算法,后者是基于前缀函数的思想。
算法的基本流程如下:
1. 将文本串T和模式串P进行左对齐,初始状态下,两者相对位置不变,仅比较当前位置的字符是否匹配。
2. 从右向左进行字符比较。如果发现不匹配,BM算法会利用Bad-Character和Good-Suffix规则来确定模式串P的移动步长。
Bad-Character规则:
当遇到不匹配的字符时,如果这个字符在模式串P中不存在,意味着从当前字符起的整个子串与P不可能匹配,所以可以直接跳过该字符后的长度等于模式串长度的部分,即Jump(x) = m,这里的m是模式串的长度,x是不匹配的字符。
Good-Suffix规则:
如果不匹配字符在模式串P中存在,算法会查找该字符之前已经匹配的部分,也就是Good-Suffix。找到最长的Good-Suffix,根据它的右边界位置Last(x),计算出一个跳跃距离,即Jump(x) = max(x) - Last(x) + 1。这个规则利用了已知的匹配信息,避免了无谓的重复比较。
举例说明:
在图示中,从右向左的第一个不匹配字符是E,它是Bad-Character,因为E不在模式串P中。根据Bad-Character规则,P可以跳过E直接比较下一个字符。如果E在P中出现过,比如图中的斜体B,算法会根据E的位置进行调整。
总结,BM算法通过巧妙地利用已知信息,减少了不必要的字符比较,提高了搜索速度。在实际应用中,如文本搜索、数据库查询等场景,BM算法由于其高效性而被广泛采用。然而,它并非总能比KMP算法更快,具体取决于输入数据的特点和环境条件。了解并掌握这两种算法,可以帮助我们根据实际情况选择最适合的匹配策略。
BM 算法详细图解 编著:WeiSteve@Yeah.net [Weisteven]
2010/10/29 于 HoHai University 4216
BM 算法详细图解
BM 算法(全称 Boyer-Moore Algorithm)是一种精确字符串匹配算法(只是一个
启发式的字符串搜索算法)。
BM 算法不同于 KMP 算法,采用从右向左比较的方法,同时引入了两种启发式 Jump
规则,即 Bad-Character 和 Good-Suffix,来决定模板向右移动的步长。
BM 算法的基本流程:
文本串 T(待匹配的字符串,长度 n),模式串为 P(用于去匹配的字符串模板,
长度设为 m)。
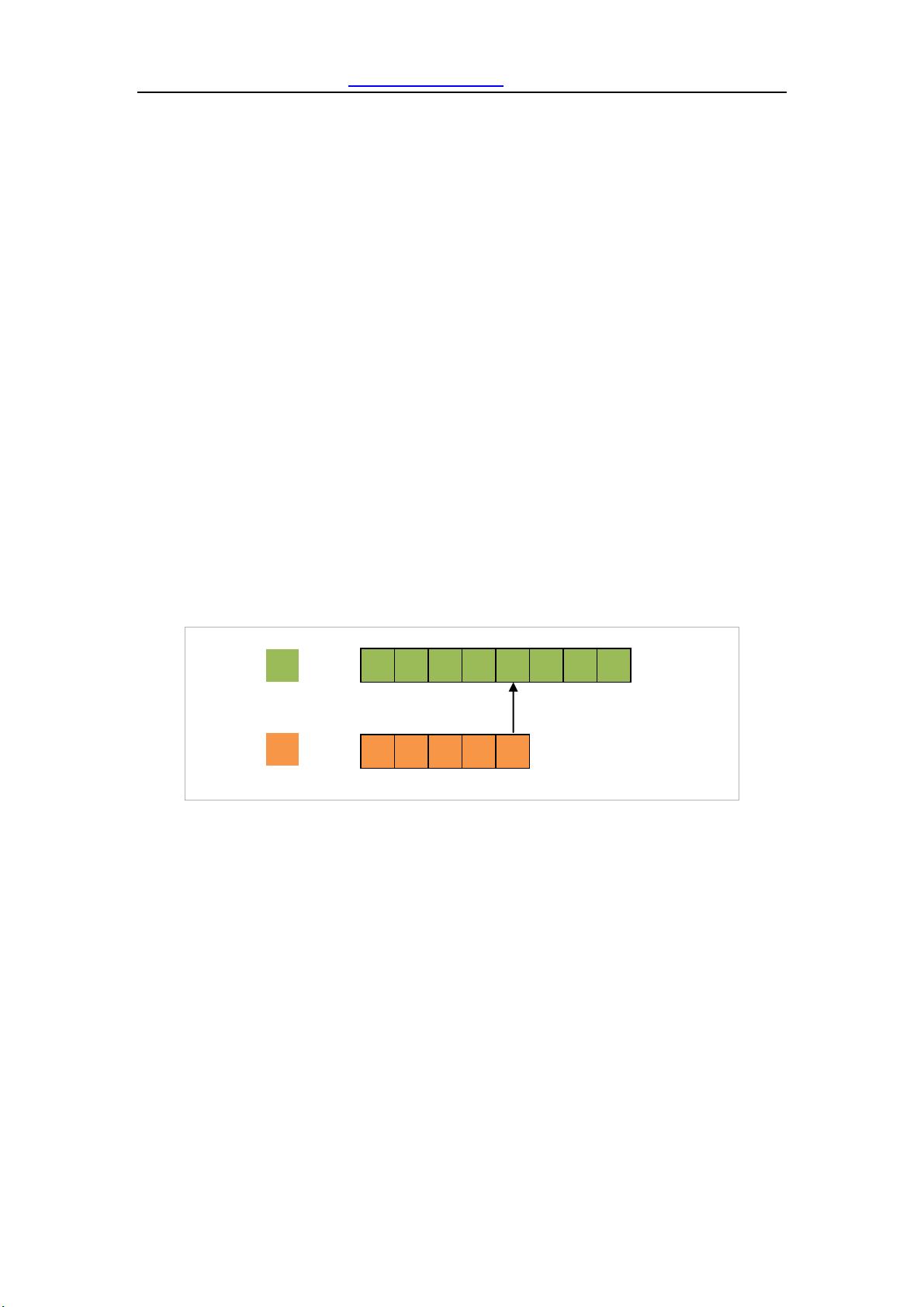
首先将 T 与 P 进行左对齐,然后进行从右向左比较(此时不移动模板和文本的相
对位置,仅仅比较对齐位置上面是否相同,方向是右向左),如下图所示:
若是某趟比较不匹配时,BM 算法就采用两条启发式规则,即前面提到的
Bad-Character 和 Good-Suffix,来计算模式串 P 向右移动的步长,直到整个匹配
过程的结束。
下面,来详细介绍一下 Bad-Character 和 Good-Suffix:
请看下图:
T
P
A
B
C
E
C
A
B
E
A
B
C
A
B
下载后可阅读完整内容,剩余6页未读,立即下载
1614 浏览量
2037 浏览量
759 浏览量
402 浏览量
201 浏览量
2022-09-19 上传
2022-09-24 上传

kei_lin
- 粉丝: 8
- 资源: 14
 我的内容管理
展开
我的内容管理
展开







最新资源
- PyDeduplication:大多数只是重复数据删除
- restmachine:用于PHP的Web机器实现
- torch_sparse-0.6.4-cp38-cp38-win_amd64whl.zip
- EMD matlab相关工具(包含EEMD,CEEMDAN)
- matlab的slam代码-ORB_SLAM2_error_analysis:ORB_SLAM2_error_analysis
- jdk1.8安装包:jdk-8u161-windows-x64
- head-in-the-clouds:与提供商无关的云供应和Docker编排
- init:环境初始化脚本
- 英雄
- torch_cluster-1.5.6-cp36-cp36m-win_amd64whl.zip
- 关于VSCode如何安装调试C/C++代码的傻瓜安装
- 导航菜单下拉
- Bird
- raspberry-pi-compute-module-base-board:Raspberry Pi计算模块的基板
- 晶格角
- thrift-0.13.0.zip
