Python实战:电影推荐的亲和性分析与Apriori算法应用
版权申诉
本章深入探讨Python数据挖掘项目开发实战中的一个重要课题——利用亲和性分析方法来推荐电影。亲和性分析,又称关联规则挖掘,是一种在商业领域广泛应用的技术,最初源于购物篮分析,旨在识别出物品之间的频繁组合。例如,通过分析电影评分数据,我们可以发现用户同时喜欢的多部电影,从而实现个性化推荐。
在这个项目中,我们将不再局限于同种对象的相似度计算,而是转向于找出不同对象(如电影)之间的关联。亲和性分析数据通常包含交易记录,如用户观看电影的行为,这些数据可以揭示用户群体的消费习惯。应用场景广泛,包括但不限于欺诈检测、客户细分、软件优化以及产品推荐。
然而,亲和性分析面临的挑战之一是数据的稀疏性,即每个用户可能并未对所有电影进行评价。这导致了推荐系统必须处理用户行为的不完整性,例如,用户未评价某部电影的原因可能是尚未观看,也可能对该电影无兴趣。这种不确定性增加了推荐算法设计的复杂性。
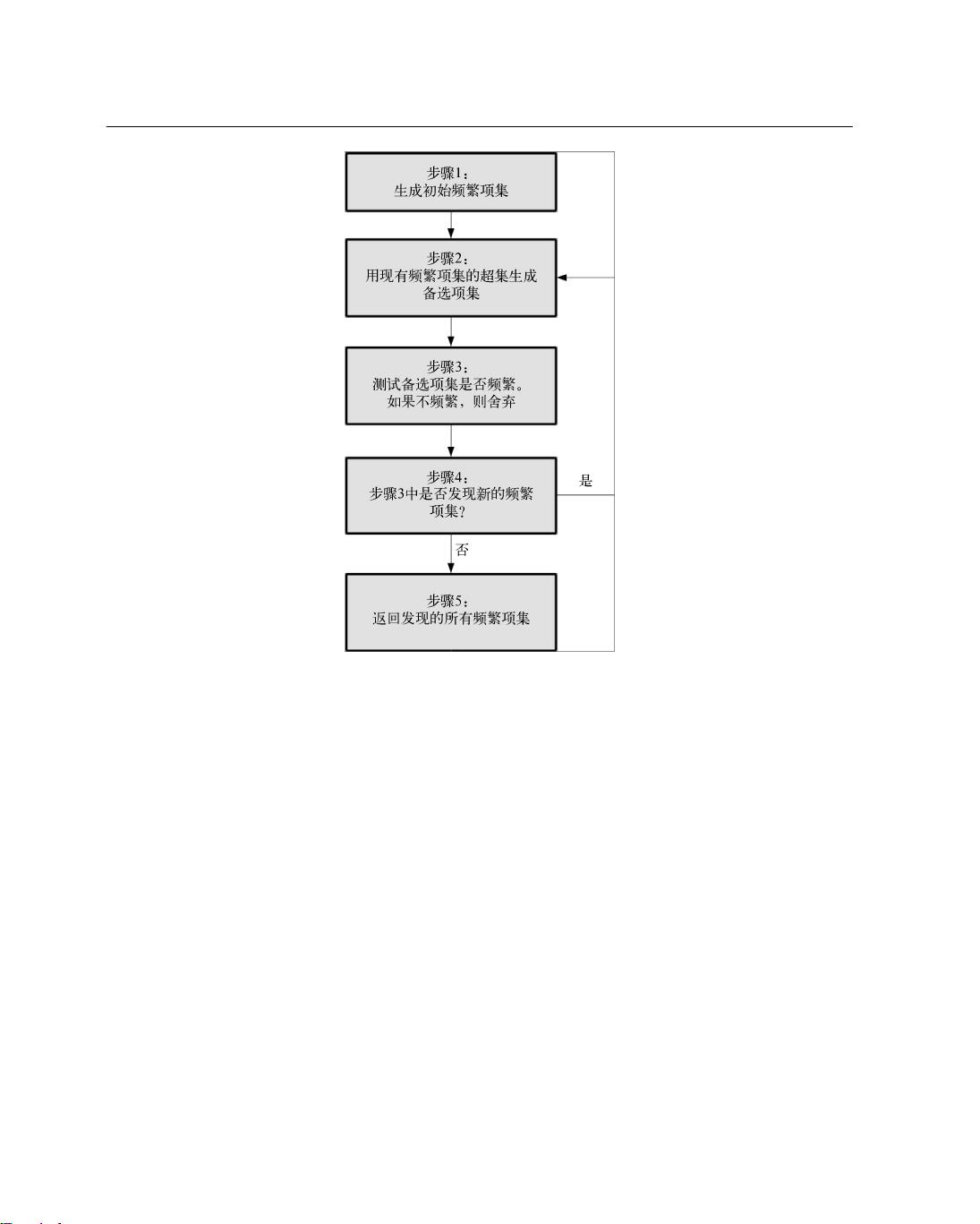
第4.1节详细介绍了亲和性分析算法,特别是Apriori算法,这是一种基于频繁模式挖掘的方法。原始的算法试图生成所有可能的规则组合,计算其支持度和置信度,然后根据这些指标筛选出最有价值的规则。然而,当数据集包含大量商品或特征时,这种方法的效率问题就突显出来,计算量会急剧增加,因此需要更高效的数据处理策略。
为了适应大规模数据集,需要考虑优化算法,例如使用剪枝策略或采用更复杂的算法结构,如FP-Growth,它能够减少计算时间,尤其是在商品数量巨大的情况下。理解并解决数据稀疏性和潜在问题对于提升推荐系统的准确性和实用性至关重要。
本章通过Python编程实例,不仅教授了如何运用亲和性分析方法,还涵盖了数据预处理、算法选择、性能优化等关键技术,使读者能够在实际项目中有效地利用这种分析方法进行电影推荐。
52 第4 章 用亲和性分析方法推荐电影
4.3.2 实现
Apriori算法第一次迭代时,新发现的项集长度为2,它们是步骤(1)中创建的项集的超集。第
二次迭代(经过步骤(4))中,新发现的项集长度为3。这有助于我们快速识别步骤(2)所需的项集。
我们把发现的频繁项集保存到以项集长度为键的字典中,便于根据长度查找,这样就可以找
到最新发现的频繁项集。下面的代码初始化一个字典。
frequent_itemsets = {}
我们还需要确定项集要成为频繁项集所需的最小支持度。这个值需要根据数据集的具体情况
来设定,可自行尝试其他值,建议每次只改动10个百分点,即使这样你可能也会发现算法运行时
间变动很大!下面,设置最小支持度。
min_support = 50
我们先来实现Apriori算法的第一步,为每一部电影生成只包含它自己的项集,检测它是否够
频繁。电影编号使用
frozenset,后面要用到集合操作。此外,它们也可以用作字典的键(普通
集合不可以)。代码如下:

剩余35页未读,继续阅读
2023-04-10 上传
2023-05-07 上传
2023-05-07 上传
2020-09-20 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

好知识传播者
- 粉丝: 1671
- 资源: 4133
 我的内容管理
展开
我的内容管理
展开







最新资源
- 深入浅出:自定义 Grunt 任务的实践指南
- 网络物理突变工具的多点路径规划实现与分析
- multifeed: 实现多作者间的超核心共享与同步技术
- C++商品交易系统实习项目详细要求
- macOS系统Python模块whl包安装教程
- 掌握fullstackJS:构建React框架与快速开发应用
- React-Purify: 实现React组件纯净方法的工具介绍
- deck.js:构建现代HTML演示的JavaScript库
- nunn:现代C++17实现的机器学习库开源项目
- Python安装包 Acquisition-4.12-cp35-cp35m-win_amd64.whl.zip 使用说明
- Amaranthus-tuberculatus基因组分析脚本集
- Ubuntu 12.04下Realtek RTL8821AE驱动的向后移植指南
- 掌握Jest环境下的最新jsdom功能
- CAGI Toolkit:开源Asterisk PBX的AGI应用开发
- MyDropDemo: 体验QGraphicsView的拖放功能
- 远程FPGA平台上的Quartus II17.1 LCD色块闪烁现象解析
