最新「基于Transformer的预训练模型」综述论文
需积分: 0 60 浏览量
更新于2023-04-28
2
收藏 5.63MB PDF 举报
基于Transformer的预训练语言模型(T-PTLMs)在几乎所有的自然语言处理任务中都取得了巨大的成功。这些模型的发展始于GPT和BERT。这些模型建立在Transformer、自监督学习和迁移学习的基础上。基于转换的PTLMs通过自监督学习从大量文本数据中学习通用语言表示,并将这些知识转移到下游任务中。这些模型为下游任务提供了良好的背景知识,避免了对下游模型从头开始的训练。

1
AMMUS : A Survey of Transformer-based
Pretrained Models in Natural Language
Processing
Katikapalli Subramanyam Kalyan, Ajit Rajasekharan, and Sivanesan Sangeetha
Abstract—Transformer-based pretrained language models (T-PTLMs) have achieved great success in almost every NLP task. The
evolution of these models started with GPT and BERT. These models are built on the top of transformers, self-supervised learning
and transfer learning. Transformed-based PTLMs learn universal language representations from large volumes of text data using
self-supervised learning and transfer this knowledge to downstream tasks. These models provide good background knowledge to
downstream tasks which avoids training of downstream models from scratch. In this comprehensive survey paper, we initially give a
brief overview of self-supervised learning. Next, we explain various core concepts like pretraining, pretraining methods, pretraining
tasks, embeddings and downstream adaptation methods. Next, we present a new taxonomy of T-PTLMs and then give brief overview
of various benchmarks including both intrinsic and extrinsic. We present a summary of various useful libraries to work with T-PTLMs.
Finally, we highlight some of the future research directions which will further improve these models. We strongly believe that this
comprehensive survey paper will ser ve as a good reference to learn the core concepts as well as to stay updated with the recent
happenings in T-PTLMs.
Index Terms—Self-Supervised Learning, Transformers, Pretrained Language Models, Survey.
F
CONTENTS
1 Introduction 2
2 Self-Supervised Learning (SSL) 3
2.1 Why Self-Supervised Learning? . . . 3
2.2 What is Self-Supervised Learning? . 3
2.3 Types of Self-Supervised Learning . 4
3 T-PTLM Core Concepts 4
3.1 Pretraining . . . . . . . . . . . . . . . 4
3.1.1 Pretraining Steps . . . . . . 4
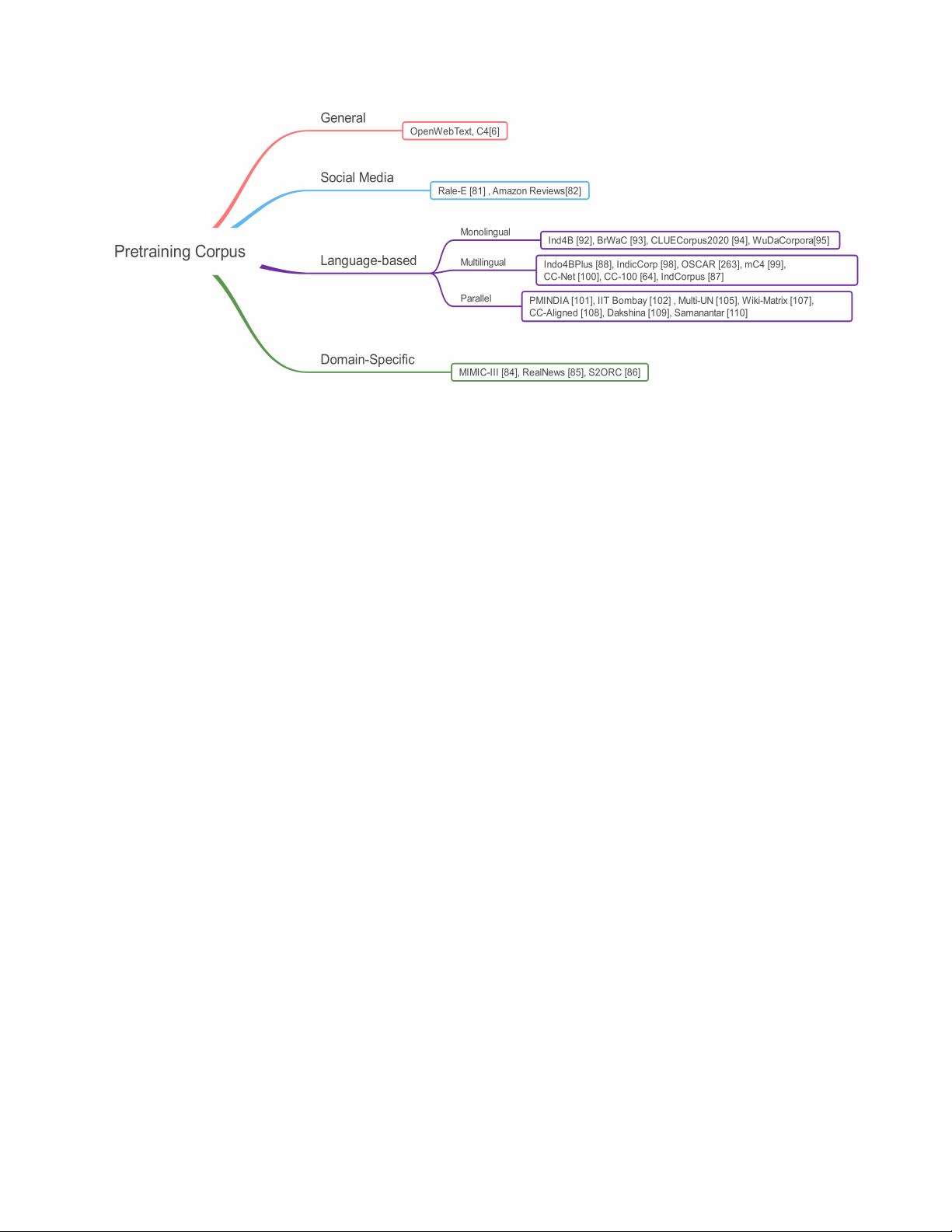
3.1.2 Pretraining Corpus . . . . 5
3.2 Types of Pretraining Methods . . . . 6
3.2.1 Pretraining from Scratch
(PTS) . . . . . . . . . . . . . 6
3.2.2 Continual Pretraining (CPT) 7
3.2.3 Simultaneous Pretraining
(SPT) . . . . . . . . . . . . . 8
3.2.4 Task Adaptive Pretraining
(TAPT) . . . . . . . . . . . . 8
• K.S.Kalyan is with the Department of Computer Applications, National
Institute of Technology Trichy, Trichy, Tamil Nadu, India, 620015.
E-mail: kalyan.ks@yahoo.com, Website: https://mr-nlp.github.io
• Ajit Rajasekharan is with the Nference.ai as CTO, Cambridge, MA, USA,
02142.
• S.Sangeetha is with the Department of Computer Applications, National
Institute of Technology Trichy, Trichy, Tamil Nadu, India, 620015..
Preprint under review - The paper is named (AMMUS - AMMU Smiles) in
the memory of one of the close friends of K.S.Kalyan (https://mr-nlp.github.
io).
3.2.5 Knowledge Inherited Pre-
training (KIPT) . . . . . . . 9
3.3 Pretraining Tasks . . . . . . . . . . . 9
3.4 Embeddings . . . . . . . . . . . . . . 12
3.4.1 Main Embeddings . . . . . 12
3.4.2 Auxiliary Embeddings . . 13
4 Taxonomy 14
4.1 Pretraining Corpus-based . . . . . . 14
4.1.1 General . . . . . . . . . . . 14
4.1.2 Social Media-based . . . . 14
4.1.3 Language-based . . . . . . 14
4.1.4 Domain-Specific Models . 17
4.2 Architecture . . . . . . . . . . . . . . 17
4.2.1 Encoder-based . . . . . . . 17
4.2.2 Decoder-based . . . . . . . 17
4.2.3 Encoder-Decoder based . . 18
4.3 SSL . . . . . . . . . . . . . . . . . . . . 19
4.3.1 Generative SSL . . . . . . . 19
4.3.2 Contrastive SSL . . . . . . 19
4.3.3 Adversarial SSL . . . . . . 19
4.3.4 Hybrid SSL . . . . . . . . . 20
4.4 Extensions . . . . . . . . . . . . . . . 20
4.4.1 Compact T-PTLMs . . . . . 20
4.4.2 Character-based T-PTLMs 21
4.4.3 Green T-PTLMs . . . . . . 21
4.4.4 Sentence-based T-PTLMs . 22
4.4.5 Tokenization-Free T-PLTMs 22
4.4.6 Large Scale T-PTLMs . . . 23
4.4.7 Knowledge Enriched T-
PTLMs . . . . . . . . . . . . 23
arXiv:2108.05542v1 [cs.CL] 12 Aug 2021



剩余41页未读,继续阅读
ProtTrans:ProtTrans提供了最先进的蛋白质预训练语言模型。 使用Transformers模型,对ProtTrans进行了来自Summit的数千个GPU和数百个Google TPU的培训
2021-04-13 上传
2021-09-07 上传
2021-10-19 上传
2020-09-21 上传
2023-03-29 上传
2022-08-03 上传
2023-08-10 上传
2023-05-13 上传
点击了解资源详情

syp_net
- 粉丝: 158
- 资源: 1187
 我的内容管理
展开
我的内容管理
展开







最新资源
- 批量文件重命名神器:HaoZipRename使用技巧
- 简洁注册登录界面设计与代码实现
- 掌握Python字符串处理与正则表达式技巧
- YOLOv5模块改进 - C3与RFAConv融合增强空间特征
- 基于EasyX的C语言打字小游戏开发教程
- 前端项目作业资源包:完整可复现的开发经验分享
- 三菱PLC与组态王实现加热炉温度智能控制
- 使用Go语言通过Consul实现Prometheus监控服务自动注册
- 深入解析Python进程与线程的并发机制
- 小波神经网络均衡算法:MATLAB仿真及信道模型对比
- PHP 8.3 中文版官方手册(CHM格式)
- SSM框架+Layuimini的酒店管理系统开发教程
- 基于SpringBoot和Vue的招聘平台完整设计与实现教程
- 移动商品推荐系统:APP设计与实现
- JAVA代码生成器:一站式后台系统快速搭建解决方案
- JSP驾校预约管理系统设计与SSM框架结合案例解析
