Python机器学习实战教程:回归机器学习实战教程:回归
引言和数据
欢迎阅读 Python 机器学习系列教程的回归部分。这里,你应该已经安装了 Scikit-Learn。如果没有,安装它,以及 Pandas
和 Matplotlib。
pip install numpy
pip install scipy
pip install scikit-learn
pip install matplotlib
pip install pandas
除了这些教程范围的导入之外,我们还要在这里使用 Quandl:
pip install quandl
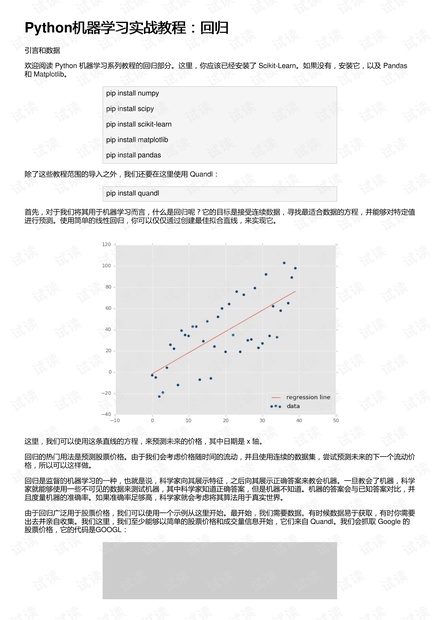
首先,对于我们将其用于机器学习而言,什么是回归呢?它的目标是接受连续数据,寻找最适合数据的方程,并能够对特定值
进行预测。使用简单的线性回归,你可以仅仅通过创建最佳拟合直线,来实现它。
这里,我们可以使用这条直线的方程,来预测未来的价格,其中日期是 x 轴。
回归的热门用法是预测股票价格。由于我们会考虑价格随时间的流动,并且使用连续的数据集,尝试预测未来的下一个流动价
格,所以可以这样做。
回归是监督的机器学习的一种,也就是说,科学家向其展示特征,之后向其展示正确答案来教会机器。一旦教会了机器,科学
家就能够使用一些不可见的数据来测试机器,其中科学家知道正确答案,但是机器不知道。机器的答案会与已知答案对比,并
且度量机器的准确率。如果准确率足够高,科学家就会考虑将其算法用于真实世界。
由于回归广泛用于股票价格,我们可以使用一个示例从这里开始。最开始,我们需要数据。有时候数据易于获取,有时你需要
出去并亲自收集。我们这里,我们至少能够以简单的股票价格和成交量信息开始,它们来自 Quandl。我们会抓取 Google 的
股票价格,它的代码是GOOGL:

剩余26页未读,继续阅读

weixin_38698433
- 粉丝: 4
- 资源: 969
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- zigbee-cluster-library-specification
- JSBSim Reference Manual
- c++校园超市商品信息管理系统课程设计说明书(含源代码) (2).pdf
- 建筑供配电系统相关课件.pptx
- 企业管理规章制度及管理模式.doc
- vb打开摄像头.doc
- 云计算-可信计算中认证协议改进方案.pdf
- [详细完整版]单片机编程4.ppt
- c语言常用算法.pdf
- c++经典程序代码大全.pdf
- 单片机数字时钟资料.doc
- 11项目管理前沿1.0.pptx
- 基于ssm的“魅力”繁峙宣传网站的设计与实现论文.doc
- 智慧交通综合解决方案.pptx
- 建筑防潮设计-PowerPointPresentati.pptx
- SPC统计过程控制程序.pptx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0