
Python人工智能之路人工智能之路-第三篇第三篇:PyAudio实现录音自动化交互实实现录音自动化交互实
现问答现问答
Python 很强大其原因就是因为它庞大的三方库 , 资源是非常的丰富 , 当然也不会缺少关于音频的库
关于音频, PyAudio 这个库, 可以实现开启麦克风录音, 可以播放音频文件等等,此刻我们不去了解其他的功能,只了解一下它如何
实现录音的
首先要先 pip 一个 PyAudio
pip install pyaudio
一.PyAudio 实现麦克风录音
然后建立一个py文件,复制如下代码
尝试一下,在目录中出现了一个 Oldboy.wav 文件 , 听一听,还是很清晰的嘛
接下来,我们将这段录音代码,写在一个函数里面,如果要录音的话就调用
建立一个文件 pyrec.py 并将录音代码和函数写在内
rec 函数就是我们调用的录音函数,并且给他一个文件名,他就会自动将声音写入到文件中了
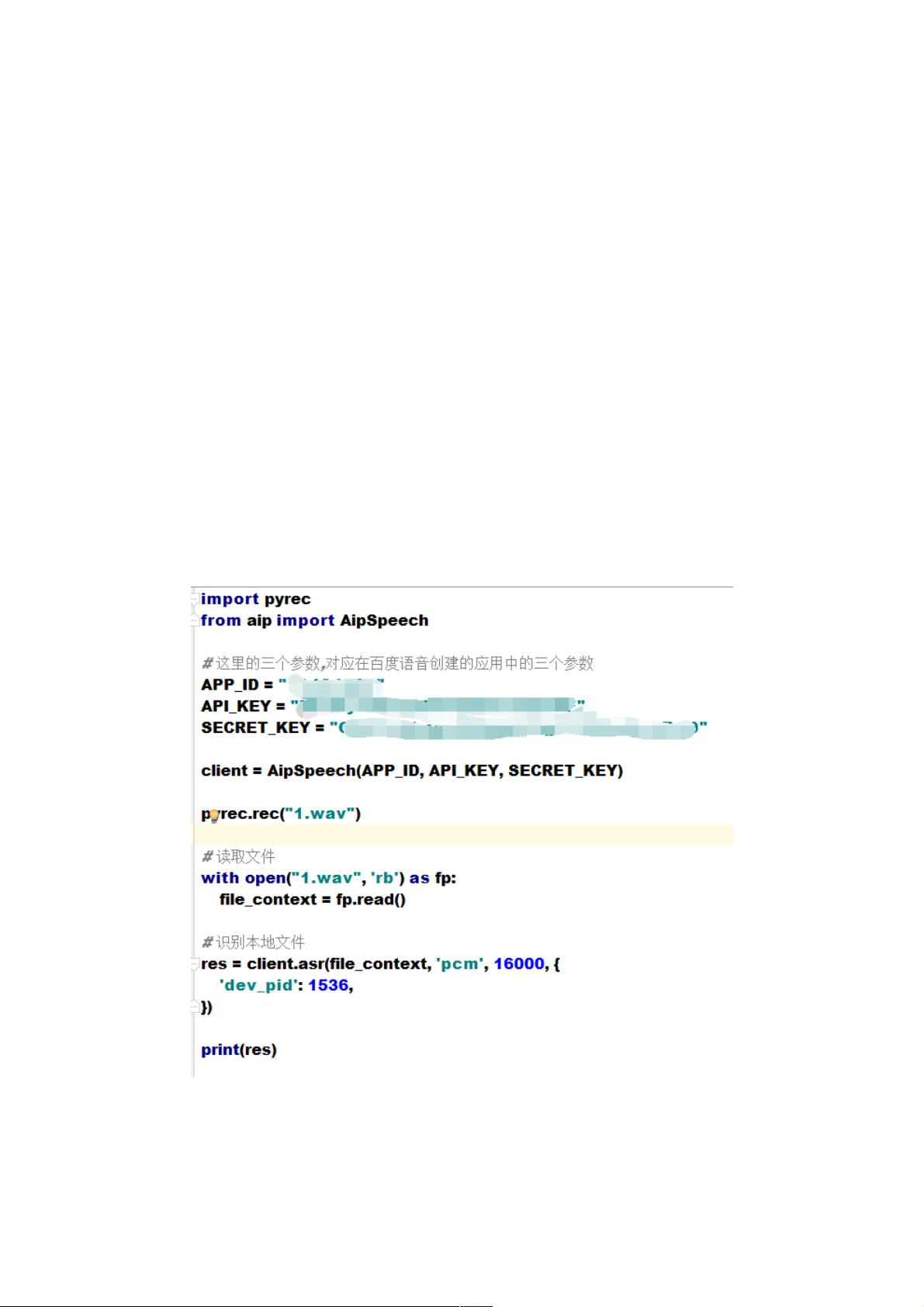
二.实现音频格式自动转换 并 调用语音识别
录音的问题解决了,赶快和百度语音识别接在一起使用一下:
不管你的录音有多么多么清晰,你发现百度给你返回的永远是:
其实不是没听清,而是百度支持的音频格式PCM搞的鬼
所以,我们要将录制的wav音频文件转换为pcm文件
写一个文件 wav2pcm.py 这个文件里面的函数是专门为我们转换wav文件的
使用 os 模块中的 os.system()方法 这个方法是执行系统命令用的, 在windows系统中的命令就是 cmd 里面写的东西,dir , cd 这
类的命令

weixin_38503483
- 粉丝: 8
- 资源: 942
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- zigbee-cluster-library-specification
- JSBSim Reference Manual
- c++校园超市商品信息管理系统课程设计说明书(含源代码) (2).pdf
- 建筑供配电系统相关课件.pptx
- 企业管理规章制度及管理模式.doc
- vb打开摄像头.doc
- 云计算-可信计算中认证协议改进方案.pdf
- [详细完整版]单片机编程4.ppt
- c语言常用算法.pdf
- c++经典程序代码大全.pdf
- 单片机数字时钟资料.doc
- 11项目管理前沿1.0.pptx
- 基于ssm的“魅力”繁峙宣传网站的设计与实现论文.doc
- 智慧交通综合解决方案.pptx
- 建筑防潮设计-PowerPointPresentati.pptx
- SPC统计过程控制程序.pptx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


