网易大数据:Impala在使用与优化中的实战分享
版权申诉
91 浏览量
更新于2024-07-05
收藏 4.65MB PDF 举报
"《7-3Impala在网易大数据中的使用和优化实践》一文深入探讨了在网易大数据环境中,Impala的应用及其优化策略。作者温正湖,作为高级数据库技术专家和OLTP&OLAP内核团队负责人,分享了Impala在数据处理领域的关键角色。
首先,文章介绍了Impala的定位和主要优势。Impala是一种针对大规模数据集进行快速查询的查询引擎,适用于百万至百亿级别的数据量。它采用去中心化的MPP(大规模并行处理)架构,相比传统的集中式数据库系统,如MySQL、PostgreSQL和MongoDB,Impala在处理海量数据时具有显著的优势,如多查询入口设计避免单点故障、并行Join、Aggregation和TopN操作,以及基于代价执行优化(CBO)和Catalog缓存的查询性能提升。
Impala特别适合于分析型数仓和自助分析场景,无论是宽表设计还是星型或雪花型数据模型,都能高效支持。此外,它还提供了友好的WebUI界面,便于监控节点内存消耗、查询分析、SQL诊断和异常查询终止,以及Metircs信息查看,确保了用户的使用体验。
文章还提及了Impala与Presto和SparkSQL的比较,强调了Impala在查询性能上的优势,以及其对Hive元数据的完全兼容性。作为Apache的顶级项目,Impala拥有活跃的社区支持,并且支持多种数据格式(如Parquet和ORC),可以与Kudu结合实现实时数仓功能。
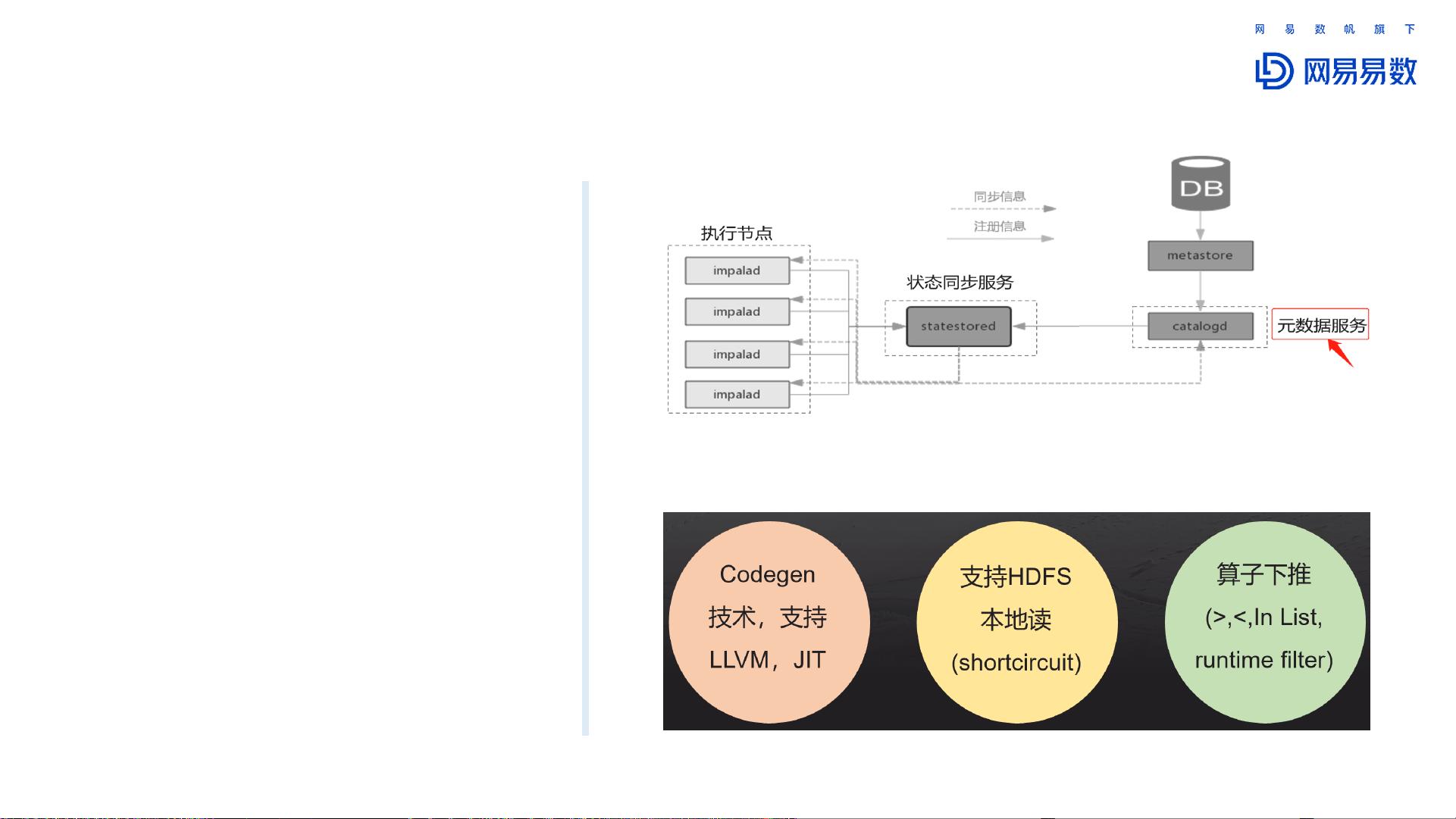
对于实际应用中的优化,文中提到了Impala管理服务器的改进,包括元数据同步增强、基于ZooKeeper的服务高可用性、增加支持的存储后端以及更全面的信息持久化,以解决社区版管理服务器非持久化问题,如信息丢失的问题。通过MySQL存储集群信息,使得集群配置和统计信息得以持久化,同时记录SQL执行计划等详细信息,提高了系统的稳定性和可靠性。
《7-3Impala在网易大数据中的使用和优化实践》是一篇实用的指南,详细解析了如何在网易大数据场景中有效利用和优化Impala,帮助企业处理和分析海量数据,提高业务效率。"
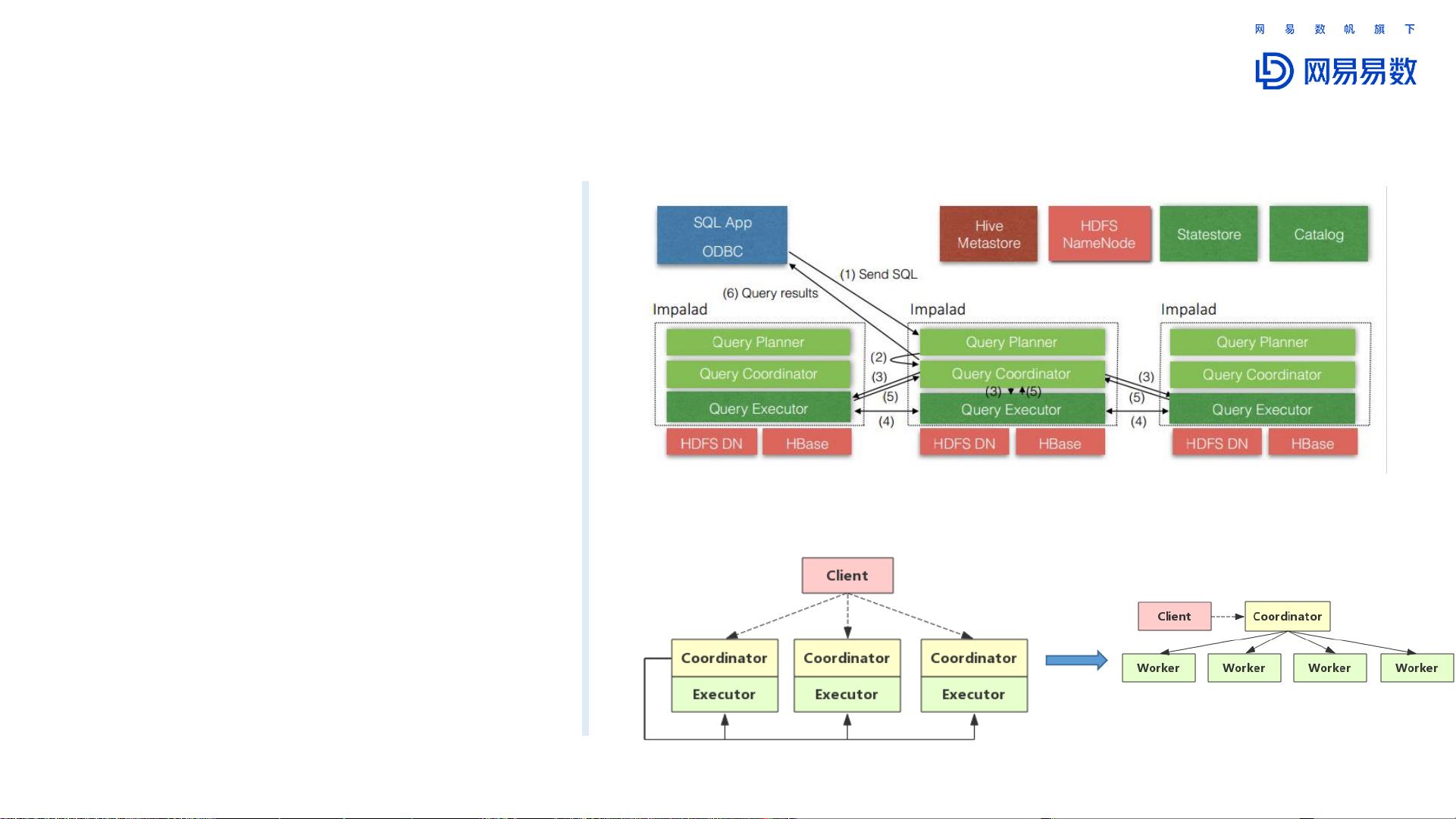
Impala优势
➢ 去中心化的MPP并行架构
Impala架构
vs
传统架构
✓ 多查询入口,防止对外服务单点故障
✓ MPP并行计算
并行Join
并行Aggregation 并行TopN
剩余32页未读,继续阅读
2021-12-25 上传
2022-03-18 上传
2021-10-14 上传
2022-03-18 上传
2022-03-18 上传
2021-09-14 上传
2022-06-19 上传
2022-12-24 上传

普通网友
- 粉丝: 13w+
- 资源: 9195
 我的内容管理
展开
我的内容管理
展开







