
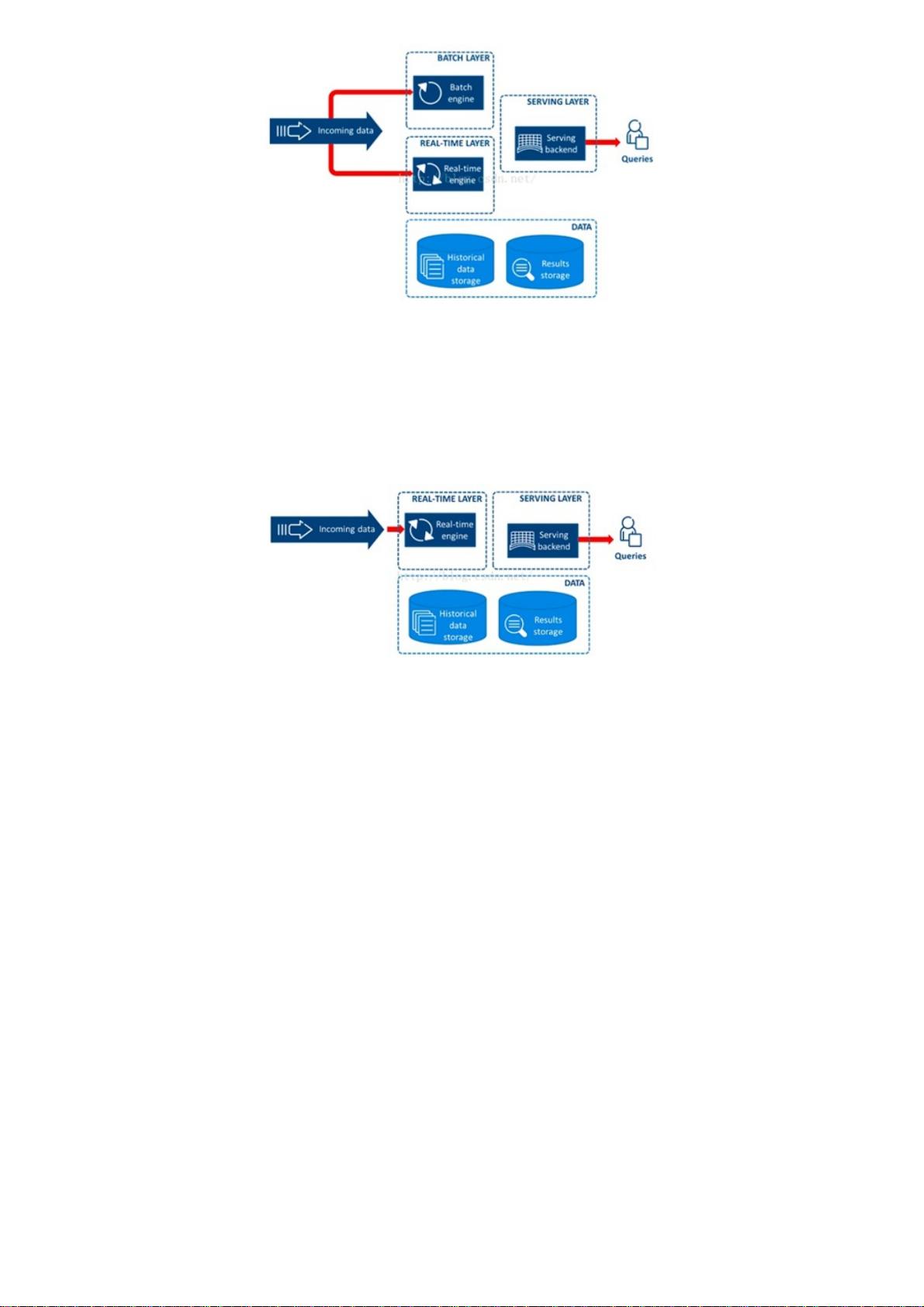
图3. Lambda架构示意
Lambda架构的核心理念是“流批一体”,如上图所示,整个数据流向自左向右流入平台。进入平台后一分为二,一部分走批处
理模式,一部分走流式计算模式。无论哪种计算模式,最终的处理结果都通过服务层对应用提供,确保访问的一致性。
3) 第三阶段:Kappa架构。Lambda架构解决了应用读取数据的一致性问题,但是“流批分离”的处理链路增大了研发的复杂
性。因此,有人就提出能不能用一套系统来解决所有问题。目前比较流行的做法就是基于流计算来做。流计算天然的分布式特
征,注定了他的扩展性更好。通过加大流计算的并发性,加大流式数据的“时间窗口”,来统一批处理与流式处理两种计算模
式。
图4. Kappa架构示意
综上,从传统的hadoop架构往lambda架构,从lambda架构往Kappa架构的演进,大数据平台基础架构的演进逐渐囊括了应用
所需的各类数据处理能力,大数据平台逐渐演化成了一个企业/组织的全量数据处理平台。当前的企业实践中,除了关系型数
据库依托于各个独立的业务系统;其余的数据,几乎都被考虑纳入大数据平台来进行统一的处理。然而,目前的大数据平台基
础架构,都将视角锁定在了存储和计算,而忽略了对于数据的资产化管理,这恰恰是数据湖作为新一代的大数据基础设施所重
点关注的方向之一。
曾经看过一个很有意思的文章,提出过如下问题:数据湖为什么叫数据湖而不叫数据河或者数据海?一个有意思的回答是:
1)“河”强调的是流动性,“海纳百川”,河终究是要流入大海的,而企业级数据是需要长期沉淀的,因此叫“湖”比叫“河”要贴
切;同时,湖水天然是分层的,满足不同的生态系统要求,这与企业建设统一数据中心,存放管理数据的需求是一致
的,“热”数据在上层,方便应用随时使用;温数据、冷数据位于数据中心不同的存储介质中,达到数据存储容量与成本的平
衡。
2)不叫“海”的原因在于,海是无边无界的,而“湖”是有边界的,这个边界就是企业/组织的业务边界;因此数据湖需要更多的
数据管理和权限管理能力。
3)叫“湖”的另一个重要原因是数据湖是需要精细治理的,一个缺乏管控、缺乏治理的数据湖最终会退化为“数据沼泽”,从而使
应用无法有效访问数据,使存于其中的数据失去价值。
大数据基础架构的演进,其实反应了一点:在企业/组织内部,数据是一类重要资产已经成为了共识;为了更好的利用数据,
企业/组织需要对数据资产1)进行长期的原样存储;2)进行有效管理与集中治理;3)提供多模式的计算能力满足处理需求;
4)以及面向业务,提供统一的数据视图、数据模型与数据处理结果。数据湖就是在这个大背景下产生的,除了大数据平台所
拥有的各类基础能力之外,数据湖更强调对于数据的管理、治理和资产化能力。落到具体的实现上,数据湖需要包括一系列的
数据管理组件,包括:1)数据接入;2)数据搬迁;3)数据治理;4)质量管理;5)资产目录;6)访问控制;7)任务管
理;8)任务编排;9)元数据管理等。如下图所示,给出了一个数据湖系统的参考架构。对于一个典型的数据湖而言,它与
大数据平台相同的地方在于它也具备处理超大规模数据所需的存储和计算能力,能提供多模式的数据处理能力;增强点在于数
据湖提供了更为完善的数据管理能力,具体体现在:
1) 更强大的数据接入能力。数据接入能力体现在对于各类外部异构数据源的定义管理能力,以及对于外部数据源相关数据的
抽取迁移能力,抽取迁移的数据包括外部数据源的元数据与实际存储的数据。
2) 更强大的数据管理能力。管理能力具体又可分为基本管理能力和扩展管理能力。基本管理能力包括对各类元数据的管理、
剩余16页未读,继续阅读

weixin_38656142
- 粉丝: 6
- 资源: 910
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- 共轴极紫外投影光刻物镜设计研究
- 基于GIS的通信管线管理系统构建与音视频编解码技术应用
- 单站被动目标跟踪算法:空频域信息下的深度研究与进展
- 构建通信企业工程项目的项目管理成熟度模型:理论与应用
- 基于控制理论的主动队列管理算法与稳定性分析
- 谷歌文件系统下的实用网络编码技术在分布式存储中的应用
- CMOS图像传感器快门特性与运动物体测量研究
- 深孔采矿研究:3D数据库在采场损失与稳定性控制中的应用
- 《洛神赋图》图像研究:明清以来的艺术价值与历史意义
- 故宫藏《洛神赋图》图像研究:明清艺术价值与审美的飞跃
- 分布式视频编码:无反馈通道算法与复杂运动场景优化
- 混沌信号的研究:产生、处理与通信系统应用
- 基于累加器的DSP数据通路内建自测试技术研究
- 跨国媒体对南亚农村社会的影响:以斯里兰卡案例的社会学分析
- 散单元法与CFD结合模拟气力输送研究
- 基于粒化机理的粗糙特征选择算法:海量数据高效处理研究
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


