PyTorch实现GAN生成MNIST:理解二人博弈思想
"这篇教程介绍了如何使用PyTorch实现GAN(生成对抗网络)来生成MNIST数据集。作者通过这个小项目旨在理解GAN的工作原理并熟悉PyTorch框架。GAN的核心理念是生成模型(G)与判别模型(D)之间的博弈,其中G试图制造逼真的假样本,而D则试图区分真假样本。代码示例展示了如何构建和训练这两个模型,以及数据预处理和结果保存的方法。"
在PyTorch中实现GAN生成MNIST数据集涉及以下几个关键知识点:
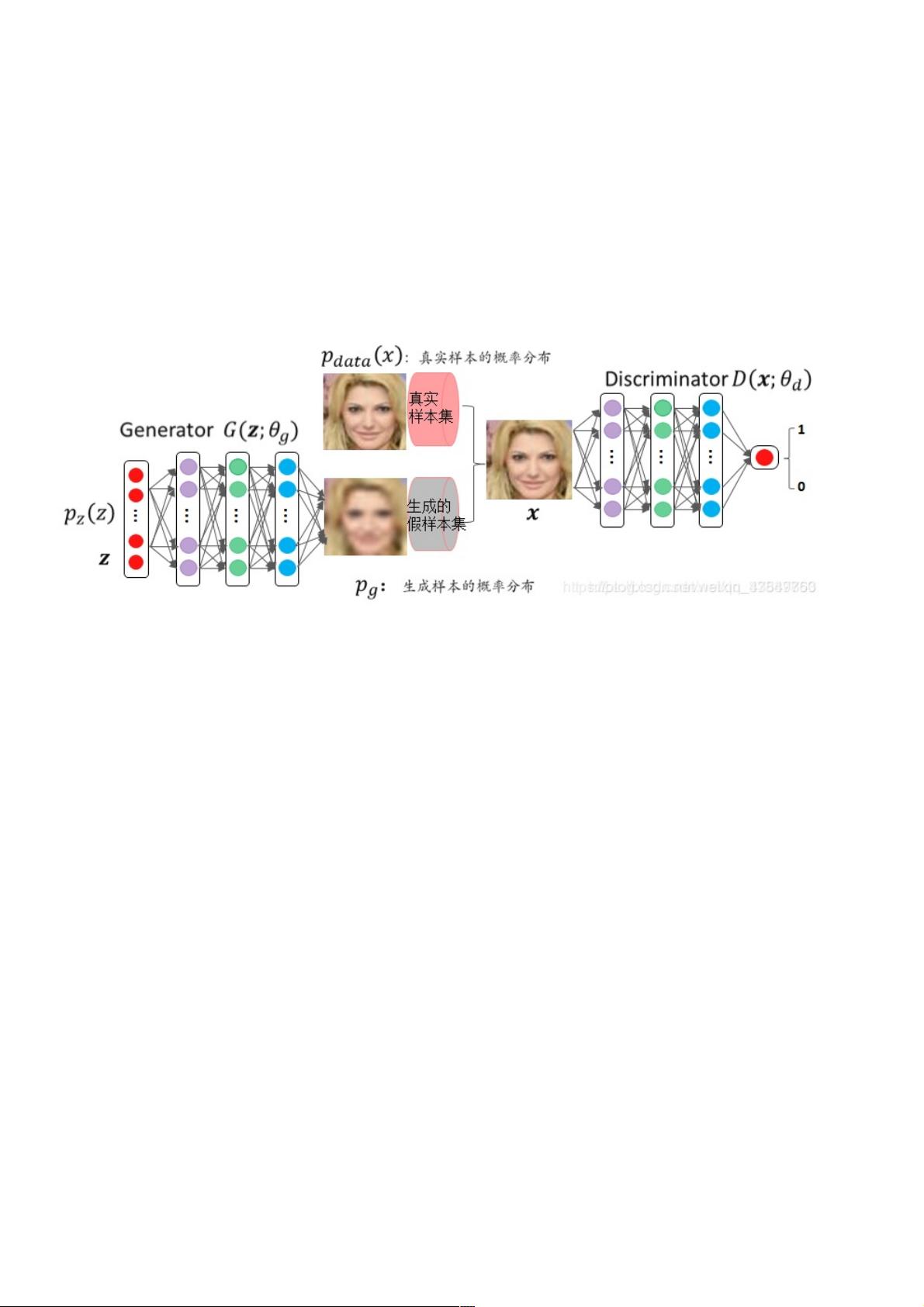
1. **生成对抗网络(GANs)**:GANs由两部分组成,生成器(Generator)和判别器(Discriminator)。生成器尝试生成与真实数据分布相似的新样本,而判别器则负责区分这些新样本与真实样本。两者通过反复迭代优化,生成器逐渐提高伪造样本的质量,直至判别器无法准确区分。
2. **PyTorch框架**:PyTorch是一个用于深度学习的Python库,它提供了自动求梯度、张量运算和构建神经网络的工具。在这个例子中,`torch.nn`和`torch.autograd`模块被用来定义和训练模型,而`torchvision`则用于加载和预处理MNIST数据集。
3. **数据预处理**:预处理步骤包括将图像转换为Tensor,并进行归一化。这里使用了`transforms.Compose`来组合多个预处理操作,如`transforms.ToTensor()`将数据转化为0-1之间的浮点数,`transforms.Normalize`则进一步将数据规范化到特定的均值和标准差。
4. **模型定义**:生成器通常是一个从随机噪声向量(在这个例子中,维度为50,即`z_dimension=50`)生成图像的网络,而判别器是一个接收图像并预测其真实性的网络。这两个网络都是基于PyTorch的`nn.Module`子类化构建的。
5. **损失函数和优化器**:在GAN中,通常使用二元交叉熵损失(Binary Cross Entropy Loss)来训练判别器,同时生成器的训练目标是让判别器对其生成的样本产生误判。每个网络都会有自己的优化器,如Adam或SGD,用于更新权重。
6. **训练过程**:在训练过程中,先固定生成器并更新判别器,然后固定判别器并更新生成器。这种交替优化的方式是GAN训练的关键。
7. **保存结果**:`save_image`函数用于将生成的图像保存到本地文件夹,以便观察生成样本的质量随训练过程的改善。
8. **变量(Variable)**:在旧版本的PyTorch中,`Variable`用于封装张量并跟踪其历史,便于自动求梯度。不过在现代版本中,可以直接使用张量,自动求梯度功能已内置。
9. **数据集加载**:`datasets.MNIST`用于从本地或网络下载MNIST数据集,`root`参数指定数据存储位置,`transform`参数传递预处理函数。
10. **批处理(Batch Size)**:`batch_size=128`表示每次迭代中用于训练的样本数量,这是训练效率和内存消耗的权衡。
通过这个项目,你可以了解GAN的基本工作流程,以及如何在PyTorch中实现一个简单的GAN模型,这对于进一步探索图像生成、超分辨率等任务具有基础性指导意义。
GAN生成生成MNIST数据集(数据集(pytorch版)版)
前言前言
最近准备研究关于用GAN神经网络实现图片超分辨的项目,为了理解GAN神经网络的内涵和更熟悉的掌握pytorch框架的用
法,写了这个小demo熟悉手感
思想思想
GAN的思想是是一种二人零和博弈思想,网上比较流行的一种比喻就是生成模型(G)是印假钞的人,而判别模型(D)就是
判断是否是假钞的警察。
判别网络的目的:就是能判别输入的数据(如图片)它是来自真实样本集还是假样本集。假如输入的是真样本,网络输出就接
近1,输入的是假样本,网络输出接近0,那么很完美,达到了很好判别的目的。
生成网络的目的:生成网络是造样本的,它的目的就是使得自己造样本的能力尽可能强,强到判别网络没法判断我是真样本还
是假样本。
代码实现代码实现
talk is cheap,show me your code
# coding=utf-8
import torch.autograd
import torch.nn as nn
from torch.autograd import Variable
from torchvision import transforms
from torchvision import datasets
from torchvision.utils import save_image
import os
# 创建文件夹
if not os.path.exists('./img2'):
os.mkdir('./img2')
def to_img(x):
out = 0.5 * (x + 1)
out = out.clamp(0, 1) # Clamp函数可以将随机变化的数值限制在一个给定的区间[min, max]内:
out = out.view(-1, 1, 28, 28) # view()函数作用是将一个多行的Tensor,拼接成一行
return out
batch_size = 128
num_epoch = 1000
z_dimension = 50
# 图像预处理
img_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1,), (0.5,))
])
# mnist dataset mnist数据集下载,没有下载的将download改成True
mnist = datasets.MNIST(
root='./mnist/', train=True, transform=img_transform, download=False
)
# data loader 数据载入
dataloader = torch.utils.data.DataLoader(
dataset=mnist, batch_size=batch_size, shuffle=True
下载后可阅读完整内容,剩余3页未读,立即下载
2018-06-29 上传
2018-08-19 上传
2023-10-20 上传
2023-07-28 上传
2023-10-17 上传
2023-04-03 上传
2023-08-29 上传
2023-09-17 上传

weixin_38513794
- 粉丝: 1
- 资源: 946
 我的内容管理
展开
我的内容管理
展开







最新资源
- CoreOS部署神器:configdrive_creator脚本详解
- 探索CCR-Studio.github.io: JavaScript的前沿实践平台
- RapidMatter:Web企业架构设计即服务应用平台
- 电影数据整合:ETL过程与数据库加载实现
- R语言文本分析工作坊资源库详细介绍
- QML小程序实现风车旋转动画教程
- Magento小部件字段验证扩展功能实现
- Flutter入门项目:my_stock应用程序开发指南
- React项目引导:快速构建、测试与部署
- 利用物联网智能技术提升设备安全
- 软件工程师校招笔试题-编程面试大学完整学习计划
- Node.js跨平台JavaScript运行时环境介绍
- 使用护照js和Google Outh的身份验证器教程
- PHP基础教程:掌握PHP编程语言
- Wheel:Vim/Neovim高效缓冲区管理与导航插件
- 在英特尔NUC5i5RYK上安装并优化Kodi运行环境
