
tensorflow使用使用L2 regularization正则化修正正则化修正overfitting过拟过拟
合方式合方式
主要介绍了tensorflow使用L2 regularization正则化修正overfitting过拟合方式,具有很好的参考价值,希望对大
家有所帮助。一起跟随小编过来看看吧
L2正则化原理:正则化原理:
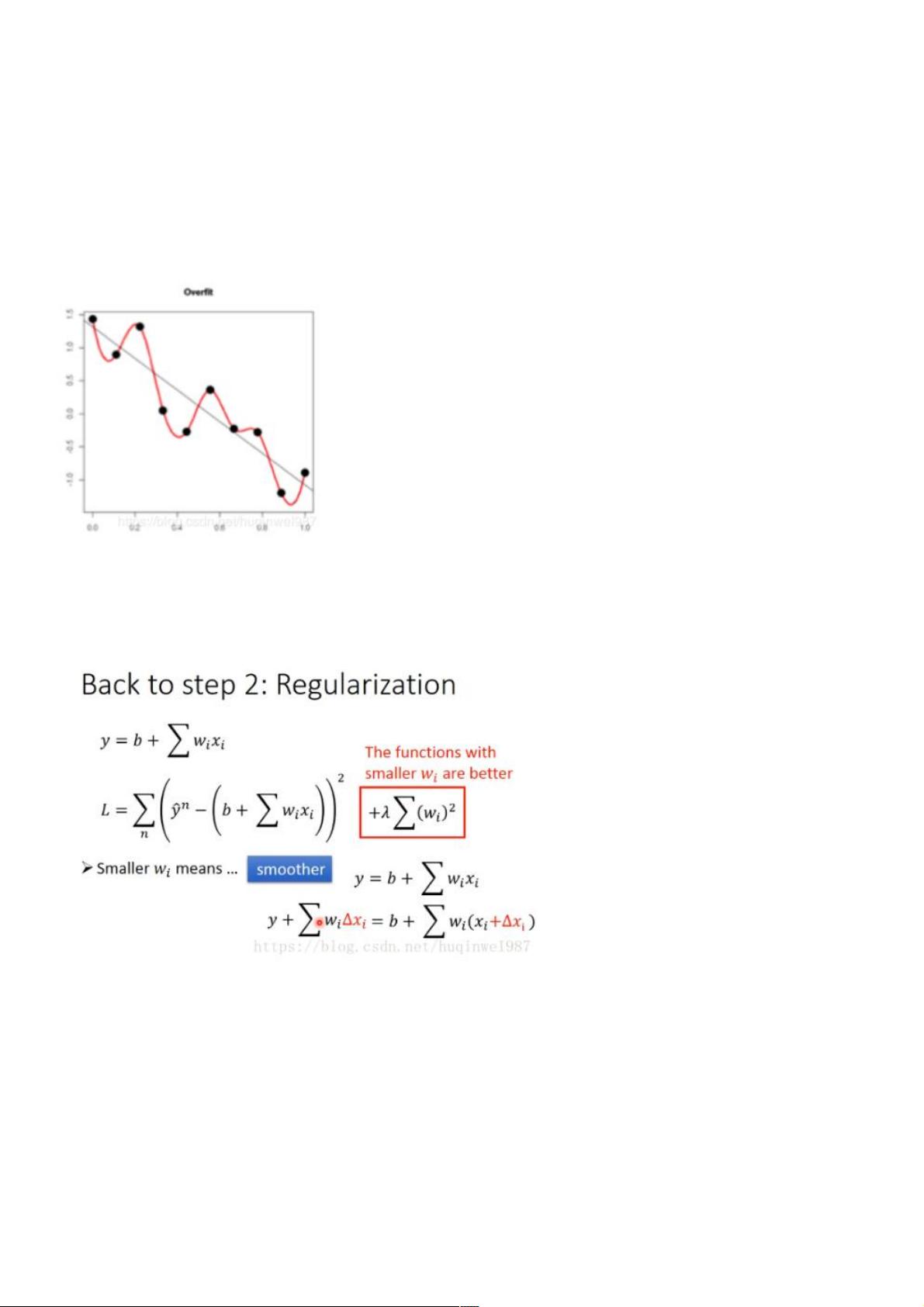
过拟合的原理:在loss下降,进行拟合的过程中(斜线),不同的batch数据样本造成红色曲线的波动大,图中低点也就是过
拟合,得到的红线点低于真实的黑线,也就是泛化更差。
可见,要想减小过拟合,减小这个波动,减少w的数值就能办到。
L2正则化训练的原理:在Loss中加入(乘以系数λ的)参数w的平方和,这样训练过程中就会抑制w的值,w的(绝对)值小,
模型复杂度低,曲线平滑,过拟合程度低(奥卡姆剃刀),参考公式如下图:
(正则化是不阻碍你去拟合曲线的,并不是所有参数都会被无脑抑制,实际上这是一个动态过程,是loss(cross_entropy)
和L2 loss博弈的一个过程。训练过程会去拟合一个合理的w,正则化又会去抑制w的变化,两项相抵消,无关的wi越变越小,
但是比零强一点(就是这一点,比没有要强,这也是L2的trade-off),有用的wi会被保留,处于一个“中庸”的范围,在拟合的
基础上更好的泛化。过多的道理和演算就不再赘述。)
那为什么L1不能办到呢?主要是L1有副作用,不太适合这个场景。
L1把L2公式中wi的平方换成wi的绝对值,根据数学特性,这种方式会导致wi不均衡的被减小,有些wi很大,有些wi很小,得到
稀疏解,属于特征提取。为什么L1的w衰减比L2的不均衡,这个很直觉的,同样都是让loss低,让w1从0.1降为0,和w2从1.0
降为0.9,对优化器和loss来说,是一样的。但是带上平方以后,前者是0.01-0=0.01,后者是1-0.81=0.19,这时候明显是减少
w2更划算。下图最能说明问题,横纵轴是w1、w2等高线是loss的值,左图的交点w1=0,w2=max(w2),典型的稀疏解,丢
弃了w1,而右图则是在w1和w2之间取得平衡。这就意味着,本来能得到一条曲线,现在w1丢了,得到一条直线,降低过拟合
的同时,拟合能力(表达能力)也下降了。

weixin_38522106
- 粉丝: 2
- 资源: 901
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- 保险服务门店新年工作计划PPT.pptx
- 车辆安全工作计划PPT.pptx
- ipqc工作总结PPT.pptx
- 车间员工上半年工作总结PPT.pptx
- 保险公司员工的工作总结PPT.pptx
- 报价工作总结PPT.pptx
- 冲压车间实习工作总结PPT.pptx
- ktv周工作总结PPT.pptx
- 保育院总务工作计划PPT.pptx
- xx年度现代教育技术工作总结PPT.pptx
- 出纳的年终总结PPT.pptx
- 贝贝班班级工作计划PPT.pptx
- 变电值班员技术个人工作总结PPT.pptx
- 大学生读书活动策划书PPT.pptx
- 财务出纳月工作总结PPT.pptx
- 大学生“三支一扶”服务期满工作总结(2)PPT.pptx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


