

OpenStack Queens HA 部署手册
1、基础知识
1.1、高可用(HighAvailability,简称 HA)
高可用性是指提供在本地系统单个组件故障情况下,能继续访问应用的能力,无论这
个故障是业务流程、物理设施、IT 软/硬件的故障。最好的可用性,就是你的一台机器宕机
了,但是使用你的服务的用户完全感觉不到。你的机器宕机了,在该机器上运行的服务肯定
得做故障切换(failover),切换有两个维度的成本:RTO(RecoveryTimeObjective)和 RPO
(RecoveryPointObjective)。 RTO 是服务恢复的时间,最佳的情况是 0,这意味着服务立即
恢复;最坏是无穷大意味着服务永远恢复不了;RPO 是切换时向前恢复的数据的时间长度,
0 意味着使用同步的数据,大于 0 意味着有数据丢失,比如“RPO=1 天”意味着恢复时使用
一天前的数据,那么一天之内的数据就丢失了。因此,恢复的最佳结果是 RTO=RPO=0,但
是这个太理想,或者要实现的话成本太高,全球估计 Visa 等少数几个公司能实现,或者几
乎实现。
对 HA 来说,往往使用共享存储,这样的话,RPO=0;同时往往使用 Active/Active(双
活集群)HA 模式来使得 RTO 几乎 0,如果使用 Active/Passive 模式的 HA 的话,则需要将
RTO 减少到最小限度。HA 的计算公式是[1-(宕机时间)/(宕机时间+运行时间)],我们常常
用几个 9 表示可用性:
2 个 9:99%=1%*365=3.65*24 小时/年=87.6 小时/年的宕机时间
4 个 9:99.99%=0.01%*365*24*60=52.56 分钟/年
5 个 9:99.999%=0.001%*365=5.265 分钟/年的宕机时间,也就意味着每次停机时间
在一到两分钟。
11 个 9:几乎就是几年才宕机几分钟。据说 AWSS3 的设计高可用性就是 11 个 9。
1.1.1 服务的分类
HA 将服务分为两类:
有状态服务:后续对服务的请求依赖于之前对服务的请求。
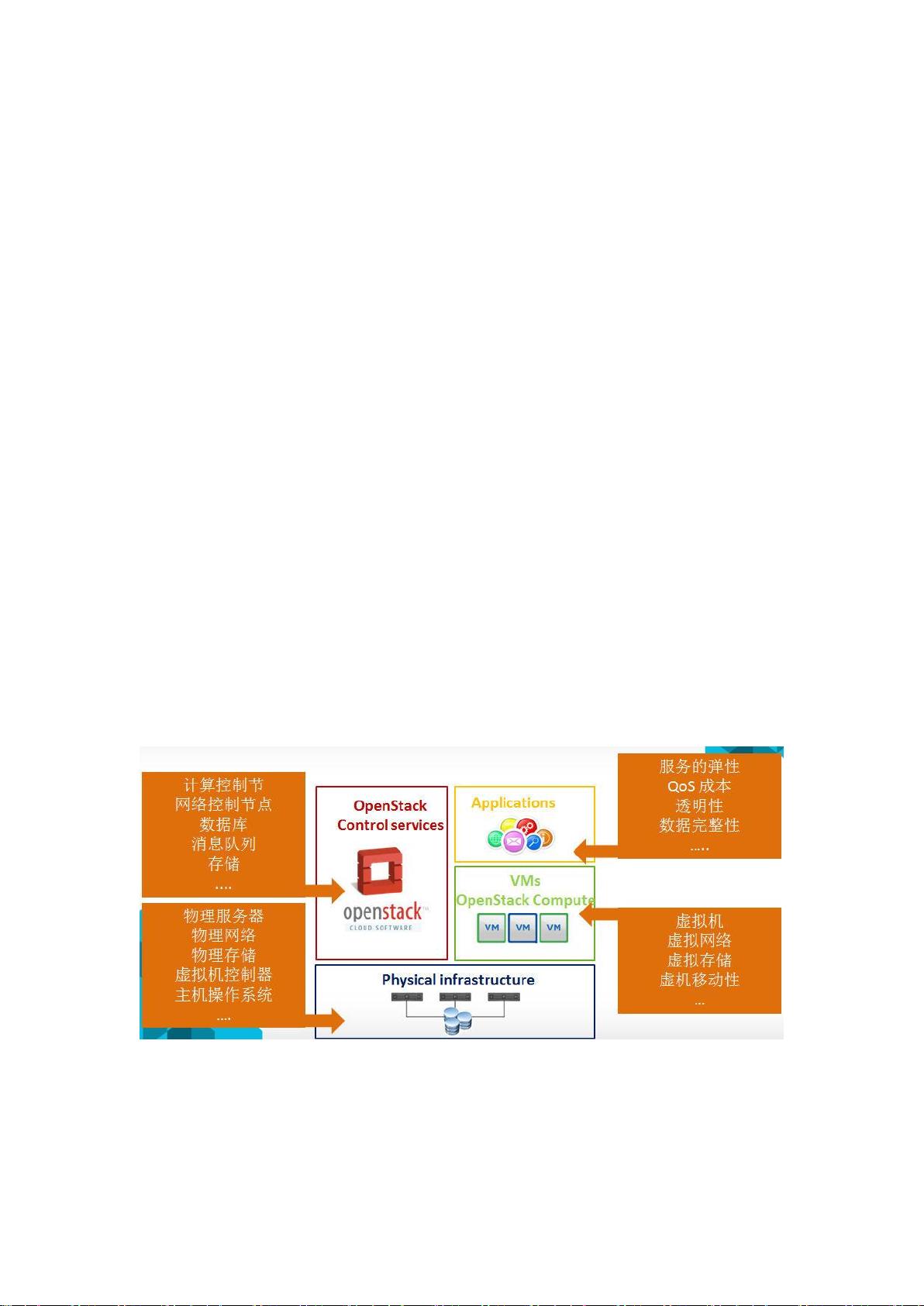


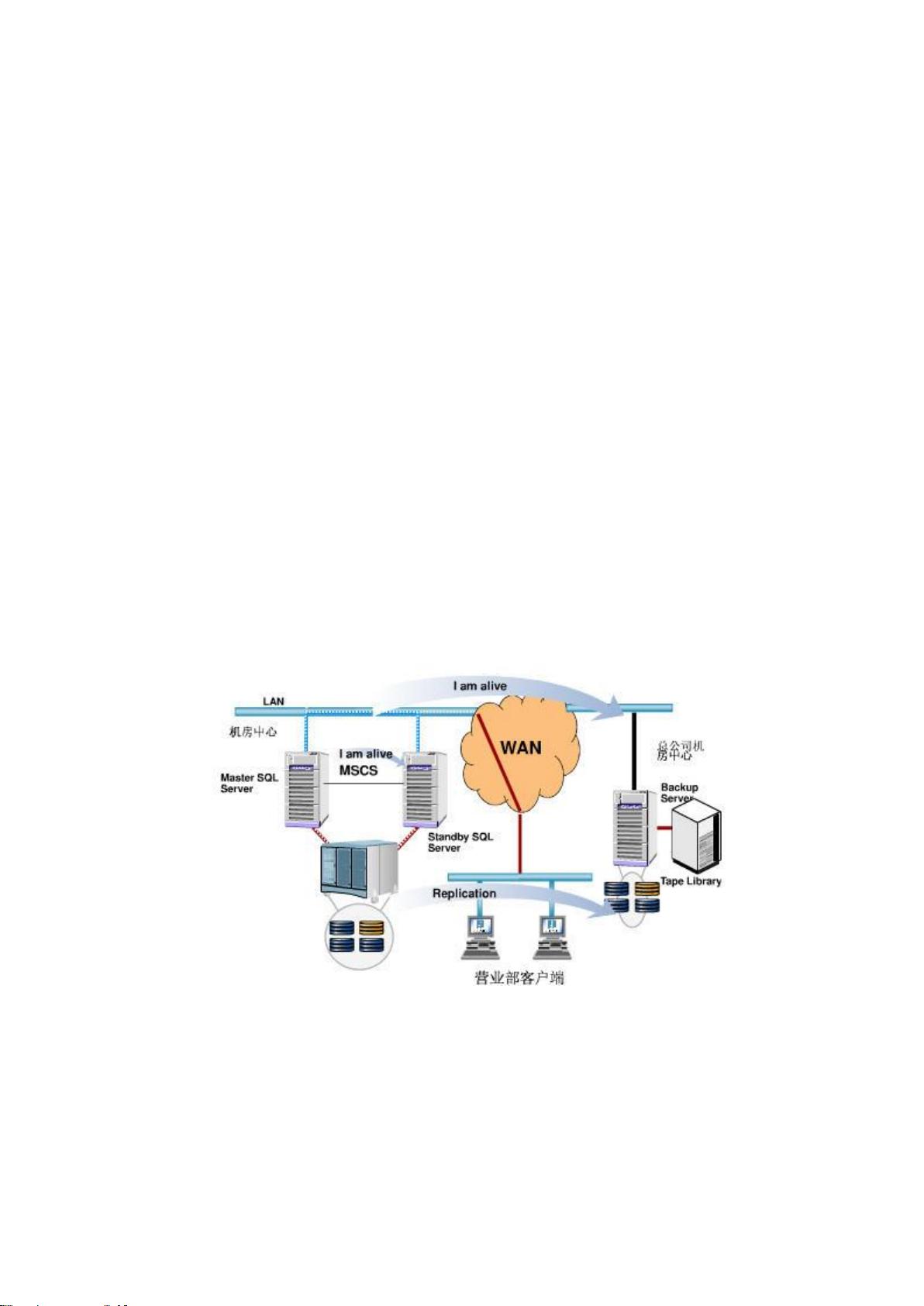
剩余166页未读,继续阅读

潇洒哥cyx
- 粉丝: 8
- 资源: 2
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- RTL8188FU-Linux-v5.7.4.2-36687.20200602.tar(20765).gz
- c++校园超市商品信息管理系统课程设计说明书(含源代码) (2).pdf
- 建筑供配电系统相关课件.pptx
- 企业管理规章制度及管理模式.doc
- vb打开摄像头.doc
- 云计算-可信计算中认证协议改进方案.pdf
- [详细完整版]单片机编程4.ppt
- c语言常用算法.pdf
- c++经典程序代码大全.pdf
- 单片机数字时钟资料.doc
- 11项目管理前沿1.0.pptx
- 基于ssm的“魅力”繁峙宣传网站的设计与实现论文.doc
- 智慧交通综合解决方案.pptx
- 建筑防潮设计-PowerPointPresentati.pptx
- SPC统计过程控制程序.pptx
- SPC统计方法基础知识.pptx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0