互联网信息抽取:从非结构化到结构化数据
版权申诉
"这是一份关于互联网数据挖掘的课程资料,特别是关于自然语言处理的第11章——互联网信息抽取。课程旨在为学生提供从入门到深入的自然语言处理技术学习,涵盖了信息检索、自然语言处理基础、数据挖掘等多个方面。在本章中,主要讨论了如何从非结构化、半结构化和结构化的数据中提取有价值的信息,特别是从HTML网页中抽取数据的挑战和方法,如利用DOM(文档对象模型)解析和操作网页内容。"
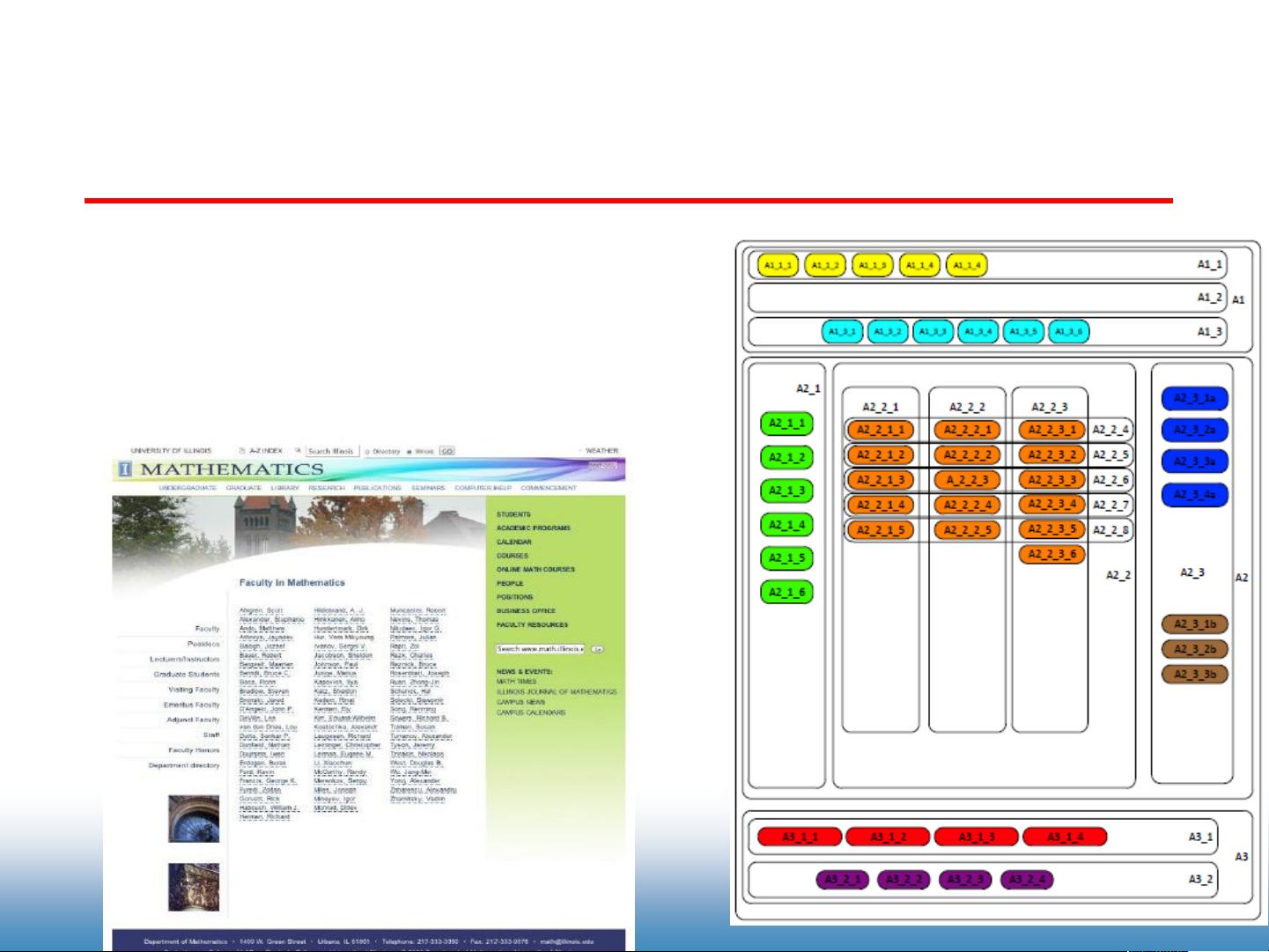
在互联网数据挖掘领域,信息抽取(Information Extraction,简称IE)是一项关键的技术,它涉及到对非结构化数据(如纯文本、句子和查询字符串)和半结构化数据(如HTML文档和查询日志)的处理。非结构化数据由于其自由形式的特性,使得信息提取变得复杂。而半结构化数据虽然比非结构化数据更具有一定的格式,但如HTML网页,它们并不遵循严格的模式,主要目的是为了浏览器呈现,而非数据存储或检索。
HTML网页数据的模式不明确,使得直接从中提取所需信息成为一项挑战。然而,HTML可以通过文档对象模型(DOM)进行解析。DOM是一种表示HTML或XML文档的标准树形结构,使得程序可以动态地访问和更新文档内容、结构和样式。每个HTML元素都被表示为一个节点,可以按照层级关系进行访问。例如,可以使用JavaScript等脚本语言通过DOM API来获取或修改特定ID的元素,如改变元素的背景颜色或者获取其子节点。
在处理HTML网页时,通过DOM可以定位到特定的数据元素,比如链接、图像、表格等,进而提取所需信息。这对于构建搜索引擎、爬虫、新闻聚合器等应用至关重要。同时,对于那些没有模式的HTML数据,可能需要使用正则表达式、模板匹配或机器学习方法来识别和抽取特定的数据模式。
此外,课程还可能涉及如何处理结构化数据,如数据库中的数据,这些数据通常遵循严格定义的模式,便于信息抽取和分析。在实际应用中,信息抽取技术经常与自然语言处理相结合,用于智能问答系统、情感分析、观点挖掘等方面,以实现自动化信息处理和决策支持。
这个课程章节将引导学生深入了解信息抽取的原理和技术,通过实例和练习帮助他们掌握从互联网数据中提取有用信息的技能,为他们在数据科学和人工智能领域的进一步研究和实践打下坚实基础。

文档对象模型(DOM)
10
通过DOM可以访问HTML
通过脚本语言可以操作DOM
<div id="item1" class="content"
onMouseOver="changeColor('item1', '#fdd');"
onMouseOut="changeColor('item1', '#cff');">
<a href="http://www.unc.edu/">UNC</a><br>
</div>
<br>
<script>
function changeColor(item, color)
{
document.getElementById(item).style.backgroundColor
=color;
//alert(document.getElementById(item).childNodes[1]);
document.getElementById(item).childNodes[1].style.backgroundColor
=color;
}
</script>
剩余57页未读,继续阅读

passionSnail
- 粉丝: 458
- 资源: 7503
 我的内容管理
展开
我的内容管理
展开







最新资源
- 俄罗斯RTSD数据集实现交通标志实时检测
- 易语言开发的文件批量改名工具使用Ex_Dui美化界面
- 爱心援助动态网页教程:前端开发实战指南
- 复旦微电子数字电路课件4章同步时序电路详解
- Dylan Manley的编程投资组合登录页面设计介绍
- Python实现H3K4me3与H3K27ac表观遗传标记域长度分析
- 易语言开源播放器项目:简易界面与强大的音频支持
- 介绍rxtx2.2全系统环境下的Java版本使用
- ZStack-CC2530 半开源协议栈使用与安装指南
- 易语言实现的八斗平台与淘宝评论采集软件开发
- Christiano响应式网站项目设计与技术特点
- QT图形框架中QGraphicRectItem的插入与缩放技术
- 组合逻辑电路深入解析与习题教程
- Vue+ECharts实现中国地图3D展示与交互功能
- MiSTer_MAME_SCRIPTS:自动下载MAME与HBMAME脚本指南
- 前端技术精髓:构建响应式盆栽展示网站
