HBase深度解析:应用场景、数据模型与架构揭秘
49 浏览量
更新于2024-08-28
收藏 1011KB PDF 举报
"本文详细介绍了Hbase的应用场景、原理和架构,包括其作为分布式列存储系统在Hadoop生态中的角色,以及与HDFS的区别。Hbase适用于海量结构化数据的存储,采用列存储方式以提高查询效率,并具有强大的数据模型和物理模型设计。"
HBase是一个高度可扩展的分布式数据库,它基于Google的BigTable模型,专为处理大规模数据而设计。在Hadoop生态系统中,HBase坐落在HDFS(Hadoop Distributed File System)之上,利用HDFS的分布式特性保证数据的容错性和扩展性。然而,与HDFS主要服务于批处理任务不同,HBase提供了实时读写能力,支持数据的随机查找和更新,特别适合在线服务和大数据分析。
HBase的数据模型是列式存储的,与传统的行式存储数据库(如MySQL)相反。这种设计使得HBase在处理大规模稀疏数据时表现出色,因为列存储允许只检索需要的列,减少不必要的I/O操作。每个数据项由一个唯一的行键(Rowkey)标识,行键决定了数据在表中的物理位置。数据被组织为多个列族(ColumnFamily),每个列族下可以有任意数量的列(Column)。每个单元格(Cell)包含一个特定时间戳的数据版本,这支持了数据的历史追踪和多版本并发控制。
HBase的操作主要围绕行键进行,提供了Put、Get、Scan等基础操作。Put用于插入数据,Get根据行键获取数据,Scan则用于扫描指定范围内的行。多行操作如Scan和MultiPut也提供了批量处理的能力。虽然HBase不支持内置的JOIN操作,但可以通过MapReduce等工具来实现复杂的多表关联查询。
在物理层面上,HBase的表被划分为多个Region,Region是HBase的基本存储和处理单元。Region会随着数据的增长而分裂,当一个Region达到预设大小时,会被分成两个新的Region,以确保数据分布的均匀性和负载均衡。RegionServer负责管理这些Region,提供数据服务,并在需要时进行Region迁移。
HBase还采用了Zookeeper进行集群协调和故障恢复,确保系统的高可用性。此外,通过Compaction机制,HBase能够定期合并存储文件,优化磁盘空间利用率并提高读取效率。
HBase是应对大数据挑战的理想选择,尤其在实时分析、日志处理、物联网数据存储等领域有广泛应用。它的设计理念和架构特性使其在处理大规模、稀疏、结构化数据时表现出高效、灵活和可扩展的优势。
Hbase的应用场景、原理及架构分析的应用场景、原理及架构分析
HBase概述
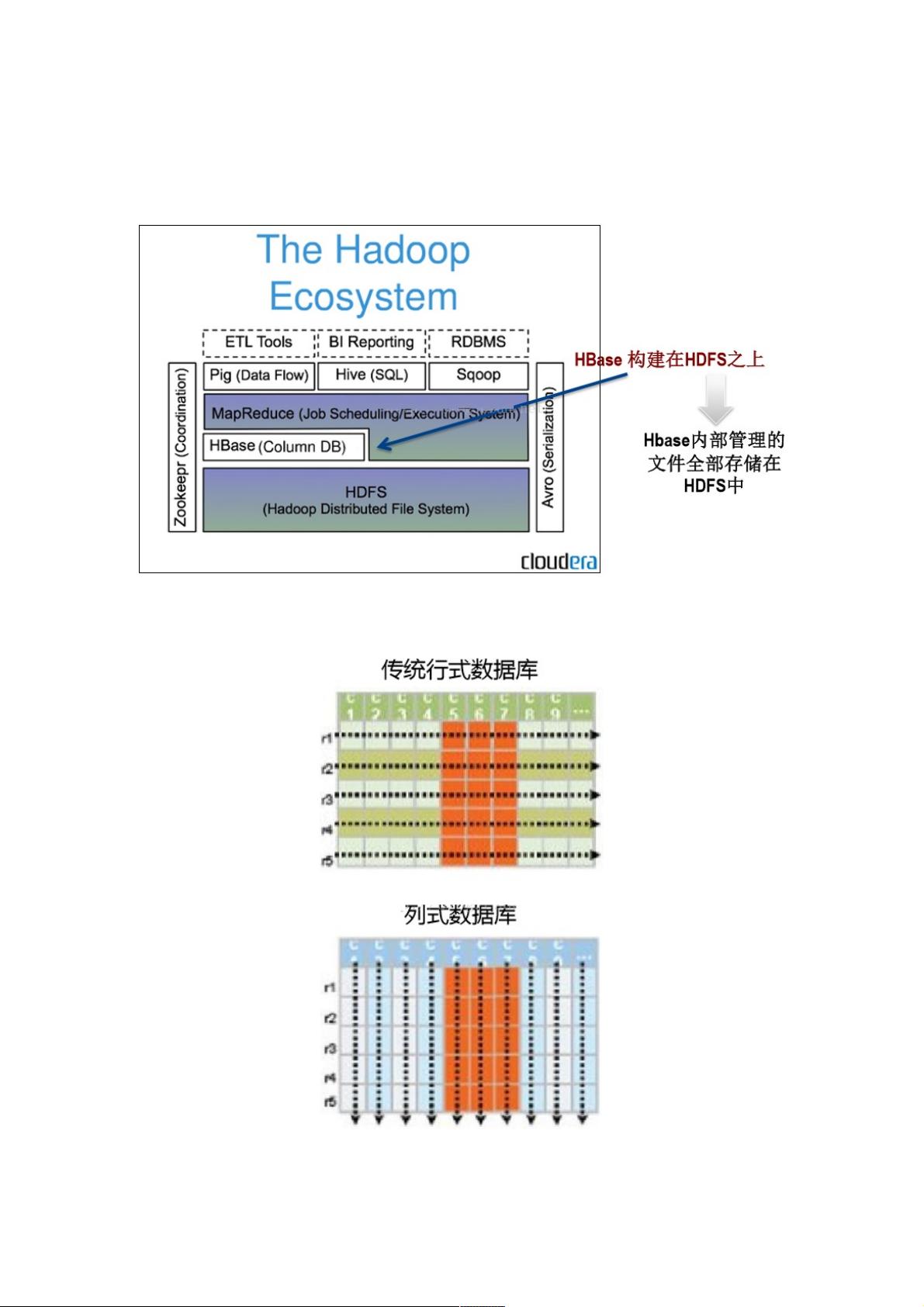
HBase是一个构建在HDFS上的分布式列存储系统。HBase是Apache Hadoop生态系统中的重要 一员,主要用于海量结构化
数据存储。从逻辑上讲,HBase将数据按照表、行和列进行存储。
如图所示,Hbase构建在HDFS之上,Hadoop之下。其内部管理的文件全部存储在HDFS中。与HDFS相比两者都具有良好的
容错性和扩展性,都可以 扩展到成百上千个节点。但HDFS适合批处理场景,不支持数据随机查找,不适合增量数据处理且不
支持数据更新。
Hbase是列存储的非关系数据库。传统数据库Mysql等,数据是按行存储的。其没有索引的查询将消耗大量I/O 并且建立索引
和物化视图需要花费大量时间和资源。因此,为了满足面向查询的需求,数据库必须被大量膨胀才能满 足性能要求。
Hbase数据是按列存储-每一列单独存放。列存储的优点是数据即是索引。访问查询涉及的列-大量降低系统I/O 。并且每一列
由一个线索来处理,可以实现查询的并发处理。基于Hbase数据类型一致性,可以实现数据库的高效压缩。
HBase数据模型
下载后可阅读完整内容,剩余5页未读,立即下载
233 浏览量
2022-11-21 上传
点击了解资源详情
144 浏览量
305 浏览量
444 浏览量
点击了解资源详情

weixin_38704786
- 粉丝: 13
 我的内容管理
展开
我的内容管理
展开







最新资源
- AR0134摄像头寄存器配置及初始化流程
- PHP4Mono:Mono平台上PHP代码的编译解决方案
- 利用虚拟处理器提升Matlab 6.5集群计算性能
- KSAS学术博客:跨部门平台与多作者支持
- renovate-config:掌握JavaScript装修配置的工具
- 文件时间同步工具:如何保持文件时间不变
- Penelope:跨平台Web浏览器工具集成开源项目
- Beolabtoolbox V65:Matlab开发的并行执行工具包
- 个性化游戏光标:Сustom game cursors-crx插件功能介绍
- 编程分配:C语言自学成才年度回顾
- TQRichTextView:iPhone富文本视图控件源代码解析
- STM32数控稳压电源开发全资料分享
- depvault:跨语言的开源依赖管理器发布
- Superpowered Web Audio JS/WASM SDK:低延迟交互式音效开发
- 掌握1000句常用英语口语,提升国际化沟通能力
- 蓝点通用管理系统V20补丁安装与更新指南
