

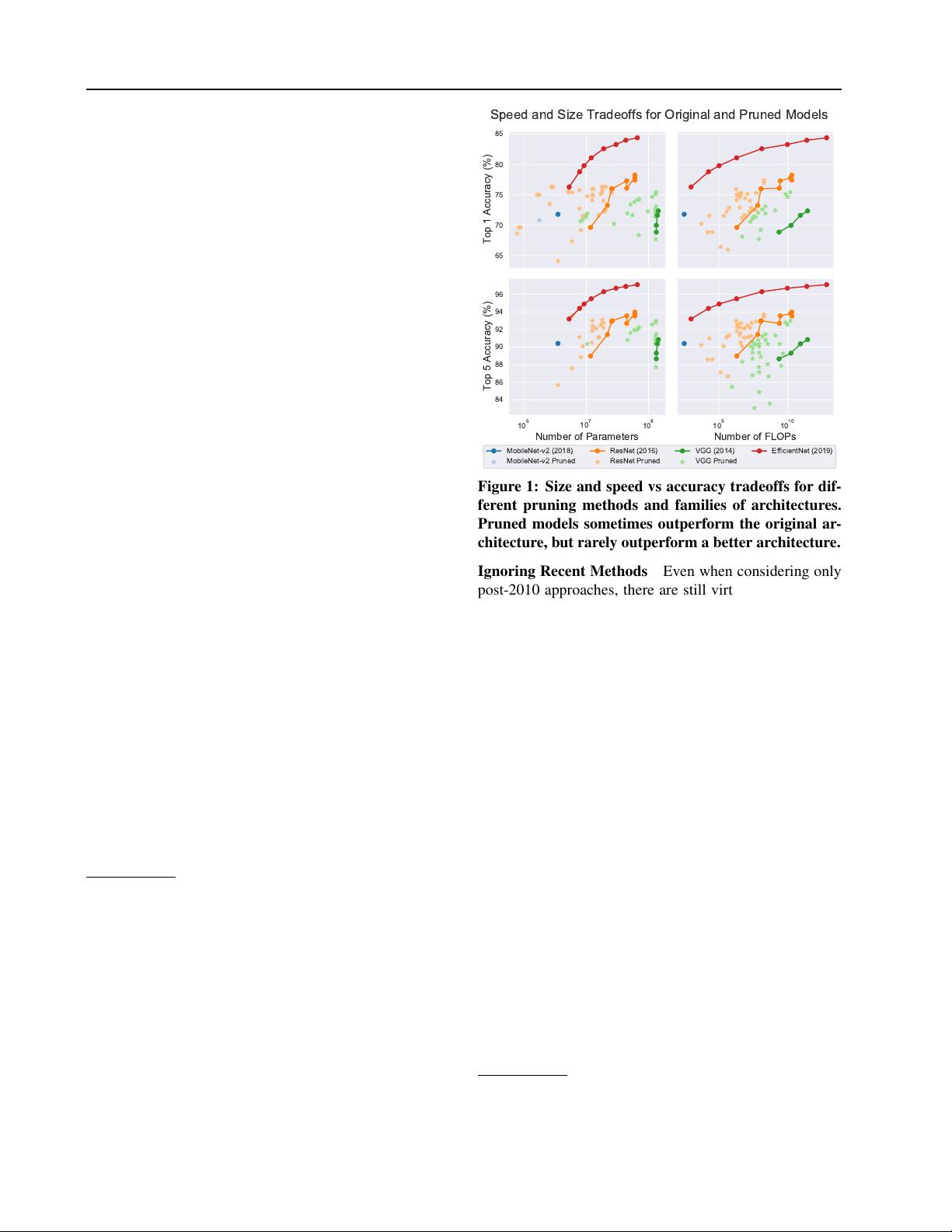
WHAT IS THE STATE OF NEURAL NETWORK PRUNING?
Davis Blalock
* 1
Jose Javier Gonzalez Ortiz
* 1
Jonathan Frankle
1
John Guttag
1
ABSTRACT
Neural network pruning—the task of reducing the size of a network by removing parameters—has been the
subject of a great deal of work in recent years. We provide a meta-analysis of the literature, including an overview
of approaches to pruning and consistent findings in the literature. After aggregating results across 81 papers
and pruning hundreds of models in controlled conditions, our clearest finding is that the community suffers
from a lack of standardized benchmarks and metrics. This deficiency is substantial enough that it is hard to
compare pruning techniques to one another or determine how much progress the field has made over the past
three decades. To address this situation, we identify issues with current practices, suggest concrete remedies, and
introduce ShrinkBench, an open-source framework to facilitate standardized evaluations of pruning methods. We
use ShrinkBench to compare various pruning techniques and show that its comprehensive evaluation can prevent
common pitfalls when comparing pruning methods.
1 INTRODUCTION
Much of the progress in machine learning in the past
decade has been a result of deep neural networks. Many
of these networks, particularly those that perform the best
(Huang et al., 2018), require enormous amounts of compu-
tation and memory. These requirements not only increase
infrastructure costs, but also make deployment of net-
works to resource-constrained environments such as mo-
bile phones or smart devices challenging (Han et al., 2015;
Sze et al., 2017; Yang et al., 2017).
One popular approach for reducing these resource require-
ments at test time is neural network pruning, which entails
systematically removing parameters from an existing net-
work. Typically, the initial network is large and accurate,
and the goal is to produce a smaller network with simi-
lar accuracy. Pruning has been used since the late 1980s
(Janowsky, 1989; Mozer & Smolensky, 1989a;b; Karnin,
1990), but has seen an explosion of interest in the past
decade thanks to the rise of deep neural networks.
For this study, we surveyed 81 recent papers on pruning
in the hopes of extracting practical lessons for the broader
community. For example: which technique achieves the
best accuracy/efficiency tradeoff? Are there strategies that
work best on specific architectures or datasets? Which
high-level design choices are most effective?
There are indeed several consistent results: pruning param-
eters based on their magnitudes substantially compresses
*
Equal contribution
1
MIT CSAIL, Cambridge, MA, USA.
Correspondence to: Davis Blalock <dblalock@mit.edu>.
Proceedings of the 3
rd
MLSys Conference, Austin, TX, USA,
2020. Copyright 2020 by the author(s).
networks without reducing accuracy, and many pruning
methods outperform random pruning. However, our cen-
tral finding is that the state of the literature is such that our
motivating questions are impossible to answer. Few papers
compare to one another, and methodologies are so inconsis-
tent between papers that we could not make these compar-
isons ourselves. For example, a quarter of papers compare
to no other pruning method, half of papers compare to at
most one other method, and dozens of methods have never
been compared to by any subsequent work. In addition,
no dataset/network pair appears in even a third of papers,
evaluation metrics differ widely, and hyperparameters and
other counfounders vary or are left unspecified.
Most of these issues stem from the absence of standard
datasets, networks, metrics, and experimental practices. To
help enable more comparable pruning research, we identify
specific impediments and pitfalls, recommend best prac-
tices, and introduce ShrinkBench, a library for standard-
ized evaluation of pruning. ShrinkBench makes it easy to
adhere to the best practices we identify, largely by provid-
ing a standardized collection of pruning primitives, models,
datasets, and training routines.
Our contributions are as follows:
1. A meta-analysis of the neural network pruning litera-
ture based on comprehensively aggregating reported re-
sults from 81 papers.
2. A catalog of problems in the literature and best prac-
tices for avoiding them. These insights derive from an-
alyzing existing work and pruning hundreds of models.
3. ShrinkBench, an open-source library for evaluating
neural network pruning methods available at
https://github.com/jjgo/shrinkbench.
arXiv:2003.03033v1 [cs.LG] 6 Mar 2020


剩余17页未读,继续阅读

syp_net
- 粉丝: 158
- 资源: 1196
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- zigbee-cluster-library-specification
- JSBSim Reference Manual
- c++校园超市商品信息管理系统课程设计说明书(含源代码) (2).pdf
- 建筑供配电系统相关课件.pptx
- 企业管理规章制度及管理模式.doc
- vb打开摄像头.doc
- 云计算-可信计算中认证协议改进方案.pdf
- [详细完整版]单片机编程4.ppt
- c语言常用算法.pdf
- c++经典程序代码大全.pdf
- 单片机数字时钟资料.doc
- 11项目管理前沿1.0.pptx
- 基于ssm的“魅力”繁峙宣传网站的设计与实现论文.doc
- 智慧交通综合解决方案.pptx
- 建筑防潮设计-PowerPointPresentati.pptx
- SPC统计过程控制程序.pptx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0