使用贝叶斯网络分析Kaggle泰坦尼克号数据:生存预测
需积分: 46 68 浏览量
更新于2023-05-15
3
收藏 398KB PDF 举报
"这篇文档详细介绍了如何利用贝叶斯网络分析Kaggle上的泰坦尼克号数据集,目的是预测乘客的存活情况。"
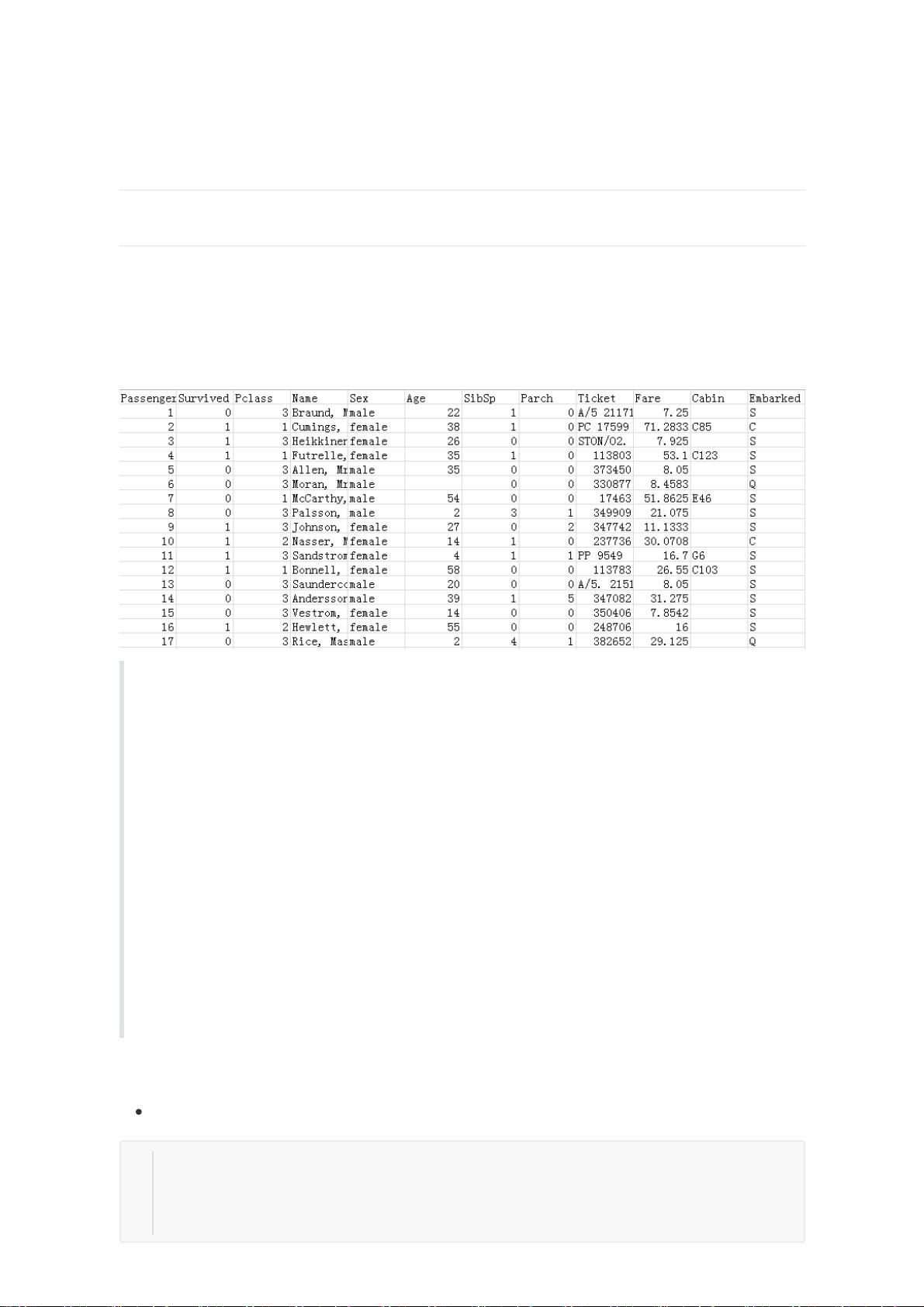
在Kaggle的泰坦尼克号挑战中,参赛者需要通过分析训练集中的乘客数据,构建一个模型来预测测试集中乘客的生存概率。数据集包含了11个特征,包括`PassengerId`(乘客ID)、`Pclass`(客舱等级)、`Name`(乘客姓名)、`Sex`(性别)、`Age`(年龄)、`SibSp`(兄弟姐妹/配偶数量)、`Parch`(父母/子女数量)、`Ticket`(船票编号)、`Fare`(船票价格)、`Cabin`(客舱号)和`Embarked`(登船港口)。特征工程是这个过程中的关键步骤,可以通过对已有特征的分析和理解,创造新的有用特征。
在数据处理阶段,首先需要对训练集和测试集进行合并,以便统一处理缺失值。`Embarked`和`Fare`的缺失值相对较少,可以考虑填充;而`Age`和`Cabin`的缺失值较多,它们可能对结果有较大影响。对于`Age`的缺失值,文档建议根据`Name`字段提取`Title`(头衔),然后使用`Title`的中位数来估计年龄。例如,将未婚女性(`Miss`)中年龄小于等于14岁的视为小女孩(`Girl`)。同样,`Cabin`的缺失值可能需要更复杂的处理,因为它涉及到客舱位置,可能关系到乘客的社会地位和逃生机会。
接着,数据可视化部分展示了性别对生存概率的影响。通过对`Sex`特征的分析,可以看出男性和女性的存活率可能存在显著差异。此外,通过创建新的特征,如`Title`,可以更深入地了解乘客的社会地位,这可能影响他们的生存机会。例如,`Title`的分布可能揭示乘客的年龄和性别,进而影响他们在灾难中的行为和生存概率。
这个文档提供了使用贝叶斯网络分析泰坦尼克号数据集的初步步骤,包括数据预处理、缺失值处理、特征工程以及初步的数据探索。通过这些步骤,参赛者可以建立一个更准确的预测模型,以判断乘客在泰坦尼克号沉船事件中的存活状态。在实际应用中,还可以考虑其他机器学习算法,如决策树、随机森林或支持向量机,并通过交叉验证和超参数调优来提高模型的预测性能。
贝叶斯网络分析kaggle泰坦尼克号
(Titanic)
一、数据处理
1.原始数据分析
主要是让参赛选手根据训练集中的乘客数据和存活情况进行建模,进而使用模型预测测试集中的乘客是
否会存活。乘客特征总共有11个,以下列出。当然也可以根据情况自己生成新特征,这就是特征工程
(feature engineering)要做的事情了。
PassengerId => 乘客ID
Pclass => 客舱等级(1/2/3等舱位)
Name => 乘客姓名
Sex => 性别
Age => 年龄
SibSp => 兄弟姐妹数/配偶数
Parch => 父母数/子女数
Ticket => 船票编号
Fare => 船票价格
Cabin => 客舱号
Embarked => 登船港口
2.数据清洗
数据集合并
#合并训练集train和测试集test
train=pd.read_csv('./train.csv')
test=pd.read_csv('./test.csv')
full=pd.concat([train,test],ignore_index=True)
1
2
3
4
下载后可阅读完整内容,剩余5页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2019-05-08 上传
2021-04-29 上传
点击了解资源详情
2021-12-26 上传
125 浏览量
2021-02-22 上传

咸鱼综合症
- 粉丝: 7
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- CoreOS部署神器:configdrive_creator脚本详解
- 探索CCR-Studio.github.io: JavaScript的前沿实践平台
- RapidMatter:Web企业架构设计即服务应用平台
- 电影数据整合:ETL过程与数据库加载实现
- R语言文本分析工作坊资源库详细介绍
- QML小程序实现风车旋转动画教程
- Magento小部件字段验证扩展功能实现
- Flutter入门项目:my_stock应用程序开发指南
- React项目引导:快速构建、测试与部署
- 利用物联网智能技术提升设备安全
- 软件工程师校招笔试题-编程面试大学完整学习计划
- Node.js跨平台JavaScript运行时环境介绍
- 使用护照js和Google Outh的身份验证器教程
- PHP基础教程:掌握PHP编程语言
- Wheel:Vim/Neovim高效缓冲区管理与导航插件
- 在英特尔NUC5i5RYK上安装并优化Kodi运行环境
