《数据科学概念与实践》第二版:快速掌握RapidMiner应用
需积分: 11 51 浏览量
更新于2023-05-19
1
收藏 48.73MB PDF 举报
《数据科学:概念与实践(第二版)》是由Vijay Kotu和Bala Deshpande共同编著的一本深入浅出的数据科学入门书籍,它属于世界著名出版商麦格劳-希尔(Morgan Kaufmann)的印记,隶属于Elsevier集团。该书位于美国马萨诸塞州剑桥市汉普郡街50号5楼,版权归属Elsevier,2019年首次发行,所有权利受到保护。
本书旨在通过一个易于理解的概念框架帮助读者掌握数据科学的基础知识,并通过RapidMiner平台进行即时实践。作者强调了在快速发展的数据科学领域,知识和最佳实践不断演变,随着新的研究发现和技术进步,研究方法、专业实践以及医疗治疗可能需要适时更新。因此,读者在学习过程中不仅要理解核心概念,还要保持对最新动态的关注。
书中涵盖了数据科学的核心概念,包括但不限于数据预处理、统计学、机器学习算法、数据可视化、模型评估和部署等关键环节。读者将学习如何收集、清洗、转换和分析数据,以及如何构建和优化预测模型来解决实际问题。此外,书中还会介绍如何使用RapidMiner这款工具,它是一个强大的数据挖掘和机器学习软件,为初学者提供了直观易用的界面来实践理论知识。
通过阅读《数据科学:概念与实践(第二版)》,读者不仅能建立扎实的数据科学基础,还能了解到如何在实际项目中灵活运用所学知识,以适应不断变化的数据科学环境。版权政策方面,未经许可,任何形式的复制或传播都必须得到出版社书面授权,获取更多信息可通过Elsevier官网的权限服务链接。
这是一本既理论结合实践,又与时俱进的数据科学教材,是任何想要踏入数据科学领域或进一步提升技能的专业人士的理想选择。

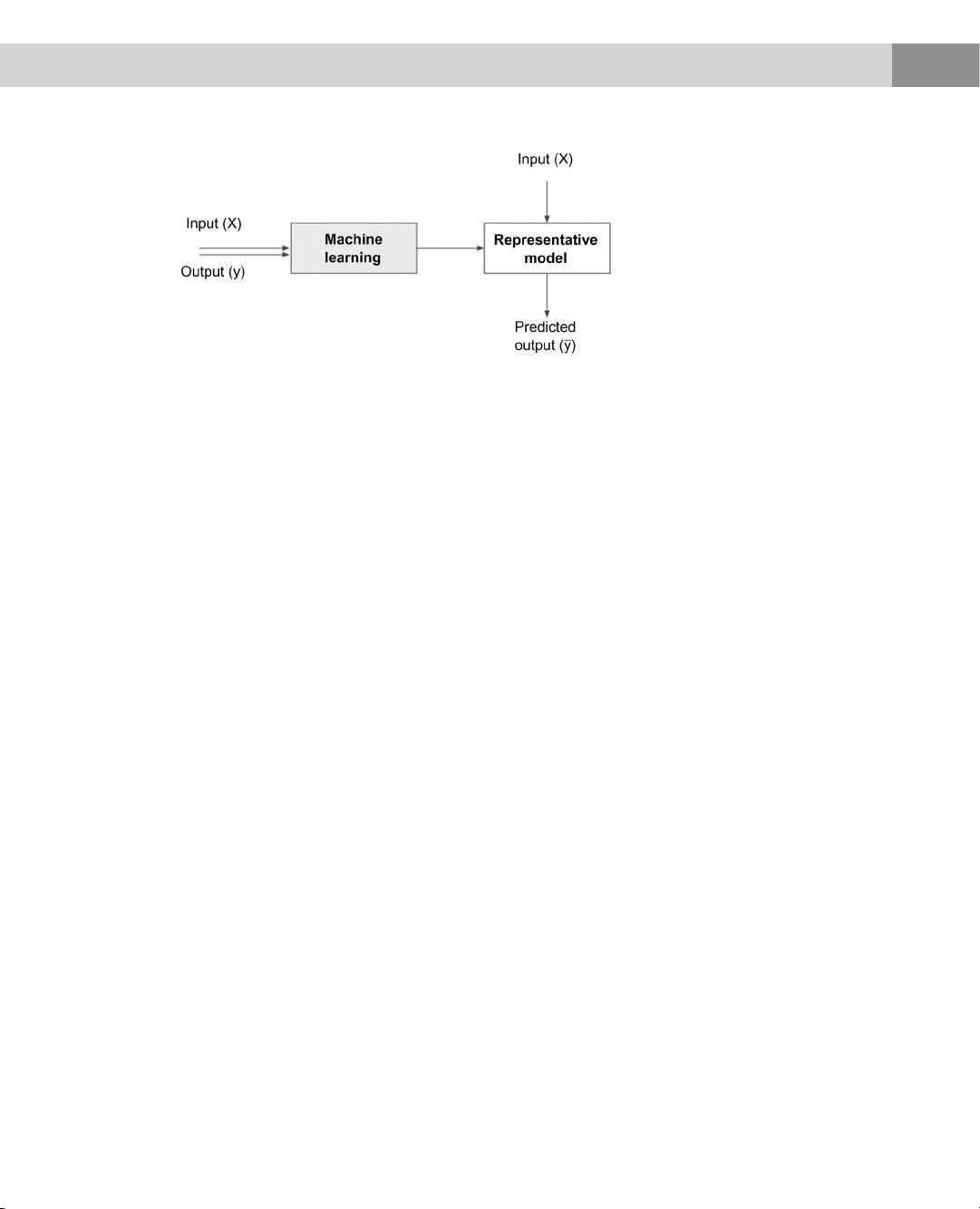
also called “learners”, take both the known input and output (training data)
to figure out a model for the program which converts input to output. For
example, many organizations like social media platforms, review sites, or for-
ums are required to moderate posts and remove abusive content. How can
machines be taught to automate the removal of abusive content? The
machines need to be shown exampl es of both abusive and non-abusive posts
with a clear indication of which one is abusive. The learners will generalize a
pattern based on certain words or sequences of words in order to conclude
whether the overall post is abusive or not. The model can take the form of a
set of “if-then” rules. Once the data science rules or model is developed,
machines can start categorizing the disposition of any new posts.
Data science is the business application of machine learning, artificial intelli-
gence, and other quantitative fields like statistics, visualization, and mathe-
matics. It is an interdisciplinary field that extracts value from data. In the
context of how data science is used today, it relies heavily on machine learn-
ing and is sometimes called data mining. Example s of data science user cases
are: recommendation engines that can recommend movies for a particular
user, a fraud alert model that detects fraudulent credit card transactions, find
customers who will most likely churn next month, or predict revenue for the
next quarter.
1.2 WHAT IS DATA SCIENCE?
Data science starts with data, which can range from a simple array of a few
numeric observations to a complex matrix of millions of observations with
thousands of variables. Data science utilizes certain specialized computational
methods in order to discover meaningful and useful structures within a dataset.
The discipline of data science coexists and is closely associated with a number
of related areas such as database systems, data engineering, visualization, data
analysis, experimentation, and business intelligence (BI). We can further define
data science by investigating some of its key features and motivations.
1.2.1 Extracting Meaningful Patterns
Knowledge discovery in databases is the nontrivial process of identifying
valid, novel, pote ntially useful, and ultimately understandable patterns or
relationships within a dataset in order to make important decisions (
Fayyad,
Piatetsky-shapiro, & Smyth, 1996
). Data science involves inference and itera-
tion of many different hypotheses. One of the key aspects of data science is
the process of generalization of patterns from a dataset. The generalization
should be valid, not just for the dataset used to observe the pattern, but also
for new unseen data. Data science is also a process with defined steps, each
4 CHAPTER 1: Introduction



剩余548页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2024-01-09 上传
2014-06-03 上传
2012-08-03 上传
2018-12-24 上传
2008-10-16 上传

bzquan
- 粉丝: 5
- 资源: 26
 我的内容管理
展开
我的内容管理
展开







最新资源
- CoreOS部署神器:configdrive_creator脚本详解
- 探索CCR-Studio.github.io: JavaScript的前沿实践平台
- RapidMatter:Web企业架构设计即服务应用平台
- 电影数据整合:ETL过程与数据库加载实现
- R语言文本分析工作坊资源库详细介绍
- QML小程序实现风车旋转动画教程
- Magento小部件字段验证扩展功能实现
- Flutter入门项目:my_stock应用程序开发指南
- React项目引导:快速构建、测试与部署
- 利用物联网智能技术提升设备安全
- 软件工程师校招笔试题-编程面试大学完整学习计划
- Node.js跨平台JavaScript运行时环境介绍
- 使用护照js和Google Outh的身份验证器教程
- PHP基础教程:掌握PHP编程语言
- Wheel:Vim/Neovim高效缓冲区管理与导航插件
- 在英特尔NUC5i5RYK上安装并优化Kodi运行环境
