

Workshop track - ICLR 2016
STACKED WHAT-WHERE AUTO-ENCODERS
Junbo Zhao, Michael Mathieu, Ross Goroshin, Yann LeCun
Courant Institute of Mathematical Sciences, New York University
719 Broadway, 12th Floor, New York, NY 10003
{junbo.zhao, mathieu, goroshin, yann}@cs.nyu.edu
ABSTRACT
We present a novel architecture, the “stacked what-where auto-encoders”
(SWWAE), which integrates discriminative and generative pathways and provides
a unified approach to supervised, semi-supervised and unsupervised learning with-
out relying on sampling during training. An instantiation of SWWAE uses a con-
volutional net (Convnet) (LeCun et al. (1998)) to encode the input, and employs a
deconvolutional net (Deconvnet) (Zeiler et al. (2010)) to produce the reconstruc-
tion. The objective function includes reconstruction terms that induce the hidden
states in the Deconvnet to be similar to those of the Convnet. Each pooling layer
produces two sets of variables: the “what” which are fed to the next layer, and
its complementary variable “where” that are fed to the corresponding layer in the
generative decoder.
1 INTRODUCTION
A desirable property of learning models is the ability to be trained in supervised, unsupervised, or
semi-supervised mode with a single architecture and a single learning procedure. Another desirable
property is the ability to exploit the advantageous discriminative and generative models. A popular
approach is to pre-train auto-encoders in a layer-wise fashion, and subsequently fine-tune the entire
stack of encoders (the feed-forward pathway) in a supervised discriminative manner (Erhan et al.
(2010); Gregor & LeCun (2010); Henaff et al. (2011); Kavukcuoglu et al. (2009; 2008; 2010); Ran-
zato et al. (2007); Ranzato & LeCun (2007)). This approach fails to provide a unified mechanism
to unsupervised and supervised learning. Another approach, that provides a unified framework for
all three training modalities, is the deep boltzmann machine (DBM) model (Hinton et al. (2006);
Larochelle & Bengio (2008)). Each layer in a DBM is an restricted boltzmann machine (RBM),
which can be seen as a kind of auto-encoder. Deep RBMs have all the desirable properties, however
they exhibit poor convergence and mixing properties ultimately due to the reliance on sampling dur-
ing training. The main issue with stacked auto-encoders is asymmetry. The mapping implemented
by the feed-forward pathway is often many-to-one, for example mapping images to invariant features
or to class labels. Conversely, the mapping implemented by the feed-back (generative) pathway is
one-to-many, e.g. mapping class labels to image reconstructions. The common way to deal with this
is to view the reconstruction mapping as probabilistic. This is the approach of RBMs and DBMs:
the missing information that is required to generate an image from a category label is dreamed up
by sampling. This sampling approach can lead to interesting visualizations, but is impractical for
training large scale networks because it tends to produce highly noisy gradients.
If the mapping from input to output of the feed-forward pathway were one-to-one, the mappings
in both directions would be well-defined functions and there would be no need for sampling while
reconstructing. But if the internal representations are to possess good invariance properties, it is
desirable that the mapping from one layer to the next be many-to-one. For example, in a Convnet,
invariance is achieved through layers of max-pooling and subsampling.
Our model attempts to satisfy two objectives: (i)-to learn a factorized representation that encodes
invariance and equivariance, (ii)-we want to leverage both labeled and unlabeled data to learn this
representation in a unified framework. The main idea of the approach we propose here is very
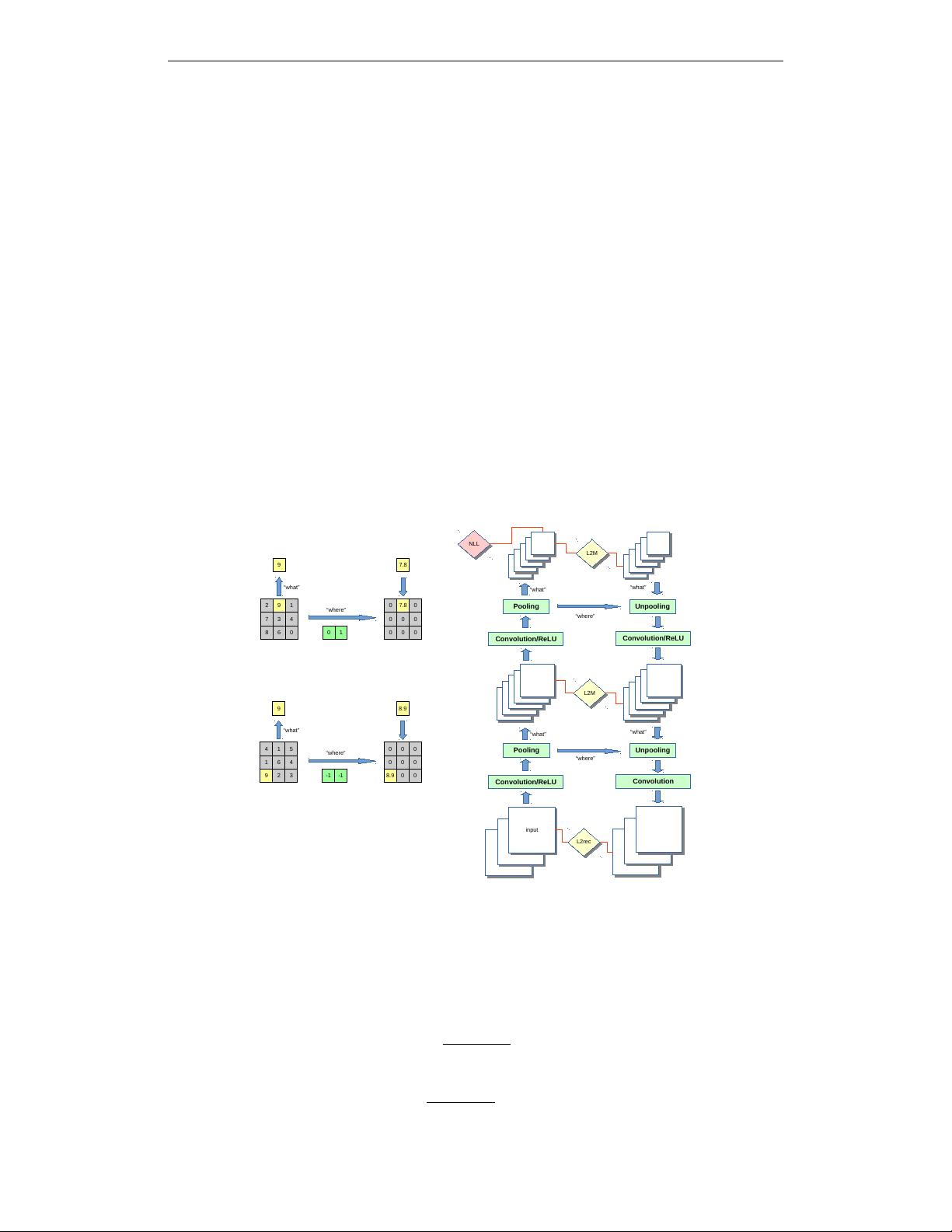
simple: whenever a layer implements a many-to-one mapping, we compute a set of complemen-
tary variables that enable reconstruction. A schematic of our model is depicted in figure 1 (b). In
the max-pooling layers of Convnets, we view the position of the max-pooling “switches” as the
1
arXiv:1506.02351v8 [stat.ML] 14 Feb 2016

剩余11页未读,继续阅读

遂言
- 粉丝: 5
- 资源: 19
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- zigbee-cluster-library-specification
- JSBSim Reference Manual
- c++校园超市商品信息管理系统课程设计说明书(含源代码) (2).pdf
- 建筑供配电系统相关课件.pptx
- 企业管理规章制度及管理模式.doc
- vb打开摄像头.doc
- 云计算-可信计算中认证协议改进方案.pdf
- [详细完整版]单片机编程4.ppt
- c语言常用算法.pdf
- c++经典程序代码大全.pdf
- 单片机数字时钟资料.doc
- 11项目管理前沿1.0.pptx
- 基于ssm的“魅力”繁峙宣传网站的设计与实现论文.doc
- 智慧交通综合解决方案.pptx
- 建筑防潮设计-PowerPointPresentati.pptx
- SPC统计过程控制程序.pptx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论5