
架构的多处理器的主机,而有的实现方式更适合大型的网络连接集群。
本章节描述一个适用于 Google 内部广泛使用的运算环境的实现:用以太网交换机连接、
由普通 PC 机组成的大型集群。在我们的环境里包括:
1.x86 架构、运行 Linux 操作系统、双处理器、2-4GB 内存的机器。
2.普通的网络硬件设备,每个机器的带宽为百兆或者千兆,但是远小于网络的平均带宽的
一半。 (alex 注:这里需要网络专家解释一下了)
3.集群中包含成百上千的机器,因此,机器故障是常态。
4.存储为廉价的内置 IDE 硬盘。一个内部分布式文件系统用来管理存储在这些磁盘上的数
据。文件系统通过数据复制来在不可靠的硬件上保证数据的可靠性和有效性。
5.用户提交工作(job)给调度系统。每个工作(job)都包含一系列的任务(task),调度
系统将这些任务调度到集群中多台可用的机器上。
3.1、执行概括
通过将 Map 调用的输入数据自动分割为 M 个数据片段的集合,Map 调用被分布到多台机
器上执行。输入的数据片段能够在不同的机器上并行处理。使 用分区函数将 Map 调用产
生的中间 key 值分成 R 个不同分区(例如,hash(key) mod R),Reduce 调用也被分布到
多台机器上执行。分区数量(R)和分区函数由用户来指定。
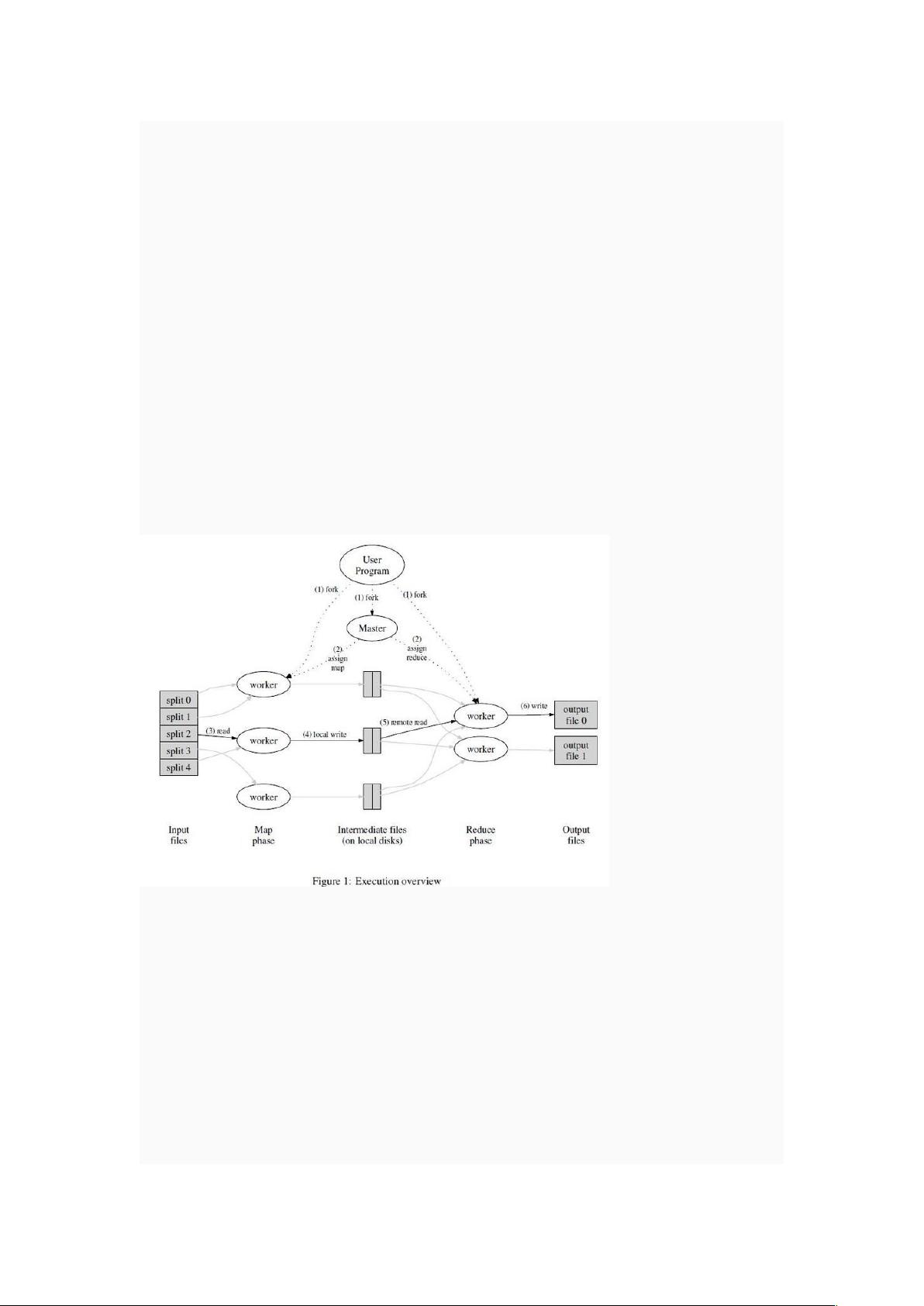
图 1 展示了我们的 MapReduce 实现中操作的全部流程。当用户调用 MapReduce 函数时,
将发生下面的一系列动作(下面的序号和图 1 中的序号一一对应):
1.用户程序首先调用的 MapReduce 库将输入文件分成 M 个数据片度,每个数据片段的大
小一般从 16MB 到 64MB(可以通过可选的参数来控制每个数据片段的大小)。然后用户程
序在机群中创建大量的程序副本。 (alex:copies of the program 还真难翻译)
2.这些程序副本中的有一个特殊的程序–master。副本中其它的程序都是 worker 程序,由
master 分配任务。有 M 个 Map 任务和 R 个 Reduce 任务将被分配,master 将一个 Map 任
务或 Reduce 任务分配给一个空闲的 worker。
3.被分配了 map 任务的 worker 程序读取相关的输入数据片段,从输入的数据片段中解析
出 key/value pair,然后把 key/value pair 传递给用户自定义的 Map 函数,由 Map 函数生
成并输出的中间 key/value pair,并缓存在内存中。
剩余19页未读,继续阅读

MHuiG
- 粉丝: 19
- 资源: 10
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- 构建智慧路灯大数据平台:物联网与节能解决方案
- 智慧开发区建设:探索创新解决方案
- SQL查询实践:员工、商品与销售数据分析
- 2022智慧酒店解决方案:提升服务效率与体验
- 2022年智慧景区信息化整体解决方案:打造数字化旅游新时代
- 2022智慧景区建设:大数据驱动的5A级管理与服务升级
- 2022智慧教育综合方案:迈向2.0时代的创新路径与实施策略
- 2022智慧教育:构建区域教育云,赋能学习新时代
- 2022智慧教室解决方案:融合技术提升教学新时代
- 构建智慧机场:2022年全面信息化解决方案
- 2022智慧机场建设:大数据与物联网引领的生态转型与客户体验升级
- 智慧机场2022安防解决方案:打造高效指挥与全面监控系统
- 2022智慧化工园区一体化管理与运营解决方案
- 2022智慧河长管理系统:科技助力水环境治理
- 伪随机相位编码雷达仿真及FFT增益分析
- 2022智慧管廊建设:工业化与智能化解决方案
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


