

循环神经网络(RNN, Recurrent Neural Networks)介绍
标签: 递归神经网络 RNN 神经网络 LSTMCW-RNN
2015-09-23 13:24 25873 人阅读 评论(13) 收藏 举报
分类:
数据挖掘与机器学习(23)
版权声明:未经许可, 不能转载
目录(?)[+]
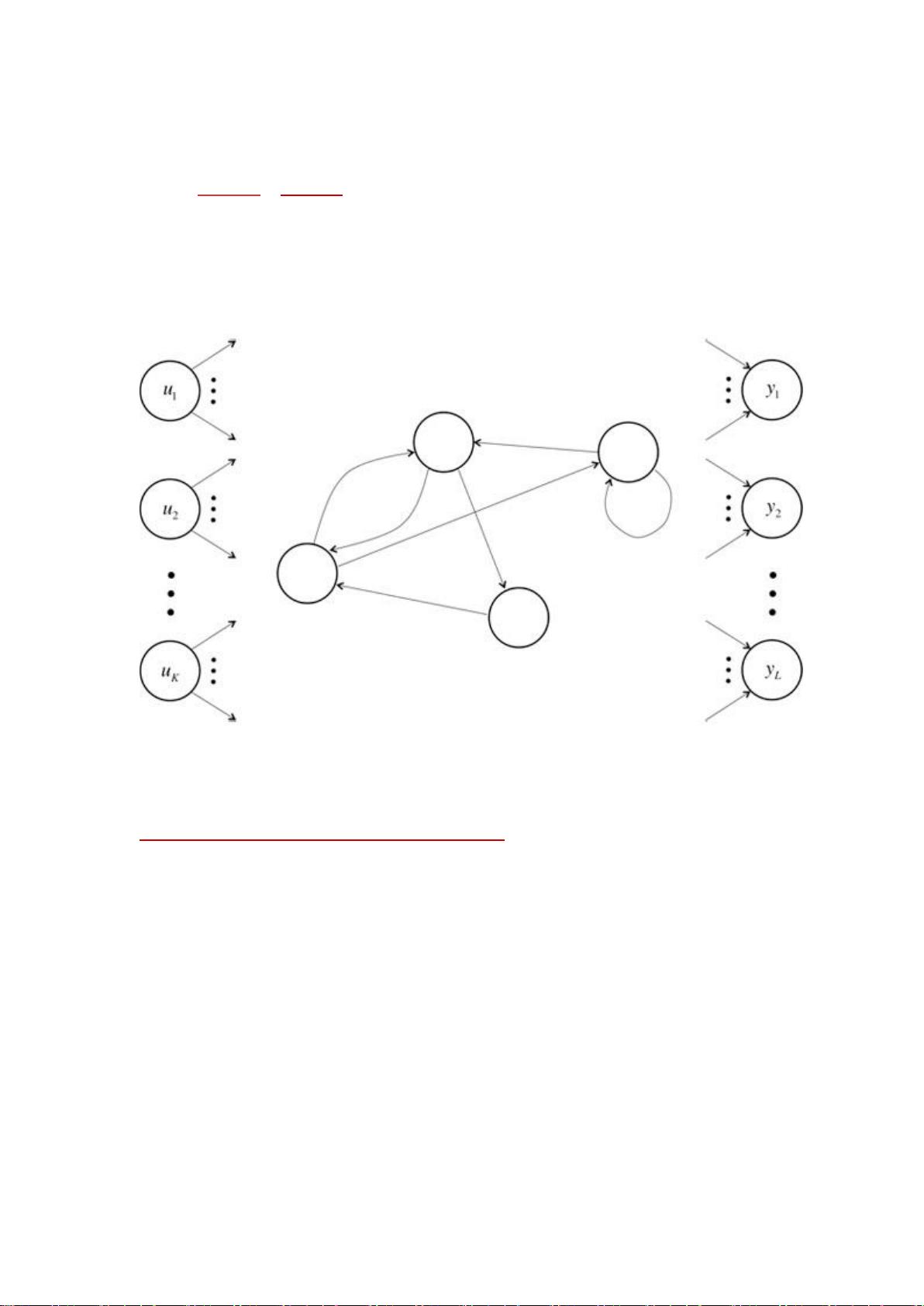
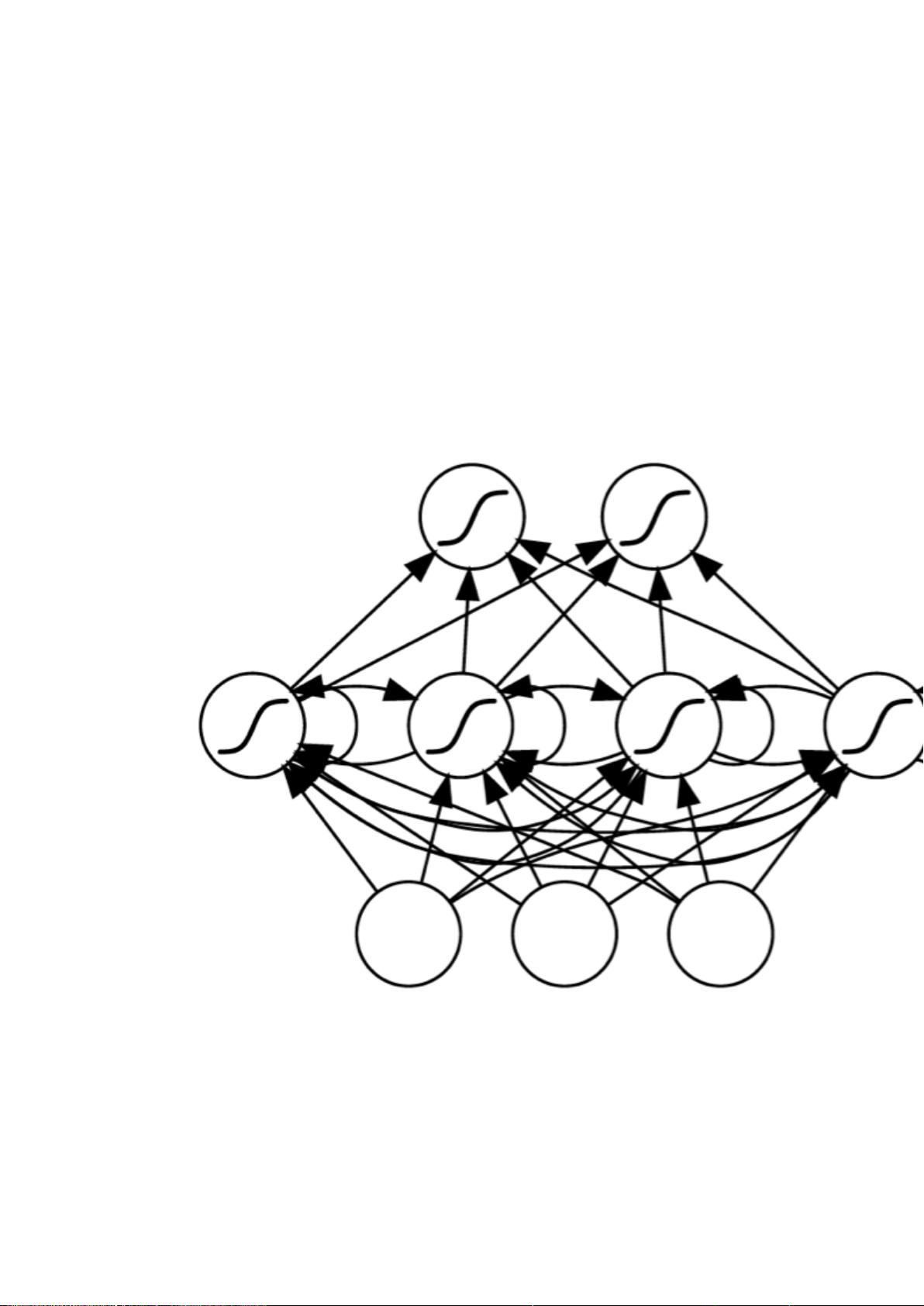
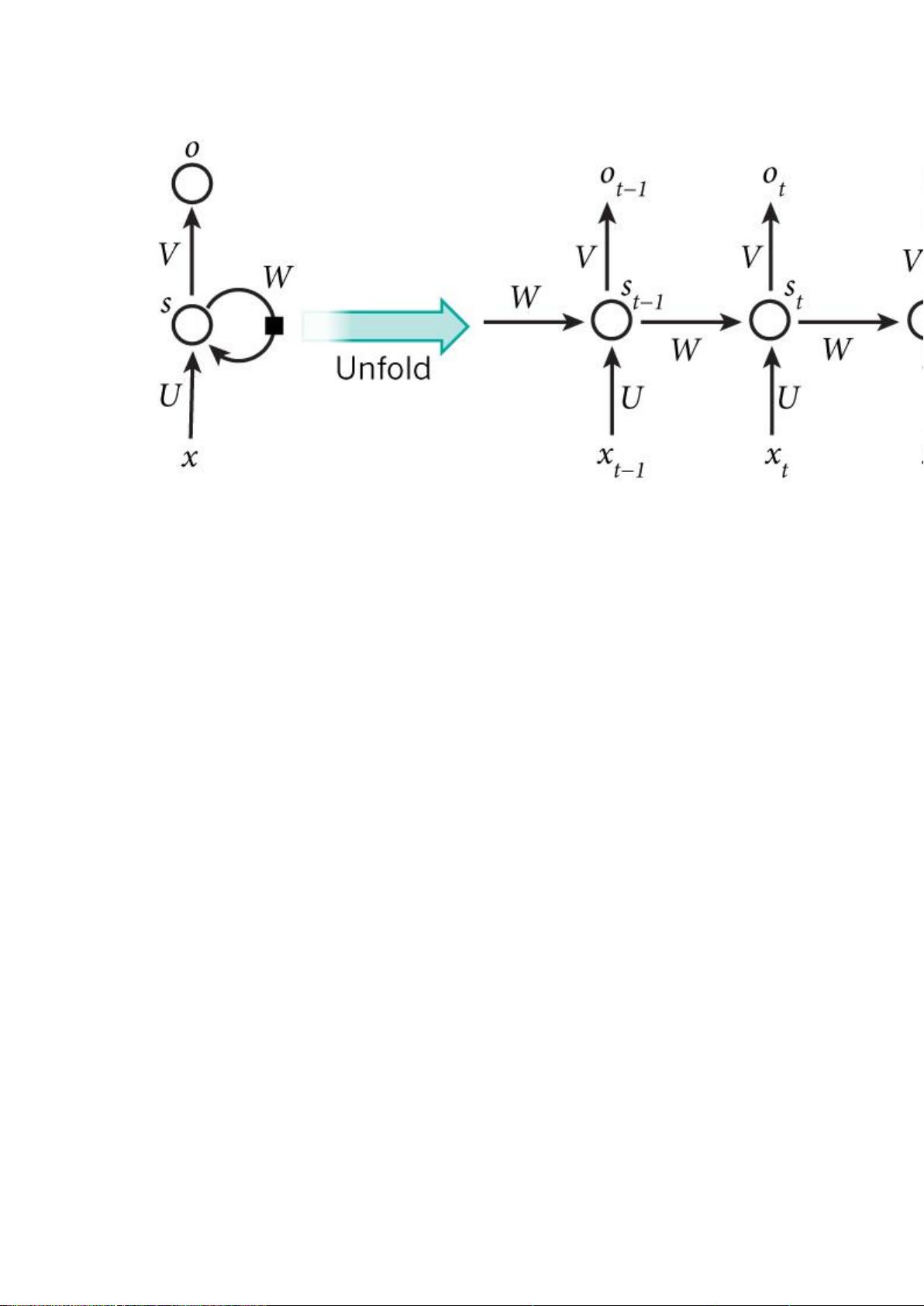
循环神经网络(RNN, Recurrent Neural Networks)
介绍
这篇文章很多内容是参考:
http://www.wildml.com/2015/09/recurrent-neural-networks-tutorial-part-1-introd
uction-to-rnns/,在这篇文章中,加入了一些新的内容与一些自己的理解。
循环神经网络(Recurrent Neural Networks,RNNs)已经在众多自然语言处理
(Natural Language Processing, NLP)中取得了巨大成功以及广泛应用。但是,目前网上
与 RNNs 有关的学习资料很少,因此该系列便是介绍 RNNs 的原理以及如何实现。主要分
成以下几个部分对 RNNs 进行介绍:
1. RNNs 的基本介绍以及一些常见的 RNNs(本文内容);
2. 详细介绍 RNNs 中一些经常使用的训练算法,如 Back Propagation Through
Time(BPTT)、Real-time Recurrent Learning(RTRL)、Extended Kalman Filter(EKF)等学
习算法,以及梯度消失问题(vanishing gradient problem)
3. 详细介绍 Long Short-Term Memory(LSTM,长短时记忆网络);

剩余25页未读,继续阅读


qq_42483047
- 粉丝: 1
- 资源: 3
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- zigbee-cluster-library-specification
- JSBSim Reference Manual
- c++校园超市商品信息管理系统课程设计说明书(含源代码) (2).pdf
- 建筑供配电系统相关课件.pptx
- 企业管理规章制度及管理模式.doc
- vb打开摄像头.doc
- 云计算-可信计算中认证协议改进方案.pdf
- [详细完整版]单片机编程4.ppt
- c语言常用算法.pdf
- c++经典程序代码大全.pdf
- 单片机数字时钟资料.doc
- 11项目管理前沿1.0.pptx
- 基于ssm的“魅力”繁峙宣传网站的设计与实现论文.doc
- 智慧交通综合解决方案.pptx
- 建筑防潮设计-PowerPointPresentati.pptx
- SPC统计过程控制程序.pptx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


